Java是一种强类型语言,这就意味着在变量编译前确定好变量的数据类型(必须先定义后使用)。
3.1 数据类型
java数据类型分为两大类:引用数据类型和基本数据类型。
-
bit(比特)
比特作为信息技术的最基本存储单位,非常小,简写为小写字母"b"。
计算机是以二进制存储数据的,二进制的一位就是 1 比特,也就是说,比特要么为 0 要么为 1。
-
Byte(字节)
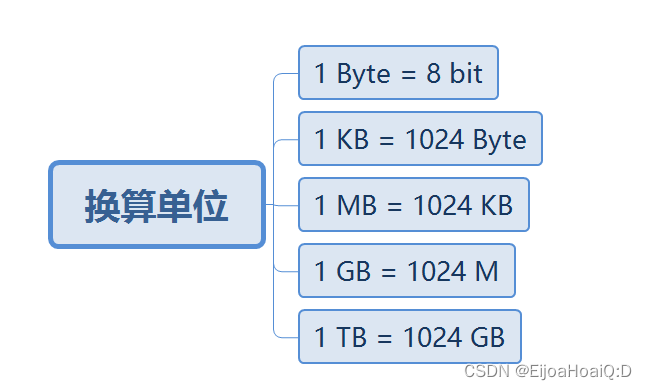
通常来说,一个英文字符是一个字节、一个中文字符是两个字节。字节与比特的换算关系是:
1字节=8比特。在往上的单位是KB,,因为计算机只认识二进制,所以是 2 的 10 次方,也就是 1024个字节。
3.1.1 引用数据类型
引用数据类型包括类、数组、接口。基本数据类型在作为成员变量和静态变量的时候有默认值,引用数据类型也有。
-
类
String 是最典型的引用数据类型,拿 String 类举例:
/** * @author QHJ * @date 2022/8/22 10:41 * @description: 引用数据类型 */ public class DataType { private String a; static String b; public static void main(String[] args) { DataType dataType = new DataType(); System.out.println("a:" + dataType.a); System.out.println("b:" + b); } }查看输出结果:
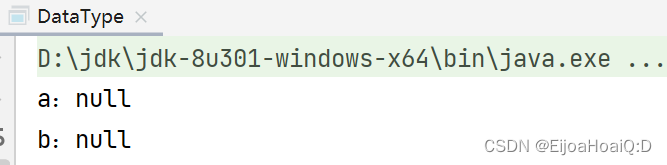
由此可见,引用数据类型的默认值为 null,包括数组和接口。
-
数组
数组虽然没有显式的定义成一个类,但是它的确是一个对象,继承了祖先类 Object 的所有方法。
为什么数组不像字符串 String 那样单独定义一个类来表示呢?查看一下 String 类:
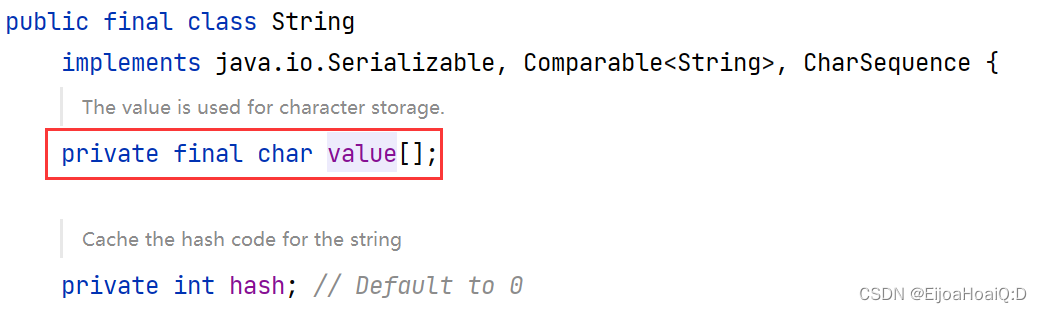
如果像 String 类这样,它就必须要定义一个容器来存放数组,在数组内部定义数组—duck不必。所以说可能 Java 将数组定义的类隐藏掉了。/** * @author QHJ * @date 2022/8/22 10:41 * @description: 引用数据类型 */ public class DataType { public static void main(String[] args) { int[] arrays = {1, 2, 3}; System.out.println("arrays:" + arrays); } }查看输出结果:
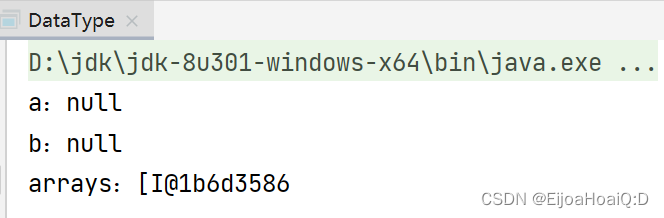
[I 表示数组是 int 类型的,@ 后面是十六进制的 hashCode。至于为什么会这样显示呢?查看一下 java.lang.Object 类的 toString() 方法:

-
接口
像 List 接口,只能 new 一个实现它的类的对象,所以接口自然也是引用数据类型了。
/** * @author QHJ * @date 2022/8/22 10:41 * @description: 引用数据类型 */ public class DataType { public static void main(String[] args) { List<String> list = new ArrayList<>(); System.out.println("list:" + list); } }查看输出结果:

4.1.2 基本数据类型(4类8种数据类型)
| 数据类型 | 关键字 | 内存占用 | 取值范围 |
|---|---|---|---|
| 字节型 | byte | 1个字节 | -128~127 |
| 短整型 | short | 2个字节 | -32768~32767 |
| 整型 | int(默认) | 4个字节 | -2147483648~2147483647 |
| 长整型 | long | 8个字节 | -2的63次方~2的63次方 |
| 单精度浮点数 | float | 4个字节 | 1.4013E~3.4028E+38(有效位数为6 ~ 7位) |
