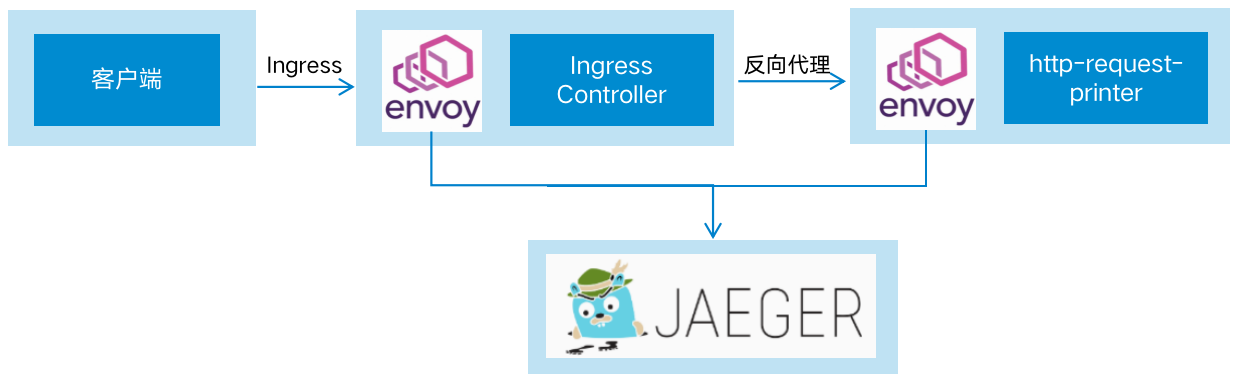
不要通过共享内存来通信,而应通过通信来共享内存。
在“Go编程实战:博客备份”一文中,使用 Go 语言实现了博客备份的串行流程。本文,我们来学习使用 Go channel 的基于通信的并发编程。
并发编程模型
并发是一个很有趣也很有挑战性的话题。 CPU 设计已经朝多核方向发展多时,而并发是充分利用多核优势的编程模型。用《火影忍者》的术语,并发就相当于多重影分身术,可以同时分化出不计其数的鸣人来进行攻击和防御。
不过,并发是有一定难度的。与串行程序按照指令顺序执行不同,并发的指令执行顺序是不确定的,因此更容易出错,出现难以排查和难以解决的 BUG。
目前有两种主要的并发模型:
- 基于共享内存的并发模型。即多个线程可以同时对同一个内存区域进行读写。这种并发模型,必须非常小心地对共享内存进行同步访问,否则,就很可能出现各种非预期的问题。详情可阅:Java并发的若干基本陷阱、原理及解决方案。
- 基于通信的并发模型。多个线程或协程通过 channel 来通信,通过 channel 来协调多个线程或协程的执行顺序。这种并发模型,实际上隐式地依赖了共享内存,但通过限制共享内存的访问而降低了出错概率。channel,实际上就是共享阻塞队列,但这种队列只允许一个写,一个读,或者只能写或只能读。
Go 语言最令人激动的就是将并发内置在语言里,提供了基于 channel 通信的并发编程模型。当然,channel 让并发编程模型变得简单,并不代表并发的难度就降低了。不仔细处理,并发依然是容易出错的。下面给出基于 Go channel 的并发编程示例,读者可以慢慢体会并发编程的“魅力”。
基本尝试
如下代码所示。只是改了 SequentialRun2 和 WriteMarkdown。
- 声明了一个 等待组 sync.WaitGroup wg,可以看作是一个倒数计数器。
- 每拿到一个有效博文链接,就使用 wg.Add(1) 加一个计数; 每当执行完成一个 WriteMarkdown, 就用 wg.Done() 减一个计数(相当于 Add(-1));
- 使用一个 wg.Wait() 阻塞住主流程。
类比下:
- 有十个运动员准备短跑。每个运动员进场就计数一次。
- 发令枪一响,每个运动员都开始短跑。每一个运动员到达终点,就减一个计数。
- 当计数减为零时,比赛结束。
两个问题:
- 为什么 WriteMarkdown 调用需要用 go ? 因为 go 会起一个协程去异步执行任务,这样就使得每个博文的 WriteMarkdown 的执行是并发的。
- 为什么要有 wg.Wait() ?读者可以去掉试试。会发现程序很快就退出了,并且几乎什么都没打印。这是因为 main goroutine 退出时,整个程序就结束了,协程也就无法执行了。
并发就是这么简单! 真的吗?下面将揭示,并发编程里令人烧脑的地方。
func SequentialRun2(fpath string) {
blogRssp, err := ReadXml(fpath)
if err != nil {
os.Exit(2)
}
var wg sync.WaitGroup
mdlinksptr := GetMdLinksPtr(blogRssp)
for i:=0 ; i<len(*mdlinksptr); i++ {
linktrimed := strings.Trim((*mdlinksptr)[i].Link, " ")
if linktrimed == "" {
continue
}
wg.Add(1)
go WriteMarkdown((*mdlinksptr)[i], wg)
}
wg.Wait()
}
func WriteMarkdown(mdlink MarkdownFile, wg sync.WaitGroup) {
defer wg.Done()
// code...
