朴素贝叶斯算法是机器学习中基于贝叶斯定理的一种分类方法。该方法实际上是一种生成模型,它通过分析数据中的各种属性之间的关系来确定不同分类的概率。在朴素贝叶斯算法中,我们先计算出每个分类的先验概率,然后通过给定的属性值计算每种分类的后验概率,最终选择拥有最高后验概率的分类作为其预测结果。

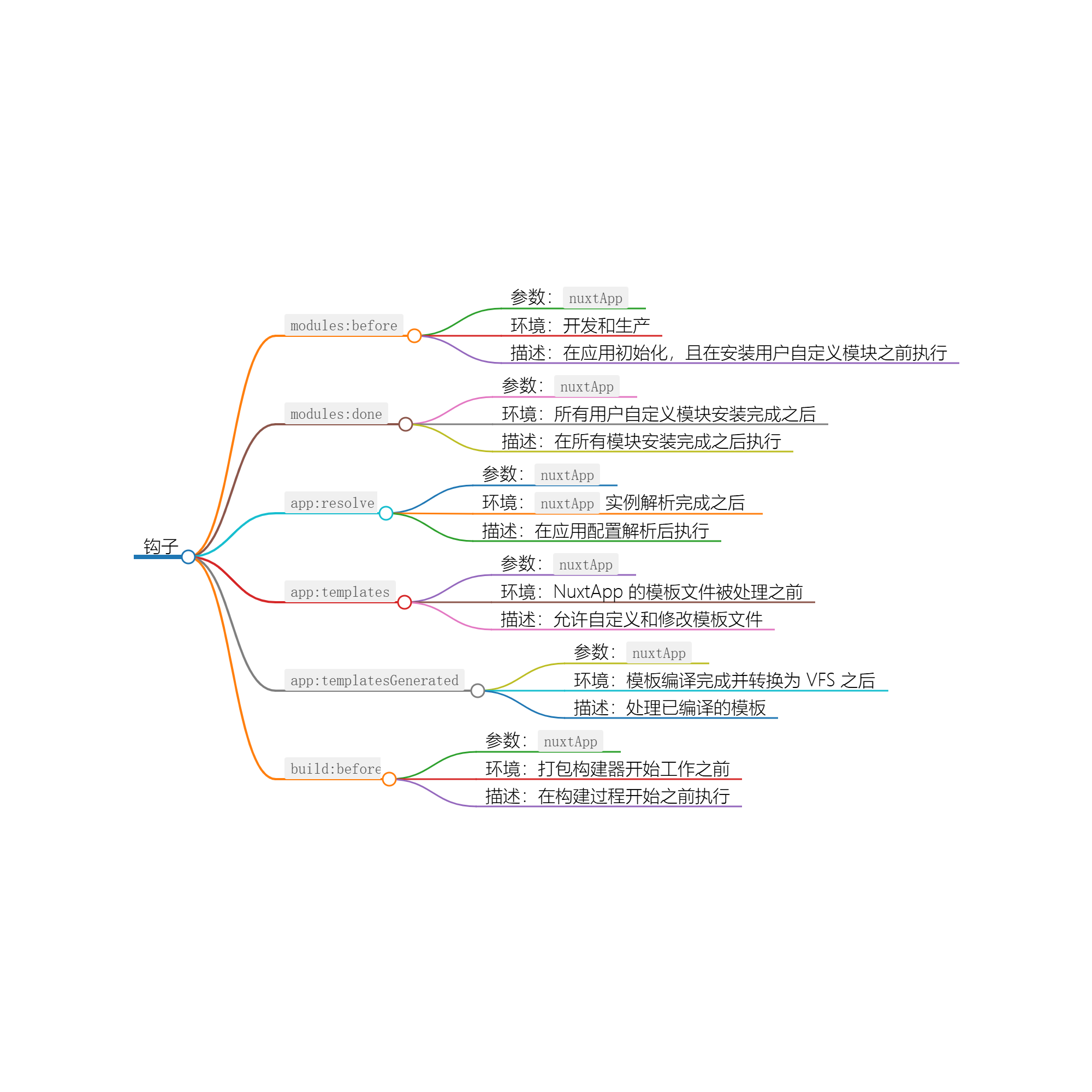
一、邮件的贝叶斯分类思想
假设我们有一个垃圾邮件分类器系统,该系统需要能够自动识别哪些邮件是垃圾邮件。我们可以利用朴素贝叶斯算法来实现这一功能,
首先,我们需要对数据进行预处理,将文本数据转换成类似于向量的形式,创建由垃圾邮件和正常邮件构成的单词库。为了避免出现条件概率为零的情况,也就是某些单词没出现在训练数据中,但会出现在预测数据中,此时可采用平滑的技术,借助单词库对未出现在训练数据中的单词计算条件概率,这样可以方便计算;
其次,我们需要将数据集划分成训练集和测试集。在训练集上,我们可以计算每个特征在不同分类下出现的概率,将针对单词库中的每个单词,分别在正常和垃圾邮件的情况下计算词库中每个单词出现的条件概率,得出不同分类各个单词出现的先验概率,从而就可以生成一个分类模型;
最后,对于新收到的一封新邮件,根据贝叶斯定义分别计算出该邮件为正常邮件和垃圾邮件的概率。如果新邮件中的某些单词没有出现在训练数据的单词库中,计算新邮件为正常或垃圾邮件的概率时将忽略掉这些单词。从而完成数据的训练,做出邮件的分类决策。常常可以在测试集上进行表现测试得到的分类模型,我们可以将测试集中的每个邮件分别输入到模型中,该模型能够根据邮件的各项属性计算概率,从而预测该邮件的分类。
在对邮件进行预处理时,要统计出训练数据中长度最小的文本,并可视化训练数据集的邮件长度的数据分布;然后把邮件的Text内容转换为向量的形式;在进行文本分析时,首先删除停用词即文本含义不起作用的词汇。然后构建出训练数据的\(X\)(文本字符)和\(Y\)(类别)向量。还可借鉴文本挖掘的处理过程,直观的显示出分类的效果,从而调整分类差的类别;有时也可以计算某个单词的Tf-idf值,针对每个句子计算Tf-idf向量,展开情感分析对比分类的精度。总的来说,朴素贝叶斯算法是一种比较简单易用的分类算法,其主要优点是计算速度快、准确率高,并且可以在大数据量下进行有效的处理,基于简单的统计原理,所以其可持续性、简单性和可解释性都非常好。
二、朴素贝叶斯案例
实例:训练数据
| 序号 | 正常邮件文本内容 | 垃圾邮件文本内容 |
|---|---|---|
| 1 | 老师 机器 论文 | 学习 开会 |
| 2 | 产品 开会 老师 | 老师 邮件 |
| 3 | 论文 点击 学习 | 链接 论文 |
| 新邮件内容 | 老师 课程 点击 学习 | 判断新邮件是否垃圾邮件? |
【解析】:词库={老师,机器,论文,产品 ,开会,点击,学习,邮件,链接}
条件概率(做了Add one smoothing处理)(似然概率):
| 正常(邮件) | 垃圾(邮件) |
|---|---|
| P(老师|正常)=(2+1)/(9+9)=3/18 | P(老师|垃圾)=(1+1)/(6+9)=2/15 |
| P(机器|正常)=(1+1)/(9+9)=2/18 | P(机器|垃圾)=(0+1)/(6+9)=1/15 |
| P(论文|正常)=(2+1)/(9+9)=3/18 | P(论文|垃圾)=(1+1)/(6+9)=2/15 |
