Treap 弱平衡的随机性很强的老鼠看不懂的平衡树
Q:为什么叫 Treap?
A:看看二叉搜索树(BST)和堆(Heap),组合起来就是 Treap
其中,二叉搜索树的性质是:
左子节点的值 (val) 比父节点小
右子节点的值 (val) 比父节点大
如果这些节点的值都一样,这棵树就会退化成一颗(?)链。
对, 我知道你在想什么——并查集。
虽然都会被傻老鼠乱搞退化成链,但优化方式大有不同。
优化 - Priority - 玄学抽卡
笨蛋老鼠可能还有疑惑,为什么链是naive的而树是超棒的呢?
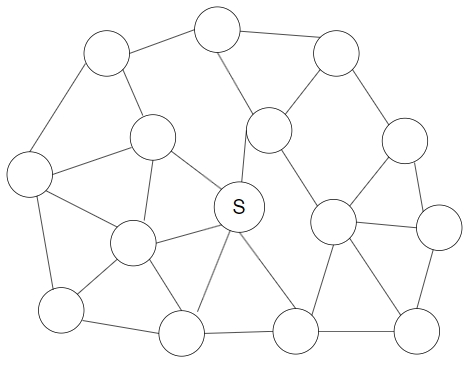
从OIwiki偷两张图来解释:
看,这是一颗正常的树,基本上可以看作满二叉树,一次查询只需要 \(O(\log_2{n})\)的时间复杂度

这是一颗(?)被老鼠乱搞以后形成的链,一次查询的时间复杂度劣化到了 \(O(n)\)