}
并发问题
sync.WaitGroup 适合每个子任务都是相互独立无依赖的。如果任务之间是有依赖的关系,就不能这么处理了。
先来梳理下整个流程:
从博客备份文件中解析出博文链接列表 => 从每个博文链接中下载 HTML 并转换成 Markdown 文件。
假设我每解析出一个博文链接,就将这个博文链接通过 channel 输送给 WriteMarkdown 函数。并且,为了增大并发度,将这个 channel 声明成 buffered channel。
过早退出
先看下面这段代码。使用了一个叫做 mdchannel 的 buffered channel 来传递博文链接列表。每拿到一个博文链接,就通过 mdchannel 输送给 WriteMarkdownFromChannel。这个程序有什么问题?
blog_backup_con_bug_1.go
func sendMdLinks(blogRss *BlogRss, mdchannel chan MarkdownFile) {
blogchannelp := blogRss.Channel
blogitems := (*blogchannelp).Items
for _, item := range blogitems {
mdchannel <- MarkdownFile{Title: item.Title, Link: item.Link}
}
}
func WriteMarkdownFromChannel(mdchannel chan MarkdownFile) {
mdlink := <- mdchannel
fmt.Printf("%v", mdlink)
go WriteMarkdown(mdlink)
}
func ConRun(fpath string) {
blogRssp, err := ReadXml(fpath)
if err != nil {
os.Exit(2)
}
mdchannel := make(chan MarkdownFile, 6)
go sendMdLinks(blogRssp, mdchannel)
WriteMarkdownFromChannel(mdchannel)
}
func main() {
ConRun(GetFiles()[0])
}
你会发现,这个程序只打印了一条博文链接,而且没有生成任何 Markdown 文件。为什么会这样?
