一般我们会认为创建线程的方式是三到四种,其实
本质上这四种没有任何区别,都是利用Thread+Runnable来进行实现的多线程,其实java自始至终创建多线程的方式都只有一种,下面一起看下他们是怎么对Runnable进行改造成多种多样的。
????????一、继承Thread
继承Thread下面是常见的写法
public class Test1 extends Thread{
@Override
public void run() {
while(true){
System.out.println("线程1");
}
}
public static void main(String[] args) {
new Test1().start();
}
}
利用这种方式实现的线程,就是继承Thread类然后重写run方法,我们在run方法内部进行线程逻辑的编写。java的start方法会调用start0方法,start0是一个native方法,底层会调用run方法进行执行线程,所以我们是重写run方法。那run方法是怎么来的呢?
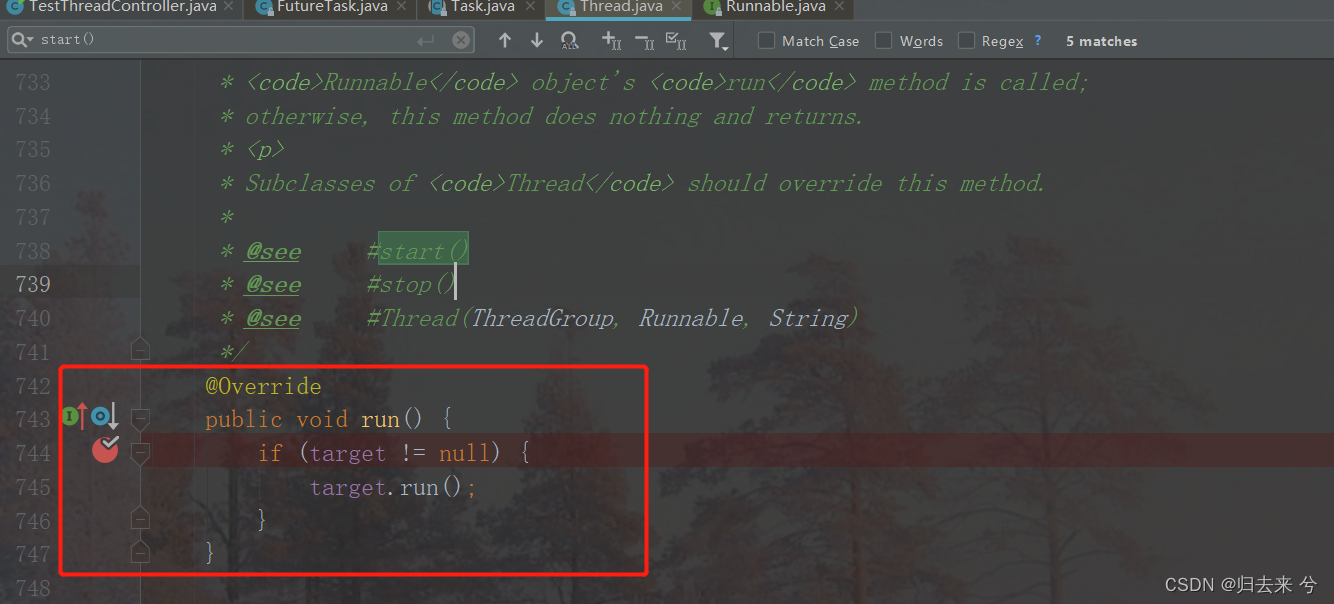
上面是run方法在Thread中的实现,我们可以看到他被注解Override修饰了,说明这个方法是父类的方法,我们点击左侧红色向上的箭头,就会发现跳到了Runnable接口中,如下
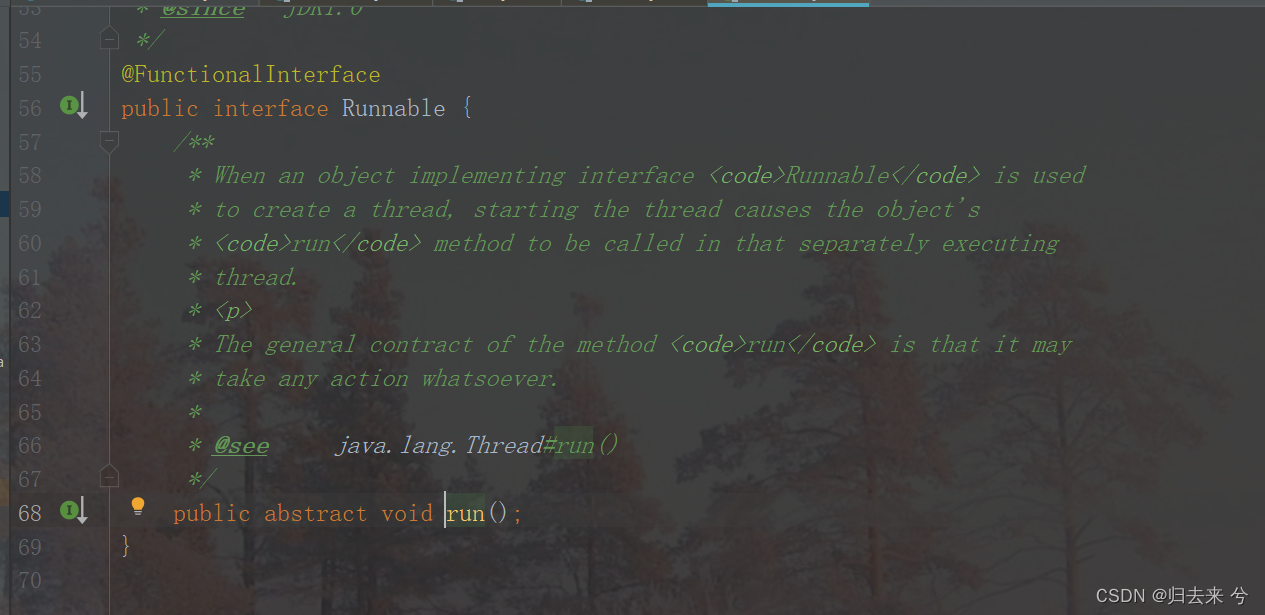
这样就很简单明了了,所以这样就简单明了了,我们在继承Thread重写run方法时其实重写的是Runnable的run方法。这这种已经证明了我们开始说的java是利用Thread+Runnable实现的多线程了。
????????二、实现Runnable接口
这种方式也是需要依赖Thread才能去创建线程,如下所示
public class TestThread {
public static void main(String[] args) {
new Thread(() -> {
while(true)
System.out.println("Runnable多线程1");
}).start();
new Thread(() -> {
while(true)
System.out.println("Runnable多线程2");
}).start();