| 双精度浮点数 | double(默认) | 8个字节 | 4.9E-324~1.7977E+308(有效位数为 15 位) |
| 字符型 | char | 2个字节 | 0~65535 |
| 布尔类型 | boolean | 1个字节 | true,false |
注意:Java没有任何无符号(unsigned)形式的 int、long、short 或 byte 类型。
小贴士:
Java中的默认类型:整数类型是 int 、浮点类型是 double 。
long类型:建议数据后加 L 表示(不用小写是因为小写的 l 容易与数字 1 混淆)。
float类型:建议数据后加 f 表示。
4.1.3 大数类型
如果基本的整数和浮点数精度不能够满足要求,就可以使用 java.math 包中的两个类:BigInteger 和 BigDecimal。这两个类可以处理包含任意长度数字序列的数值(它可以表示一个任意大小且精度完全准确的浮点数)。
-
BigInteger
BigInteger类实现任意精度的整数运算。
但是,并不能使用我们熟悉的算数运算符(比如:+ 和 *)处理大数,而需要使用大数类中的 add() 和 multiply() 方法。
/** * @author QHJ * @date 2022/8/7 14:46 * @description: 大数 */ public class BigNumbers { public static void main(String[] args) { // 将普通的数值转换为大数 Integer a1 = 100; BigInteger a2 = BigInteger.valueOf(100); System.out.println(a1.getClass().getName() + ":" + a1); System.out.println(a2.getClass().getName() + ":" + a2); // 对于更大的数,使用一个带字符串参数的构造器 BigInteger reallyNums = new BigInteger("123457890987654323445667788996654433556788909"); System.out.println(reallyNums.getClass().getName() + ":" + reallyNums); // java 8 常量 BigInteger b = BigInteger.ONE; BigInteger c = BigInteger.ZERO; BigInteger d = BigInteger.TEN; // java 9 新增常量 BigInteger e = BigInteger.Two; System.out.println(b + "," + c + "," + d); BigInteger f = b.add(c); // 1 BigInteger g = f.multiply(c); // 0 BigInteger h = d.add(f); // 11 BigInteger i = h.multiply(h); // 121 BigInteger j = h.pow(2); // 121 System.out.println("f:" + f + ",g:" + g + ",h:" + h + ",i:" + i + ",j:" + j); } }
-
BigDcimal
BigDcimal类实现任意精度的浮点数运算。

3.2 基本数据类型
3.2.1 整型
整型用于表示没有小数部分的数值,允许是负数。
如果要使用不可能为负的整数值而且确实需要额外的一位(bit),也可以把有符号整数值解释为无符号数,但是要非常仔细。
例如:一个 byte 值 b 可以不表示范围 -128~127,如果想要表示 0~255的范围,也可以存储在一个 byte 中。
基于二进制算数运算的性质,只要不溢出,加法、减法、乘法都能正常计算。但是对于其他运算,需要调用 Byte.toUnsignedInt(b) 来得到一个 0~255的 int 值,然后处理这个整数值,再把它转换回 byte。
Integer 和 Long 类都提供了处理无符号除法和求余数的方法。
3.2.2 浮点类型
单精度:1 位符号,8 位指数, 23 位小数,有效位数为 7 位。