- 虽然 blogitems 通过 for-range 进行了遍历,但是 WriteMarkdownFromChannel 只执行了一次,
- 当 mdlink := <- mdchannel 获取到一条博文链接,开始启动一个协程来执行 WriteMarkdown 时,main goroutine 已经无阻塞地退出了,程序就结束了。因此不会生成任何 Markdown 文件。
这是基于 channel 并发编程遇到的第一个问题:main goroutine 过早退出。一切已无法挽回。
为了阻止 main goroutine 过早退出,必须想出一种办法来阻塞 main goroutine。我们想到了 sync.WaitGroup.Wait 方法。于是有了第二个版本。
第二个版本使用了 sync.WaitGroup 。遗憾的是,第二个版本犯了与第一个版本几乎相同的错误,即使使用了 sync.WaitGroup.Wait 也无济于事。
这里有个问题,已经使用了 defer wg.Done() 和 wg.Wait() 阻塞了 main goroutine,按说至少第一个博文链接可以生成 markdown 吧,为什么还是没有生成一个 Markdown 呢?读者可以思考下,后面会有原因说明。或者读者可以对比下网上的教程,看看这里的用法与网上教程有什么差异。
blog_backup_con_bug_2.go
func sendMdLinks(blogRss *BlogRss, mdchannel chan MarkdownFile) {
blogchannelp := blogRss.Channel
blogitems := (*blogchannelp).Items
for _, item := range blogitems {
mdchannel <- MarkdownFile{Title: item.Title, Link: item.Link}
}
}
func WriteMarkdownFromChannel(mdchannel chan MarkdownFile, wg sync.WaitGroup) {
mdlink := <- mdchannel
fmt.Printf("%v", mdlink)
wg.Add(1)
go WriteMarkdown(mdlink, wg)
}
func ConRun(fpath string) {
blogRssp, err := ReadXml(fpath)
if err != nil {
os.Exit(2)
}
var wg sync.WaitGroup
mdchannel := make(chan MarkdownFile, 6)
go sendMdLinks(blogRssp, mdchannel)
WriteMarkdownFromChannel(mdchannel, wg)
wg.Wait()
}
func WriteMarkdown(mdlink MarkdownFile, wg sync.WaitGroup) {
defer wg.Done()
//code...
}
永久阻塞
第三个版本如下。使用了一个 terminatedchannel ,并且仅在 所有博文链接都发送到 mdchannel 之后,才会给 terminatedchannel 发送消息。这样,<- terminatedchannel 就会阻塞 main goroutine,直到所有博文链接都发送完。这个程序有什么问题呢?
blog_backup_con_bug_3.go
func sendMdLinks(blogRss *BlogRss, mdchannel chan MarkdownFile, terminatedchannel chan struct{}) {
blogchannelp := blogRss.Channel
blogitems := (*blogchannelp).Items
for _, item := range blogitems {
mdchannel <- MarkdownFile{Title: item.Title, Link: item.Link}
}
terminatedchannel <- struct{}{}
}
func WriteMarkdownFromChannel(mdchannel chan MarkdownFile, wg sync.WaitGroup) {
mdlink := <- mdchannel
fmt.Printf("%v", mdlink)
wg.Add(1)
go WriteMarkdown(mdlink, wg)
}
func ConRun(fpath string) {
blogRssp, err := ReadXml(fpath)
if err != nil {
os.Exit(2)
}
var wg sync.WaitGroup
terminatedchannel := make(chan struct{})
mdchannel := make(chan MarkdownFile, 6)
go sendMdLinks(blogRssp, mdchannel, terminatedchannel)
WriteMarkdownFromChannel(mdchannel, wg)
<- terminatedchannel
wg.Wait()
}
func WriteMarkdown(mdlink MarkdownFile, wg sync.WaitGroup) {
defer wg.Done()
//code...
}
这个程序会打印第一个博文链接,并生成第一个 Markdown ,然后就卡住了。 为什么会这样?
- 这个版本还是没有意识到, WriteMarkdownFromChannel 只调用了一次,也就是只从 mdchannel 取了一个博文链接,然后就被阻塞在 <- terminatedchannel 这里; 而 sendMdLinks 因为 mdchannel <- MarkdownFile{Title: item.Title, Link: item.Link} 当 mdchannel 缓存满之后,也被阻塞了,无法抵达 terminatedchannel <- struct{}{} 这一步。于是程序永久被阻塞了!
计数错误
再看下面这个程序。
这次终于意识到:mdlink := <- mdchannel 只会被执行一次,并不会一直被阻塞。使用了 for-range 来遍历 mdchannel 里的博文链接,并分别启动一个协程来执行这个博文链接的下载及生成 Markdown 文件。这里涉及一个知识点: 对一个 channel 进行 for-range ,将会一直遍历并取出这个 channel 里的元素并被阻塞。
- 如果 channel 没有被 close ,那么就会阻塞在 for 循环这里无法退出;
- 直到这个 channel 被 close 了,那么迭代完 channel 里的最后一个元素后,for 循环才会退出。
for mdlink := range mdchannel {
fmt.Printf("link: %v\n", mdlink)
go WriteMarkdown(mdlink, wg)
}
那么,这个程序有什么问题呢?
