1,什么是kafak
kafka是一种事件的流式处理平台,他的主要的三个特性是
- 发布和订阅时间流,包括连续导入/导出来之其他系统的数据
- 持久可靠的存储事件流
- 在事件发生或回顾性地处理事件流
2,kafka的体系结构
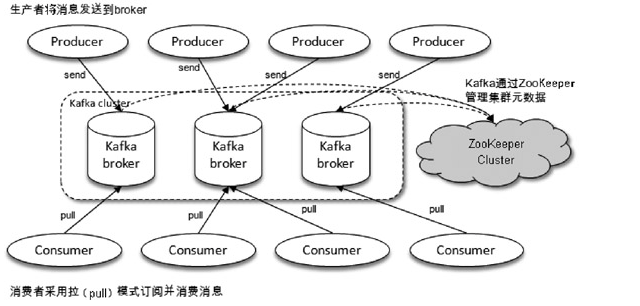
- producer 负责生产消息
- consumer 负责消费消息
- broker 服务代理节点。Broker可以简单地看作一个独立的Kafka服务节点或Kafka服务实例。也可以将Broker看作一台Kafka服务器,前提是这台服务器上只部署了一个Kafka实例。一个或多个Broker组成了一个Kafka集群。
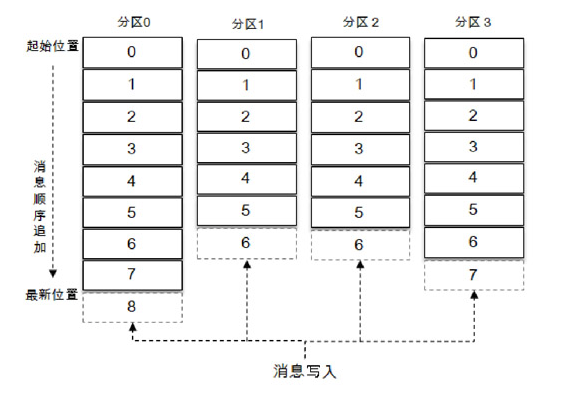
2.1 topic
消息的主题,一个主题可以分为多个分区(partition),同一个主题下不同分区内的消息是不同的,分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。offset是消息在分区中的唯一标识,Kafka通过它来保证消息在分区内的顺序性,不过offset并不跨越分区,也就是说,Kafka保证的是分区有序而不是主题有序。
题中有 4 个分区,消息被顺序追加到每个分区日志文件的尾部。Kafka中的分区可以分布在不同的服务器(broker)上,也就是说,一个主题可以横跨多个broker,以此来提供比单个broker更强大的性能。
如果一个主题只有一个分区,这个主题的I/O性能取决于当前机器的读写瓶颈
2.2 副本机制
kafka 为分区引入了多副本(Replica)机制,通过增加副本数量可以提升容灾能力。同一分区的不同副本中保存的是相同的消息(在同一时刻,副本之间并非完全一样),副本之间是“一主多从”的关系,其中leader副本负责处理读写请求,follower副本只负责与leader副本的消息同步。副本处于不同的broker中,当leader副本出现故障时,从follower副本中重新选举新的leader副本对外提供服务。Kafka通过多副本机制实现了故障的自动转移,当Kafka集群中某个broker失效时仍然能保证服务可用。
3,kafka的安装 略
4,简单的生产者和消费者示例代码
生产者
public class ProducerDemo {
public static final String brookeList = "";
public static final String topic="";
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("key","");
properties.put("value","");
properties.put("bootstrap.servers","");
//配置生产者客户端并创建producer实例
KafkaProducer<String,String> producer = new KafkaProducer<>(properties);
//构建要发送的消息
ProducerRecord record = new ProducerRecord(topic,"hello kafka");
try {
producer.send(record);
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close();
}
}
}
消费者
public class ConsumerDemo {
public static void main(String[] args) {
Properties props= new Properties();
//props.put("bootstrap.servers","192.168.44.161:9093,192.168.44.161:9094,192.168.44.161:9095");
props.put("bootstrap.servers","172.16.57.34:9092");
props.put("bootstrap.servers","172.16.57.34:9092");
props.put("group.id","gp-test-group");
// 是否自动提交偏移量,只有commit之后才更新消费组的 offset
props.put("enable.auto.commit","true");
// 消费者自动提交的间隔
props.put("auto.commit.interval.ms","1000");
// 从最早的数据开始消费 earliest | latest | none
props.put("auto.offset.reset","earliest");
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String,String> consumer=new KafkaConsumer<String, String>(props);
// 订阅topic
consumer.subscribe(Arrays.asList("test"));
try {
while (true){