}
}
那我们来看下这个实现方式到底是如何进行多线程创建的吧,我们还是从run方法开始,因为Thread启动线程时调用的是自己的run方法,那我们就先看下他自己的run方法实现:
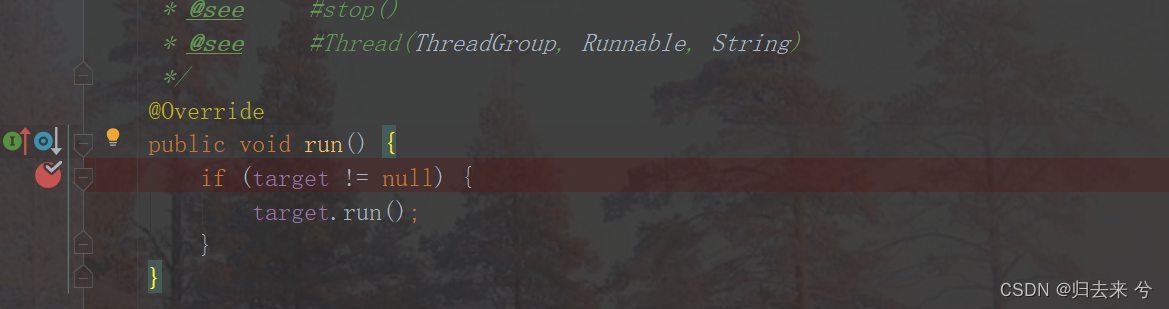
可以看到Thread的run方法调用的是target.run方法,那target是什么呢?ctrl+左会发现,他就是一个Runnable,那这个Runnable怎么来的呢?我们创建过程中只在Thread的构造方法中传入了Runnable,那是不是在这里咱们一起看下:

这里没有做什么实质的操作,所以继续看,最后调用到了这里:
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc) {
if (name == null) {
throw new NullPointerException("name cannot be null");
}
this.name = name.toCharArray();
Thread parent = currentThread();
SecurityManager security = System.getSecurityManager();
if (g == null) {
/* Determine if it's an applet or not */
/* If there is a security manager, ask the security manager
what to do. */
if (security != null) {
g = security.getThreadGroup();
}
/* If the security doesn't have a strong opinion of the matter
use the parent thread group. */
if (g == null) {
g = parent.getThreadGroup();
}
}
/* checkAccess regardless of whether or not threadgroup is
explicitly passed in. */
g.checkAccess();
/*
* Do we have the required permissions?