blog_backup_con_bug_4.go
func sendMdLinks(blogRss *BlogRss, mdchannel chan MarkdownFile, wg sync.WaitGroup, terminatedchannel chan struct{}) {
blogchannelp := blogRss.Channel
blogitems := (*blogchannelp).Items
for _, item := range blogitems {
wg.Add(1)
mdchannel <- MarkdownFile{Title: item.Title, Link: item.Link}
}
close(mdchannel)
wg.Wait()
terminatedchannel <- struct{}{}
}
func WriteMarkdownFromChannel(mdchannel chan MarkdownFile, wg sync.WaitGroup) {
for mdlink := range mdchannel {
fmt.Printf("link: %v\n", mdlink)
go WriteMarkdown(mdlink, wg)
}
}
func ConRun(fpath string) {
blogRssp, err := ReadXml(fpath)
if err != nil {
os.Exit(2)
}
var wg sync.WaitGroup
terminatedchannel := make(chan struct{})
mdchannel := make(chan MarkdownFile, 6)
go sendMdLinks(blogRssp, mdchannel, wg, terminatedchannel)
WriteMarkdownFromChannel(mdchannel, wg)
<- terminatedchannel
close(terminatedchannel)
}
func WriteMarkdown(mdlink MarkdownFile, wg sync.WaitGroup) {
defer wg.Done()
//code...
}
这个程序会报:
panic: sync: negative WaitGroup counter
goroutine 368 [running]:
sync.(*WaitGroup).Add(0xc000bdf5c0?, 0x0?)
/usr/local/go/src/sync/waitgroup.go:62 +0xe5
sync.(*WaitGroup).Done(0x0?)
/usr/local/go/src/sync/waitgroup.go:87 +0x25
main.WriteMarkdown({{0xc000022588?, 0x1329e38?}, {0xc0001f4ec0?, 0x122738a?}}, {{}, {{}, {}, 0x0}, 0x0})
/Users/qinshu/workspace/goproj/gostudy/basic/blog_backup_con_bug4.go:96 +0x3e7
created by main.WriteMarkdownFromChannel
/Users/qinshu/workspace/goproj/gostudy/basic/blog_backup_con_bug4.go:114 +0x5d
exit status 2
奇怪了! 按道理,每次都是 wg.Add(1) 之后才 mdchannel <- MarkdownFile{Title: item.Title, Link: item.Link} ; 怎么会出现 wg.Done() 变成负数呢?
想了很久,百思不得其解,就先回家了。
使用指针
回家突然想到,使用 sync.WaitGroup 是传值调用。当调用 WriteMarkdownFromChannel(mdchannel, wg) 是原始的 wg 的值,而不是一个动态变化的值。因此,需要用指针引用才行。
得到最终版程序如下所示。运行基本 OK。不过,不排查还会有并发 Bug 藏在里面。而且 channel, sync.WaitGroup 用得有点混乱,还是需要理一下。
func sendMdLinks(blogRss *BlogRss, mdchannel chan MarkdownFile, wg *sync.WaitGroup, terminatedchannel chan struct{}) {
blogchannelp := blogRss.Channel
blogitems := (*blogchannelp).Items
for _, item := range blogitems {
(*wg).Add(1)
mdchannel <- MarkdownFile{Title: item.Title, Link: item.Link}
}
close(mdchannel)
wg.Wait()
terminatedchannel <- struct{}{}
}
func WriteMarkdownFromChannel(mdchannel chan MarkdownFile, wg *sync.WaitGroup) {
for mdlink := range mdchannel {
fmt.Printf("link: %v\n", mdlink)
go WriteMarkdown(mdlink, wg)
}
}
func ConRun(fpath string) {
blogRssp, err := ReadXml(fpath)
if err != nil {
os.Exit(2)
}
var wg sync.WaitGroup
terminatedchannel := make(chan struct{})
mdchannel := make(chan MarkdownFile, 6)
go sendMdLinks(blogRssp, mdchannel, &wg, terminatedchannel)
WriteMarkdownFromChannel(mdchannel, &wg)
<- terminatedchannel
close(terminatedchannel)
}
func WriteMarkdown(mdlink MarkdownFile, wg *sync.WaitGroup) {
defer (*wg).Done()
//code...