ConsumerRecords<String,String> records=consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String,String> record:records){
log.info("offest:{},key:{},value:{},partition:{}",record.offset(),record.key(),record.value(),record.partition());
// System.out.printf("offset = %d ,key =%s, value= %s, partition= %s%n" ,record.offset(),record.key(),record.value(),record.partition());
}
}
}finally {
consumer.close();
}
}
}
4.1 服务端参数
zookeeper.connect
breoker 节点连接zk的地址
listeners
该参数指明broker监听客户端连接的地址列表,即为客户端要连接broker的入口地址列表
broker.id
该参数用来指定Kafka集群中broker的唯一标识,默认值为-1。如果没有设置,那么Kafka会自动生成一个。这个参数还和meta.properties文件及服务端参数broker.id.generation.enable和reserved.broker.max.id有关
log.dir和log.dirs
kafka日志存放地址
message.max.bytes
用来指定broker所能接收消息的最大值,默认值为1000012(B),约等于976.6KB。如果Producer 发送的消息大于这个参数所设置的值,那么(Producer)就会报出RecordTooLargeException的异常。如果需要修改这个参数,那么还要考虑max.request.size (客户端参数)、max.message.bytes(topic端参数)等参数的影响。为了避免修改此参数而引起级联的影响,建议在修改此参数之前考虑分拆消息的可行性
5,生产者详解
public class ProducerRecord<K, V> {
private final String topic;
private final Integer partition;
private final Headers headers;
private final K key;
private final V value;
private final Long timestamp;
}
生产者示例中的参数
- topic 主题
- partition 分区号
- headers 消息的头部,Kafka 0.11.x版本才引入这个属性,它大多用来设定一些与应用相关的信息,如无需要也可以不用设置
- key 用来指定消息的键,不仅是消息的附加信息,还可以用来计算分区号进而可以让消息发往特定的分区。前面提及消息以主题为单位进行归类,而这个key可以让消息再进行二次归类,同一个key的消息会被划分到同一个分区中,有key的消息还可以支持日志压缩的功能。
- value 消息体
- timestamp 指消息的时间戳,它有CreateTime和LogAppendTime两种类型,前者表示消息创建的时间,后者表示消息追加到日志文件的时间
KafkaProducer是线程安全的,可以在多个线程中共享单个KafkaProducer实例,也可以将KafkaProducer实例进行池化来供其他线程调用
5.1 kafkaproducer的池化
1,创建连接池工厂
public class KafkaProducerFactory extends BasePooledObjectFactory<KafkaProducer<String, String>> {
private final Properties kafkaProps;
public KafkaProducerFactory(Properties kafkaProps) {
this.kafkaProps = kafkaProps;
}
@Override
public KafkaProducer<String, String> create() throws Exception {
return new KafkaProducer<>(kafkaProps);
}
@Override
public PooledObject<KafkaProducer<String, String>> wrap(KafkaProducer<String, String> producer) {
return new DefaultPooledObject<>(producer);
}
@Override
public void destroyObject(PooledObject<KafkaProducer<String, String>> p) throws Exception {
p.getObject().close();
super.destroyObject(p);
}
}
2,创建连接池
public class KafkaProducerPool {
private final GenericObjectPool<KafkaProducer<String, String>> producerPool;