| P(产品|正常)=(1+1)/(9+9)=2/18 | P(产品|垃圾)=(0+1)/(6+9)=1/15 |
| P(开会|正常)=(2+1)/(9+9)=3/18 | P(开会|垃圾)=(1+1)/(6+9)=2/15 |
| P(点击|正常)=(1+1)/(9+9)=2/18 | P(点击|垃圾)=(0+1)/(6+9)=1/15 |
| P(学习|正常)=(1+1)/(9+9)=2/18 | P(学习|垃圾)=(1+1)/(6+9)=2/15 |
| P(邮件|正常)=(0+1)/(9+9)=1/18 | P(论文|垃圾)=(1+1)/(6+9)=2/15 |
| P(链接|正常)=(0+1)/(9+9)=1/18 | P(链接|垃圾)=(1+1)/(6+9)=2/15 |
| 先验概率:P(正常邮件)=2/3 | 先验概率P(垃圾邮件)=1/3 |
以上求条件概率和先验概率就是训练过程。
后验概率:
=\frac {P(老师|正常)*P(课程|正常) *P(点击|正常) *P(学习|正常) *P(正常)}{P(新邮件}\\
=\frac{(3/18)*(3/18)*(2/18)*(2/3)}{P(新邮件)} \\
P(垃圾|新邮件)=\frac{P(新邮件|垃圾)*P(垃圾)}{P(新邮件)}\\
=\frac{P(老师|垃圾)*P(课程|垃圾) *P(点击|垃圾) *P(学习|垃圾) *P(垃圾)}{P(新邮件)}\\
=\frac{(2/15)*(1/15)*(2/15)*(1/3)}{P(新邮件)}
\]
\(P(正常|新邮件)>P(垃圾|新邮件)\),所以该新邮件是正常邮件,新邮件中不在词库中的关键词“课程”可以忽略;此外\(P(新邮件)\)概率不用详细计算,因为只要比较分子已经能够得到P(正常|新邮件)与P(垃圾|新邮件)大小了。
三、垃圾邮件贝叶斯分类的R程序
数据获取:https://trec.nist.gov/data/spam.html,下载2006垃圾邮件语料库,其中的trec06c文件为本文中使用的数据。
3.1 浏览邮件格式
setwd("~/Desktop/python/email/trec06c")
email_exm <- read.table("data/001/005",fill=TRUE,fileEncoding = "GB18030",sep = "|")
V1
1 Received: from iresearch.cn ([61.152.199.213])
2 \tby spam-gw.ccert.edu.cn (MIMEDefang) with ESMTP id j7BJE30S017437
3 \tfor <chi@ccert.edu.cn>; Sun, 14 Aug 2005 19:45:49 +0800 (CST)
4 Received: from [219.146.1.211]; Sun, 14 Aug 2005 19:59:31 +0800
5 To: chi@ccert.edu.cn
6 From: luo <luo@iresearch.cn>
7 Subject: 8月12日艾瑞视点: 中国IPTV安装用户规模及预测
8 Date: Sun, 14 Aug 2005 11:59:22 GMT
9 Message-Id: <20408064l.87479671l1241856l9287l@iresearch.cn>>
