RA-Depth: Resolution Adaptive Self-Supervised Monocular Depth Estimation
注:刚入门depth estimation,这也是以后的主要研究方向,欢迎同一个方向的加入QQ群(602708168)交流。
1. 论文简介
论文题目:RA-Depth: Resolution Adaptive Self-Supervised Monocular Depth Estimation
Paper地址:https://arxiv.org/pdf/2207.11984.pdf
Code地址:https://github.com/hmhemu/RA-Depth
发表刊物:ECCV
发表时间:2022
2. Abstract
本文针对的问题:模型由固定尺寸的数据训练,在不固定尺寸上的测试集上性能有所降低;
本文提出的方法:提出了一个鲁棒自适应地自监督单目深度估计方法(RA-Depth)。

3. Introduction
深度估计的概念,背景,价值与意义介绍;
引出半监督。

![]()
现有self-supervised monocular depth estimation方法的局限性:训练在固定尺寸数据集;
在推理过程中性能下降;
并在图1中对比了训练和测试同一尺寸,Monodepth2和作者提出的方法都不错,而当测试
在其他尺寸时,Monodepth2下降明显。


本文的工作(个人感觉有点工作堆叠的意思,缺乏新颖性):
- 提出了一个数据增强方法,用于生成不同尺度的图像;
- 提出了带有多尺度融合的框架;
- 提出了跨尺度的一致性损失;


4. Related Work
4.1 Supervised Monocular Depth Estimation
输入单幅图像到CNN,然后输出depth map,与GT计算loss。

4.2 Self-Supervised Monocular Depth Estimation
自监督方法将depth estimation看成重建问题,在立体对和单目序列使用光度损失。



5. Method
5.1 Problem Formulation
输入为3幅图像,两幅source view图像,以及一幅target view图像;
根据得到的depth map, 已知相机内参与相机位姿可以将源视角下的图像投影到目标视角。

两个损失函数,公式2,3。

![]()
5.2 Resolution Adaptive Self-Supervised Framework
5.2.1 Overview
方法流程:如图2所示,
第一步:给定输入数据![]() ,然后用数据增强方法扩增数据
,然后用数据增强方法扩增数据
得到三种训练数据![]() ,其中L,M与H表示小,中,大
,其中L,M与H表示小,中,大
三种尺度;然后用提出的Dual HRNet(双HRNet)预测depth maps![]() 。
。
第二步:投影;获得目标视角下图像的深度图![]() ,相机位姿
,相机位姿![]() (
(
所有图像公用统一位姿),三种源视角下的图像,我们可以将源视角的图像投影到
目标视角![]() 。
。
第三步:计算loss。
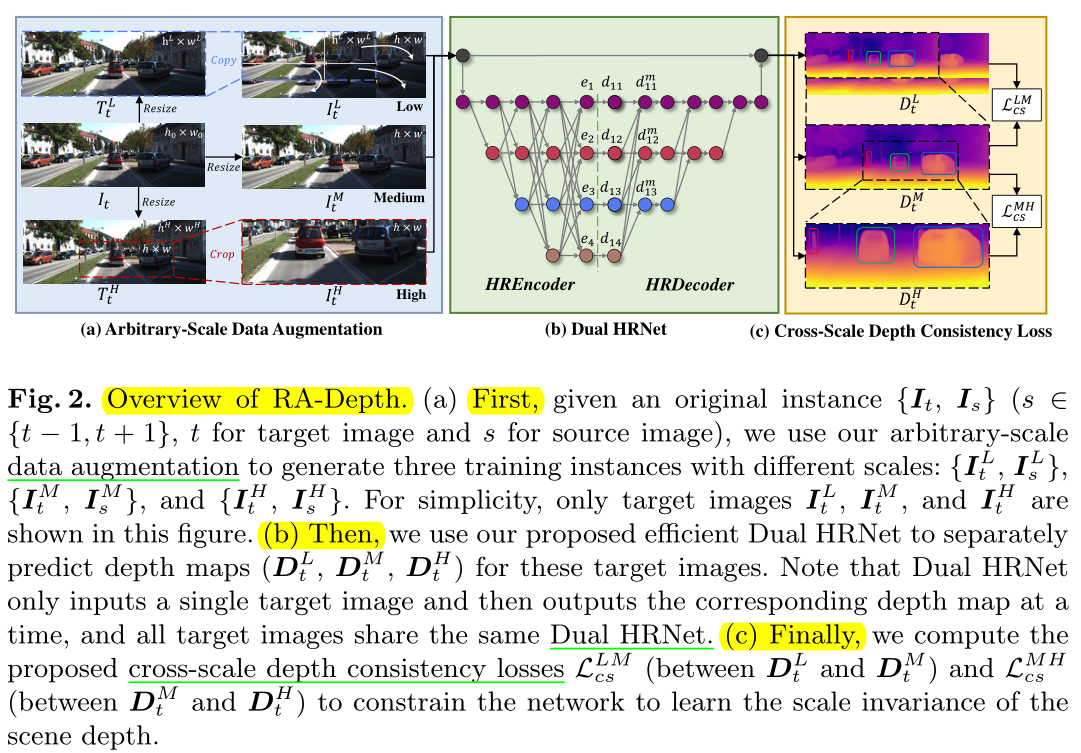

5.2.2 Arbitrary-Scale Data Augmentation
数据增强方式:
给定三种图像,分别resize成不同尺寸,对于M类,resize成(3,192,640),另外两类
根据缩放因子[0.7,0.9]和[1.1,2.0]进行缩放与扩大;
接着,对L类执行复制到M类图像中;M类图像保持不变;H类图像执行裁剪到与M一样大小;
最红得到的L,M,H都是h×w大小;

5.2.3 Dual HRNet for Monocular Depth Estimation
用HRNet作为Network。
细节请阅读原文。


5.2.4 Cross-Scale Depth Consistency Loss
计算夸尺度损失,原理很简单,就是让在三个预测的L,M,H深度图中,先获取相同
位置的深度图,再来做Loss。

6. Experiments
具体细节请参考原文。
7. 总结
本文最大的亮点在于数据集的增强设计以及损失函数的设计。
统一场景下的图像设定成不同size,让网络学习尺度不变鲁棒性。
损失函数的设计还是比较有特色,从L,M,H三类深度图中计算找出相同的部分,然后计算损失函数。
8. 结语
努力去爱周围的每一个人,付出,不一定有收获,但是不付出就一定没有收获! 给街头卖艺的人零钱,不和深夜还在摆摊的小贩讨价还价。愿我的博客对你有所帮助(*^▽^*)(*^▽^*)!
如果客官喜欢小生的园子,记得关注小生哟,小生会持续更新(#^.^#)(#^.^#)。