那么,既然屑老鼠已经说了这棵树有堆的性质,所以就要给每一个结点上一个随机的优先级\(Priority\)
让它同时成为一个堆,在双重特征下保持完全二叉树的形状
PS:傻老鼠脑子糊涂了,首先树得满足BST的性质,然后空下来时维护Heap的性质
大功告成,现在该知道节点里面应该放什么了。
node节点(为什么不用类封装?因为老鼠不会)
struct node{
node *child[2];
int val,ranf,cnt,siz;
node(int __val) : val(__val), cnt(1), siz(1){
child[0] = child[1] = nullptr;//左右儿子初始化
ranf = rand();//玄学抽卡
}
node(node *__node){
val = __node->val, ranf = __node->ranf, cnt = __node->cnt, siz = __node->siz;
}
void ud_siz(){
siz = cnt;
if(child[0] != nullptr)siz += child[0]->siz;
if(child[1] != nullptr)siz += child[1]->siz;
}
};
Treap的重要操作 Split & Merge
分裂过程接受两个参数:根指针 \(\textit{cur}\)、关键值 \(\textit{key}\)。结果为将根指针指向的 treap 分裂为两个 treap,第一个 treap 所有结点的值\(\textit{val}\)小于等于 \(\textit{key}\),第二个 treap 所有结点的值大于 \(\textit{key}\)。
该过程首先判断 \(\textit{key}\) 是否小于 \(\textit{cur}\) 的值,若小于,则说明 \(\textit{cur}\) 及其右子树全部大于 \(\textit{key}\),属于第二个 treap。当然,也可能有一部分的左子树的值大于 \(\textit{key}\),所以还需要继续向左子树递归地分裂。对于大于 \(\textit{key}\) 的那部分左子树,我们把它作为 \(\textit{cur}\) 的左子树,这样,整个 \(\textit{cur}\) 上的节点都是大于 \(\textit{key}\) 的。
相应的,如果 \(\textit{key}\) 大于等于 \(\textit{cur}\) 的值,说明 \(\textit{cur}\) 的整个左子树以及其自身都小于 \(\textit{key}\),属于分裂后的第一个 treap。并且,\(\textit{cur}\) 的部分右子树也可能有部分小于 \(\textit{key}\),因此我们需要继续递归地分裂右子树。把小于 \(\textit{key}\) 的那部分作为 \(\textit{cur}\) 的右子树,这样,整个 \(\textit{cur}\) 上的节点都小于 \(\textit{key}\)。
下图展示了 \(\textit{cur}\) 的值小于等于 \(\textit{key}\) 时按值分裂的情况. ——OIWIKI
老鼠才不会解释,因为老鼠没脑子。
Split
pair<node *, node *> split(node *rt,int key){
if(rt == nullptr)return {nullptr, nullptr};
if(rt->val <= key){
auto temp = split(rt->child[1],key);
rt->child[1] = temp.first;
rt->ud_siz();
return {rt,temp.second};
}
else{
auto temp = split(rt->child[0],key);
rt->child[0] = temp.second;
rt->ud_siz();
return {temp.first,rt};
}
}
合并过程接受两个参数:左 treap 的根指针 \(\textit{u}\)、右 treap 的根指针 \(\textit{v}\)。必须满足 \(\textit{u}\) 中所有结点的值小于等于 \(\textit{v}\) 中所有结点的值。一般来说,我们合并的两个 treap 都是原来从一个 treap 中分裂出去的,所以不难满足 \(\textit{u}\) 中所有节点的值都小于 \(\textit{v}\)
在旋转 treap 中,我们借助旋转操作来维护 \(\textit{priority}\) 符合堆的性质,同时旋转时还不能改变树的性质。在无旋 treap 中,我们用合并达到相同的效果。
因为两个 treap 已经有序,所以我们在合并的时候只需要考虑把哪个树「放在上面」,把哪个「放在下面」,也就是是需要判断将哪个一个树作为子树。显然,根据堆的性质,我们需要把 \(\textit{priority}\) 小的放在上面(这里采用小根堆)。
同时,我们还需要满足搜索树的性质,所以若 \(\textit{u}\) 的根结点的 \(\textit{priority}\) 小于 \(\textit{v}\) 的,那么 \(\textit{u}\) 即为新根结点,并且 \(\textit{v}\) 因为值比 \(\textit{u}\) 更大,应与 \(\textit{u}\) 的右子树合并;反之,则 \(\textit{v}\) 作为新根结点,然后因为 u 的值比 \(\textit{v}\) 小,与 v 的左子树合并。——OIWIKI
老鼠懒,自己看。
Merge
node *merge(node *u,node *v){
if(u == nullptr && v == nullptr)return nullptr;
if(u != nullptr && v == nullptr)return u;
if(u == nullptr && v != nullptr)return v;
if(u->ranf < v->ranf){
u->child[1] = merge(u->child[1],v);
u->ud_siz();
return u;
}
else{
v->child[0] = merge(u, v->child[0]);
v->ud_siz();
return v;
}
}
不好用,才不用——⑨老鼠
作为笨蛋老鼠,能看懂这个东西怎么用才奇怪吧,只能分裂和合并的数据结构,鬼才用嘞!
笨蛋老鼠!这个东西可以整很多活的
查询小于等于val的数的个数:考察根节点的值和val,如果val小于根节点,递归进左子树,否则递归进右子树。
插入val:先查询Rank(val),然后按照rank把整个TreapSplit成两个,把val做成一个新节点,Merge到里面。
删除val:先查询Rank(val),然后按照rank把整个TreapSplit成三个,删除需要的点,最后Merge剩下两个。
查询第K个值:把整个TreapSplit成三个,输出需要的值,最后合并起来。
好啊,你的区间呢?
夸下的海口终究会被打qwq。
发现了没,这些个操作全是区间的,想想你的线段树怎么区间修改优化的?
\(LazyTag\)救我狗命对吧!
所以,直接打标记建线段树到处乱搞,怎么在树链剖分上整的活大多数都能整!





![[MAUI程序设计]界面多态与实现](https://img2023.cnblogs.com/blog/644861/202305/644861-20230514174411501-283775291.png)