10 Content-Type: text/html; charset=GB2312
11 iWebChoice 媒体排名
.............................................................................
该文件内包含了一份邮件所应该的全部信息,然而我们实际需要的只是其中邮件的正文部分,其他的信息都是基本用不到,是要被清理掉的,这其中主要是一些英文字符、特殊符号以及数字。另外,为了方便后续对中文文本进行分词的处理,我们需要将读入多行的数据合并成一行。粗略阅读该邮件的内容,发现这是一份推销邮件, 显然这是一份垃圾邮件,full文件夹中的index文件中标记了邮件是否为垃圾邮件,我们将index文件导入,查看一下这份数据的结构。
3.2 获取邮件类型
library(dplyr)
email_class_full <- read.table("full/index",fill=TRUE,fileEncoding = "GB18030",col.names = c("type","path"))
str(email_class_full)
prop.table(table(email_class_full$type))
head(email_class_full)
filter(email_class_full,path == "../data/001/005")
index文件包含了所有邮件的文件路径以及邮件的是否为垃圾邮件,一共64620行数据,即64620份邮件,其中非垃圾邮件占比为33.68%,垃圾邮件占比66.32%;另外我们查看了data/001/005的类型,为spam,其的确为垃圾邮件。后续的数据处理中我们将随机抽取其中的10000份邮件,通过index中的文件路径将抽样的文本导入。
3.3 导入邮件文本
library(dplyr)
library(plyr)
library(stringr)
#随机抽取10000条数据
email_class_full <- email_class_full[sample(1:length(email_class_full$type),size=5000),]
#准备for循环中用到的变量
warn_path = c()
emails = c()
num <- length(email_class_full$type)
#逐一读入文件
for(i in 1:num){
#截取邮件的文件路径
path <- str_sub(email_class_full[i,2],4)
#个别邮件包含无法识别的特殊字符无法读入,将其抓取出来
warn <-tryCatch(
{text <- read.table(path,fill=TRUE,fileEncoding = "GB18030",colClasses ="character",sep = "|")},
warning = function(w){"warning"}
)
if(warn == "warning"){ warn_path <- c(warn_path,as.character(email_class_full[i,2]))}
#去除文本中的英文字符、特殊字符
arrange_text <- gsub("[a-zA-Z]","",as.character(warn)) %>%
gsub('[\\(\\.\\\\)-<\n-=@\\>?_]',"",.)