双精度:1 位符号,11 位指数,52 位小数,有效位数为 16 位。
取值范围取决于指数位,计算精度取决于小数位(尾数)。小数位数越多,则能表示的数越大,那么计算精度则越高。
浮点类型用于表示有小数部分的数值。double 表示这种类型的数值精度是 float 类型的两倍。float 类型的数值有一个后缀 F 或 f,没有后缀 F 的浮点数总是默认为是 double 类型,也可以在 double 类型的数值后面添加后缀 D 或 d。
所有的浮点数值计算都遵循 IEEE 754 规范。具体来说,下面是用于表示溢出和出错情况的三个特殊的浮点数值:
- 正无穷大(Infinity)
- 负无穷大(-Infinity)
- NaN (不是一个数字)
注意: 可以使用十六进制表示浮点数值。例如,0.125=2^-3 可以表示成 0xl.0p-3 = 1.0 * 2^-3。在十六进制表示法中, 使用 p 表示指数, 而不是 e。 注意, 尾数采用十六进制,指数采用十进制。指数(p)的基数是 2,而不是 10。
/**
* @author QHJ
* @date 2022/8/1 16:00
* @description: 测试
*/
public class TypeTest {
public static void main(String[] args) {
double x = 0.0d / 0.0;
System.out.println(Double.isNaN(x)); // true
// public static final double POSITIVE_INFINITY = 1.0 / 0.0;
System.out.println(x == Double.NaN); // false
System.out.println(Double.POSITIVE_INFINITY); // Infinity
// public static final double NEGATIVE_INFINITY = -1.0 / 0.0;
System.out.println(Double.NEGATIVE_INFINITY); // -Infinity
// public static final double NaN = 0.0d / 0.0;
System.out.println(Double.NaN); // NaN
}
}
Double.POSITIVE_INFINITY、Double.NEGATIVE_INFINITY、Double.NaN分别表示这三个特殊的值,但是在实际应用中很少遇到。
特别要说明的是, 不能这样检测一个特定值是否等于 Double.NaN:
if (x == Double.NaN) // is never true 所有“ 非数值” 的值都认为是不相同的。
然而,可以使用 Double.isNaN 方法:
if (Double.isNaN(x)) // check whether x is "not a number
3.2.3 char类型
char 类型用于表示单个字符,要用单引号括起来。char 类型的值可以表示位十六进制值,其范围从 \u0000 到 \uFFFF。
char 只有一个字符,却占用了两个字节,主要是因为 Java 使用的是 Unicode 字符集而不是 ASCII 字符集。字符集也可以叫做编码,编码不同,实际占用的字节就会不同。
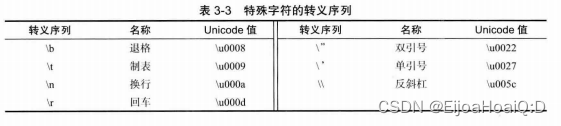
除了转义序列 \u 之外, 还有一些用于表示特殊字符的转义序列。所有这些转义序列都可以出现在加引号的字符字面量或字符串中。例如,’\02丨22’ 或 "1 110\11”。转义序列 \u 还可以出现在加引号的字符常量或字符串之外(而其他所有转义序列不可以)。例 如:public static void main(String\u005B\ u00SD args)就完全符合语法规则, \u005B 和 \u005D 是 [ 和 ] 的编码。
3.2.4 Unicode和char类型
Unicode 为所有字符指定了一个数字来表示该字符。
UTF-8 是目前互联网上使用最广泛的一种 Unicode 编码方式,它的最大特点就是可变长。它可以使用 1 - 4 个字节表示一个字符,根据字符的不同变换长度。