*/
if (security != null) {
if (isCCLOverridden(getClass())) {
security.checkPermission(SUBCLASS_IMPLEMENTATION_PERMISSION);
}
}
g.addUnstarted();
this.group = g;
this.daemon = parent.isDaemon();
this.priority = parent.getPriority();
if (security == null || isCCLOverridden(parent.getClass()))
this.contextClassLoader = parent.getContextClassLoader();
else
this.contextClassLoader = parent.contextClassLoader;
this.inheritedAccessControlContext =
acc != null ? acc : AccessController.getContext();
this.target = target; // 这里是关键点
setPriority(priority);
if (parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
/* Stash the specified stack size in case the VM cares */
this.stackSize = stackSize;
/* Set thread ID */
tid = nextThreadID();
}
我们会发现这个方法内部将我们从构造器中传入的Runnable对象放到了this.target中,所以可以看到Thread中的run方法调用的就是我们重写的run方法。所以这个也证明了java中是通过Thread+Runnable实现的多线程方式。
????????三、实现Callable接口
这种方式我们需要依赖FutrureTask,其实我们可以接受返回值也得归功FutureTask,下面是常见的实现代码:
public class TestThread {
public static void main(String[] args) throws Exception{
FutureTask<String> futureTask = new FutureTask<>(()->{
int i =0 ;
while(i<100)
System.out.println("Callable线程1在执行:"+i++);
return "线程1执行完了";
});
FutureTask<String> futureTask2 = new FutureTask<>(()->{
int i =0 ;
while(i<100)
System.out.println("Callable线程2在执行:"+i++);
return "线程2执行完了";
});
new Thread(futureTask).start();
new Thread(futureTask2).start();
System.out.println(futureTask.get());
System.out.println(futureTask2.get());
}
}
run方法才是多线程的执行地方,还是一样我们还是从run方法开始看,我们点击下new Thread会进入Thread的构造器,发现进入的构造器和第二种是一样的:

这就说明FutureTask一定实现了或者继承了Runnable接口,其实FutureTask实现了RunnableFuture接口,而RunnableFuture继承了Runnable接口,因为继承和实现的特性,相当于FutureTask实现了Runnable接口。那走到这个构造器就是理所当然那的了。所以与第二种方式相同的是Thread调用的target.run就是FutureTask的run了。我们来看下FutureTask的run方法吧:
public void run() {
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
上面是FutureTask的run方法,里面真正调用的是c.call方法,看到call方法应该就明白了,不错这个call就是我们传入到FutureTask中的Callable实例的call方法,所以FutureTask的调用路线也就清晰了:Thread.start–>Thread.run–>FutureTask.run–>Callable.call。而FutureTask则是Runnable的子类,所以也证明了我们一开始说的java是通过Thread+Runnable来实现的多线程。此外通过这里我们还可以清洗的看到FutureTask是怎么实现参数返回接收的,就是因为call方法有返回,然后FutureTask的run方法接收到返回后将他存放到自身的泛型V中,然后我们就可以直接通过FutureTask.get方法进行获取了。其实这种思想java里有很多,比如常见的http请求的包装类也是通过这种思想来处理流数据的。
????????四、通过线程池创建