#将处理后的文本保存
emails <- c(emails,arrange_text)
}
normal_emails <- mutate(email_class_full,text = emails,type = factor(type)) %>% filter(.,text !="")
warn_emails <- mutate(email_class_full,text = emails) %>% filter(.,text =="")
随机抽取5000份邮件导入并进行初步的数据清洗后,我们查看一下导入后的数据情况。基本上文本内容均是我们所需要的汉字正文,可以进行下一步的分词提取关键词了。
3.4 处理文本分词
#分词并提取关键词
engine <- worker()
keys = worker("keywords",topn=20)
clean_word <- function(data){
return(paste(unique(vector_keywords(segment(data$text,engine),keys)),collapse=" "))
}
email_words <- ddply(normal_emails,.(type,path),clean_word) %>% rename(.,replace = c("V1" = "words"))
#建立语料库
emails_corpus <- Corpus(VectorSource(email_words$words)) %>% tm_map(.,stripWhitespace)
#创建文档-单词矩阵
emails_dtm <- DocumentTermMatrix(emails_corpus)
3.5 分类垃圾邮件
library(dplyr)
library(plyr)
library(stringr)
library(tm)
library(jiebaR)
library(e1071)
#随机抽取70%的数据作为训练集,剩下的30%作为测试集
train_row <- sample(1:length(email_words$type),size = floor((length(email_words$type) *0.7)))
email_words_train <- email_words[train_row,]
email_words_test <- email_words[-train_row,]
emails_dtm_train <- emails_dtm[train_row,]
emails_dtm_test <- emails_dtm[-train_row,]
emails_corpus_train <- emails_corpus[train_row]
emails_corpus_test <- emails_corpus[-train_row]
#选取词频>=5的词汇
emails_words_dict <- findFreqTerms(emails_dtm_train,5)
emails_corpus_freq_train <- DocumentTermMatrix(emails_corpus_train,list(dictionry = emails_words_dict))
emails_corpus_freq_test <- DocumentTermMatrix(emails_corpus_test,list(dictionry = emails_words_dict))
#将训练集和测试集中的词用0,1分别标记在文本中未出现、出现某一词汇
convert_counts <- function(x){
x <- ifelse(as.numeric(as.character(x))>0,1,0)
x <- factor(x,levels = c(0,1),labels = c("No","Yes"))
return(x)
}
emails_corpus_convert_train <- apply(emails_corpus_freq_train,MARGIN = 2,convert_counts)
emails_corpus_convert_test <- apply(emails_corpus_freq_test,MARGIN = 2,convert_counts)
#利用朴素贝叶斯算法进行分类
emails_naiveBayes <- naiveBayes(emails_corpus_convert_train,email_words_train$type,laplace = 1)
#测试分类的效果
emails_predict <- predict(emails_naiveBayes,emails_corpus_convert_test)
3.6 给出混淆矩阵
table(emails_predict,email_words_test$type)
emails_predict ham spam
ham 509 161
spam 4 754
朴素贝叶斯邮件分类要注意:
需要对邮件文本分词,关键词选取文本中出现的名词、形容词作为输入模型的数据,需要对邮件数据进行训练与积累,所以每一次分类的结果可能有所不同;
有时有些关键词不在训练词库里,这就要训练分类器时加入拉普拉斯平滑,才能得到合理的结果。可在emails_naiveBayes中选择参数laplace = 1。
上面分类是离散地示意过程,在实际处理时集成在一起展开处理就行。此外一定要了解所用邮件数据的数据结构,以便我们在邮件分类时操作模仿。
总结
贝叶斯定理需要大规模的数据(条件概率的获取)计算推理才能体现效果,它在很多计算机应用领域中都大有作为,如自然语言处理、机器学习、推荐系统、图像识别、博弈论,等等。垃圾邮件的问题一直困扰着人们,传统的垃圾邮件分类的方法主要有"关键词法"和"校验码法"等,然而这两种方法效果并不理想。其中,如果使用的是“关键词”法,垃圾邮件中如果这个关键词被拆开则可能识别不了,比如,“中奖”如果被拆成“中 --- 奖”可能会识别不了。直到提出了使用“贝叶斯”的方法才使得垃圾邮件的分类达到一个较好的效果,而且随着邮件数目越来越多,贝叶斯分类的效果会更加好。
例如,收集北京地区两家精神专科医院(北京安定医院、北京回龙观医院)、8家综合医院(北京中医药大学第三附属医院、北京中医药大学东方医院、北京大学第一医院、北京中医医院、中国中医科学院望京医院、中国中医科学院广安门医院、中国中医科学院西苑医院、北京市中西医结合医院)2009年8月1日至2010年7月31日焦虑抑郁门诊的患者,诊断为广泛性焦虑症的患者共705例。根据贝叶斯网络建立证候要素和证候靶位之间的关系模型,总结出9个证候类型为肝郁化火、气郁血瘀、痰热扰心、心胆气虚、肝郁脾虚、心肾不交、心脾两虚、肾精亏虚、肾虚肝旺。