UTF-16 编码介于 UTF-32 与 UTF-8 之间,同时结合了定长和变长两种编码方法的特点。它的编码规则很简单:基本平面的字符占用 2 个字节,辅助平面的字符占用 4 个字节。也就是说,UTF-16 的编码长度要么是 2 个字节(U+0000 到 U+FFFF),要么是 4 个字节(U+010000 到 U+10FFFF)。
3.2.5 boolean类型
布尔类型有两个值:true 和 false,用来判定逻辑条件。整型值和布尔值之间不能进行互相转换。
3.3 数据类型转换
3.3.1 自动类型转换
转换规则:将取值范围小的类型自动提升为取值范围大的类型 。
当两个数值进行二元操作时,要先将两个操作数转换为同一种类型,然后再进行计算:
- 如果两个操作数中有一个是 double 类型,另一个操作数就会转换为 double 类型;
- 否则,如果其中一个操作数是 float 类型,另一个操作数将会转换为 float 类型;
- 否则,如果其中一个操作数是 long 类型,另一个操作数将会转换为 long 类型;
- 否则,两个操作数都将被转换为 int 类型。
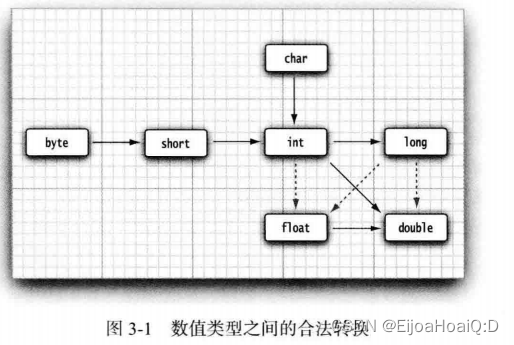
public static void main(String[] args) {
int a = 10;
double b = 2.5;
//int自动提升为double类型
//自动类型转换时,取值范围小的类型直接转换为取值范围大的类型
double c = a + b;
System.out.println(c);
}
小贴士(小->大):
byte、short、char‐‐>int‐‐>long‐‐>float‐‐>double
3.3.2 强制类型转换(cast)
转换规则:将取值范围大的类型强制转换成取值范围小的类型 。
转换格式:数据类型 变量名 = (数据类型)被转数据值;
public static void main(String[] args) {
//short类型变量,内存中2个字节
short s = 1;
/*
出现编译失败
s和1做运算的时候,1是int类型,s会被提升为int类型
s+1后的结果是int类型,将结果在赋值成short类型时发生错误
short内存2个字节,int类型4个字节
必须将int强制转成short才能完成赋值
*/
s = s + 1;//编译失败
s = (short)(s+1);//编译成功①
s+=1;//编译成功②,②是①通过内部强转得到的
// 可以使用 Math.round(double a) 方法对浮点数进行舍入运算,以便得到最接近的整数
int a = (int)round(9.997);
System.out.println(a); // 10
}
特别注意:
比较而言,自动转换是Java自动执行的,而强制转换需要我们自己手动执行;
浮点数转成整数,直接取消小数点(通过截断小数部分将浮点值转换为整型),可能造成数据损失精度;
可以使用 Math.round(double a) 方法对浮点数进行舍入运算,以便得到最接近的整数。
警告:如果试图将一个数值从一种类型强制转换为另一种类型, 而又超出了目标类型的表示范围,结果就会截断成一个完全不同的值。例如,(byte ) 300 的实际值为 44。
3.3 引用数据类型和基本数据类型的区别
-
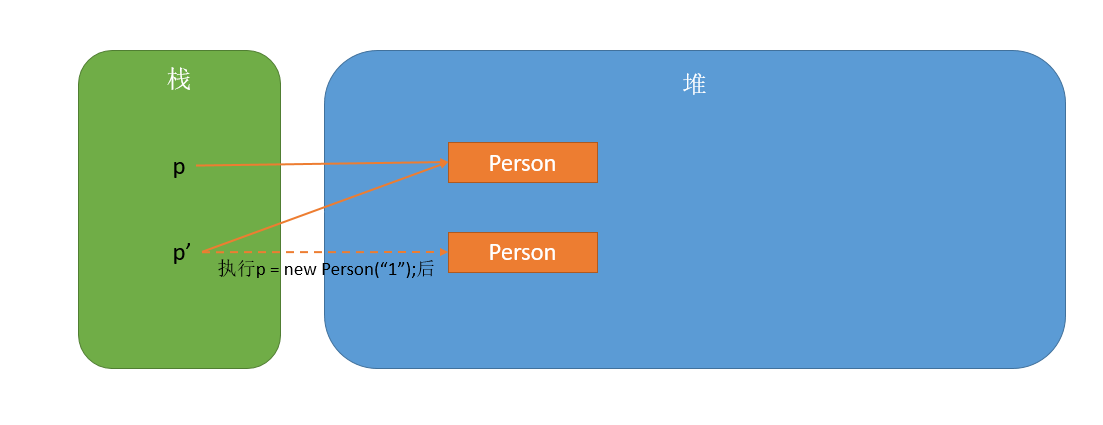
堆和栈
堆是堆,栈是栈。堆是在
程序运行时在内存中申请的空间(可以理解为动态的过程),切记不是在编译时。所以,Java 中的对象就放在这里,这样做的好处就是:当需要一个对象时,只需要通过 new 关键字写一行代码即可,当执行这行代码时,会自动在内存的"堆"区分配空间。
栈能够和处理器(CPU)直接关联,因此访问速度更快。Java 把对象的引用放在栈里,因为 Java 在编译程序时,必须明确的知道存储在栈里的东西的生命周期,否则就没法释放旧的内存来开辟新的内存空间存放引用(空间的大小是固定的)。
-
基本数据类型
- 变量名指向具体的数值;
- 基本数据类型在栈上。
-
引用数据类型
- 变量名指向的是存储对象的内存地址,在栈上;
- 内存地址指向的对象存储在堆上。
3.4 常用ASCII编码表(美国标准信息交换码)
| 字符 | 数值 |
|---|---|
| 0 | 48 |
| 9 | 57 |
| A | 65 |
| Z | 90 |
| a | 97 |
| z | 122 |