线程池这里咱们采用自己实现的线程池来进行解释说明,其实没啥区别,只不过是我们一般使用线程池都是禁止直接使用jdk自带线程池的所以才有用自己实现的线程池来看这个问题
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1,1, 60,TimeUnit.SECONDS, new SynchronousQueue<Runnable>(),Executors.defaultThreadFactory(),new ThreadPoolExecutor.DiscardPolicy() );
threadPoolExecutor.execute(()->{
while(true){
System.out.println("线程4执行中");
}
});
关于各个参数的意思,这里就不解释了,需要的看这里:,言归正传,我们看下线程池是怎么创建线程的,线程池提交任务有submit和execute还有一个定时的schedule,不过schedule他的线程池类不是这个,不过原理一样这里只介绍ThreadPoolExecutor的。我们看下execute的实现方法
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
// 此处省略原文注释
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {//判断线程是否小于核心线程数,很明显第一次会进入这里
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
很明显第一次执行会执行:addWorker(command, true)这个方法,我们再看下这个方法做了什么
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);//这个firstTask实际就是我们从execute传入的Runnable实现类
final Thread t = w.thread;//获取thread,因为线程开启必须利用Thread的start方法,这两步就是最关键的地方
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();//这里真正调用了线程启动
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
最关键的两步,笔者在代码中加了注释了,可以看到会将我们传入的Runnable的实现类交给Worker的构造器,那我们看看这个构造器又干了什么:

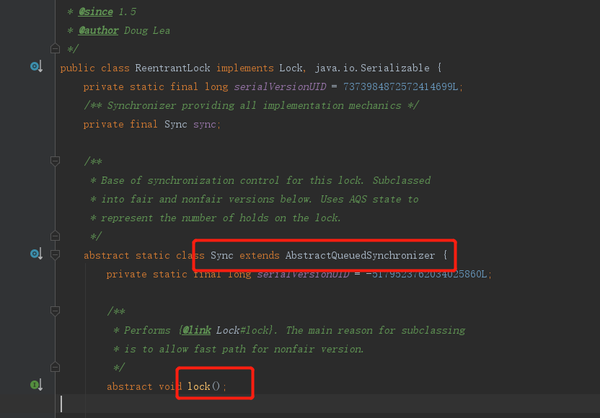
可以看到在这个构造器里面,将我们传入的Runnable给到了自己的Runnable,对他的私有变量进行了初始化,然后又对thread进行了初始化,而初始化Thread时传入了this,注意传入的是this。因为Worker实现了Runable,所以当我们真正执行start方法时,调用的应该是Worker的run方法,所以我们到这里应该去看run方法了,run方法很简单,他直接调用了runWorer方法,那看下runWorker的实现:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;//将Runnable的对象指向一个新的引用
w.firstTask = null;//失效原引用
w.unlock(); // allow interrupts//加锁,worker实现了AQS,支持锁
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();//这里相当于运行了我们在execute中传入的Runnable对象的run方法了。
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
看笔者在代码中加的注释很清晰就看到最终调用的是我们从execute中传入的Runnable的对象的run方法。所以我们看到这里也是可以得出一个解决线程池还是利用Thread+Runnable接口一起实现的多线程。那么来从新梳理下线程池的调用过程:
execute(Runnable)–>
addWorker(command, true)–>内部对Worker(Runnale)进行初始化,Worker该类实现了Runnable,初始化Worker时生产线程Thread传入Worker自己,之后获取上一步生产的thread调用start方法。执行start方法,实际执行的是Worker的run方法,worker.run方法调用了runWorker方法,该方法执行时是将Worker的Runnable的对象的run方法进行调用执行。而Worker的Runnable的对象就是在addWorker中由execute方法传入的Runnable实现类。这样整个流程就很清晰了,我们也是可以佐证一开始说的观点了。
????????五、总结
看了以上四种分析,我们可以清晰的发现了java中其实创建线程的方式就只有一种就是利用Thread+Runnable来实现多线程。其他多有方式都是对这个实现方式的变种。如有不对欢迎路过的朋友指正,也希望能帮到路过的朋友