}
注意,上述 WriteMarkdownFromChannel 的写法是有问题的,它的效果类似写成如下调用。原因是:mdlink 作为迭代变量会被所有的 go rountine 共享,而不是每个 goroutine 有一个唯一对应的值。这样,当调用 WriteMarkdown 时,可能会传入同一个值。执行程序,会发现最终生成的文件少了。
func WriteMarkdownFromChannelBuggy(mdchannel chan MarkdownFile, wg *sync.WaitGroup) {
for mdlink := range mdchannel {
//fmt.Printf("link: %v\n", mdlink)
go func() {
WriteMarkdown(mdlink, wg)
}()
}
}
正确的写法是:
func WriteMarkdownFromChannelCorrectly(mdchannel chan MarkdownFile, wg *sync.WaitGroup) {
for mdlink := range mdchannel {
//fmt.Printf("link: %v\n", mdlink)
go func(mdlink MarkdownFile) {
WriteMarkdown(mdlink, wg)
}(mdlink)
}
}
死锁
看看如下程序,会有什么问题?
package main
import (
"fmt"
)
func main() {
ints := make(chan int, 5)
go func() {
for i := 0; i < 10; i++ {
ints <- i
}
}()
for j := range ints {
fmt.Println(j*j)
}
fmt.Println("exit")
}
执行下,报错:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan receive]:
main.main()
/Users/qinshu/workspace/goproj/gostudy/basic/for-range.go:17 +0xca
exit status 2
直接判定程序死锁了!
疑问:为什么有的时候只是程序卡住了无法进行,有时直接报死锁了呢?猜测 go 执行器有一种机制,可以区分出死锁和永久阻塞。死锁,即是程序已经能够判定程序永远无法结束,比如 i 已经发送完,但 channel 已经确定无法被关闭, 那么接收 goroutine 里 j 就会一直阻塞在这里无法退出。 但如果接收 goroutine 无法确定 channel 是否会被 close ,也就无法报死锁了。
增大并发度
使用 time 命令概览下用时(去掉所有日志打印):
➜ basic time go run blog_backup.go ~/Downloads/cnblogs_backup.xml
go run blog_backup.go ~/Downloads/cnblogs_backup.xml 4.86s user 1.77s system 9% cpu 1:12.48 total
➜ basic go build blog_backup.go
➜ basic time ./blog_backup ~/Downloads/cnblogs_backup.xml
./blog_backup ~/Downloads/cnblogs_backup.xml 5.21s user 1.74s system 8% cpu 1:17.44 total
➜ basic time go run blog_backup_con_first.go ~/Downloads/cnblogs_backup.xml
被阻塞住了。
➜ basic time go run blog_backup_con_second.go ~/Downloads/cnblogs_backup.xml
go run blog_backup_con_second.go ~/Downloads/cnblogs_backup.xml 4.94s user 1.60s system 85% cpu 7.631 total
go build blog_backup_con_second.go
➜ basic time ./blog_backup_con_second ~/Downloads/cnblogs_backup.xml
./blog_backup_con_second ~/Downloads/cnblogs_backup.xml 3.62s user 0.97s system 124% cpu 3.686 total
事实上, blog_backup_con_second.go 与 blog_backup_con_first.go 的用时应该相差不大。因为 range blogitems 并不耗时,真正耗时的是 WriteMarkdown 里下载文件内容和写入文件内容两个部分。
现在,我们要将这两个部分并发起来,而不是串行。整个流程应该是:
从博客备份文件中解析出博文链接列表 => 并发从每个博文链接中下载 HTML => 并发将 HTML 文件转换成 Markdown 文件。
只要把原来的 WriteMarkdown 分解为两个方法 。如下代码所示,将写 markdown 文件分离出来,并将 defer (*wg).Done() 移到 WriteMarkDownInner 里。 emm... 协程里再起协程?会有什么问题么?反正就是探索,充分试错是有必要的。确实能运行,不过运行效率与 blog_backup_con_second.go 似乎相差不大。
blog_backup_con_final.go
func WriteMarkdown(mdlink MarkdownFile, wg *sync.WaitGroup) {
urllink := mdlink.Link
filename := mdlink.Title
resp, err := http.Get(urllink)
if err != nil {
fmt.Printf("error get url: %s error: %v", urllink, err)
}
doc, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
fmt.Printf("err: %v", err)
}
postbody := doc.Find("#cnblogs_post_body")
converter := md.NewConverter("", true, nil)
markdown, err := converter.ConvertString(postbody.Text())
if err != nil {
fmt.Printf("err parse html: %v", err)
}
go WriteMarkDownInner(markdown, filename, urllink, wg)
resp.Body.Close()
}
func WriteMarkDownInner(content string, filename string, urllink string, wg *sync.WaitGroup) {
defer (*wg).Done()
ioutil.WriteFile(filename + ".md", []byte(content), 0666)
fmt.Println("link done: " + urllink)
}
测试时间(日志打印去掉):
➜ basic time go run blog_backup_con_final.go ~/Downloads/cnblogs_backup.xml
go run blog_backup_con_final.go ~/Downloads/cnblogs_backup.xml 4.27s user 1.34s system 115% cpu 4.867 total
go build blog_backup_con_final.go
➜ basic time ./blog_backup_con_final ~/Downloads/cnblogs_backup.xml
./blog_backup_con_final ~/Downloads/cnblogs_backup.xml 3.61s user 0.93s system 149% cpu 3.032 total
编译后运行,串行程序耗时 1 分 17 秒,约 77s ,并发程序耗时 5s 左右。提升近 15 倍!
小结
本文探索了 go channel 的基于通信的并发编程。尽管我有一定的并发编程经验,但在使用 go channel 并发编程时,还是步步踩坑。不踩坑,不亲自实践下,无以有获也!
我们感受到:如果并发程序设计不当,可能会导致如下结果:
- 程序过早退出,无法执行所期望的任务;
- 程序永久阻塞,无法进行下去;
- 计数错误,直接报错退出程序;
- 死锁,直接报错退出程序。
那么,要设计正确的并发程序,若干要点如下:
- 首先规划和部署好所有需要并发的 goroutine;
- 要有一个阻塞 main goroutine 的方法,避免 main goroutine 过早退出。
- 在 main goroutine 中避免执行具体事情的阻塞方法,否则 channel 的阻塞特性很可能会导致 main goroutine 永久阻塞。
- 同一 channel 的发送 goroutine 和 接收 goroutine 不能同时都在 main goroutine 里,否则容易永久阻塞 main goroutine。
- 对一个 channel 发送完数据后,切记要 close 这个 channel。
- 独立子任务的并发可以使用 sync.WaitGroup 来解决。sync.WaitGroup 通常是作为全局变量来使用。如果要作为局部变量传入函数,则必须使用指针。
- 有依赖关系的子任务并发可以使用 channel 来协调执行顺序,确保全部执行完成。
- 增大并发的方法是增加耗时方法的并发度。
掌握这些要点,可以高效写出基于 channel 的并发程序,并接近成功。但并不能保证并发程序是没有 bug 的。并发程序是一个有难度的话题,需要多多领悟、多多实践才行。
参考资料
- 《The Go Programming Language》
- Go语言等待组(sync.WaitGroup)
- 深入理解 go sync.Waitgroup
- 由浅入深剖析 go channel
- GO语言的goroutine并发原理和调度机制
- Effective Go: 并发