public KafkaProducerPool(Properties kafkaProps) {
KafkaProducerFactory factory = new KafkaProducerFactory(kafkaProps);
this.producerPool = new GenericObjectPool<>(factory);
}
public KafkaProducer<String, String> borrowProducer() throws Exception {
return producerPool.borrowObject();
}
public void returnProducer(KafkaProducer<String, String> producer) {
producerPool.returnObject(producer);
}
}
3,多线程环境使用连接池
try {
KafkaProducer<String, String> producer = kafkaProducerPool.borrowProducer();
// 使用 producer 发送消息
} finally {
kafkaProducerPool.returnProducer(producer);
}
5.2 消息的发送
发送消息主要有三种模式:发后即忘(fire-and-forget)、同步(sync)及异步(async)
上面的代码送方式就是发后即忘,它只管往Kafka中发送消息而并不关心消息是否正确到达。在大多数情况下,这种发送方式没有什么问题,不过在某些时候(比如发生不可重试异常时)会造成消息的丢失。这种发送方式的性能最高,可靠性也最差。
5.2.1 同步发送
producter.send方法返回值不是void,shi是Future
使用
producer.send(record).get();
执行send()方法之后直接链式调用了get()方法来阻塞等待Kafka的响应,直到消息发送成功,或者发生异常。如果发生异常,那么就需要捕获异常并交由外层逻辑处理。
在RecordMetadata对象里包含了消息的一些元数据信息,比如当前消息的主题、分区号、分区中的偏移量(offset)、时间戳等
tips: Future 表示一个任务的生命周期,并提供了相应的方法来判断任务是否已经完成或取消,以及获取任务的结果和取消任务等。可以用Java语言层面的技巧来丰富应用的实现,比如使用Future中的 get(long timeout,TimeUnit unit)方法实现可超时的阻塞
异常
KafkaProducer中一般会发生两种类型的异常:可重试的异常和不可重试的异常。常见的可重试异常有:NetworkException、LeaderNotAvailableException、UnknownTopicOrPartitionException、NotEnoughReplicasException、NotCoordinatorException 等。比如NetworkException 表示网络异常,这个有可能是由于网络瞬时故障而导致的异常,可以通过重试解决;又比如LeaderNotAvailableException表示分区的leader副本不可用,这个异常通常发生在leader副本下线而新的 leader 副本选举完成之前,重试之后可以重新恢复。不可重试的异常,比如 RecordTooLargeException异常,是所发送的消息太大,KafkaProducer对此不会进行任何重试,直接抛出异常。对于可重试的异常,如果配置了 retries 参数,那么只要在规定的重试次数内自行恢复了,就不会抛出异常。retries参数的默认值为0,配置方式参考如下
properties.put(ProducerConfig.RETRIES_CONFIG,10);
5.2.2 异步发送
一般是在send()方法里指定一个Callback的回调函数,Kafka在返回响应时调用该函数来实现异步的发送确认。为啥不在send()方法的返回值类型就是Future,而Future本身就可以用作异步的逻辑处理。这样做不是不行,只不过Future里的 get()方法在何时调用,以及怎么调用都是需要面对的问题,消息不停地发送,那么诸多消息对应的Future对象的处理难免会引起代码处理逻辑的混乱。使用Callback的方式非常简洁,Kafka有响应时就会回调,要么发送成功,要么抛出异常。异步发送方式的示例如下:
try {
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
exception.printStackTrace();
} else {
System.out.println(metadata.topic()+ "-"+ metadata.partition()+"-"+ metadata.offset());
}
}
});
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close();
}
5.3 原理分析
消息在真正发往Kafka之前,有可能需要经历拦截器(Interceptor)、序列化器(Serializer)和分区器(Partitioner)等一系列的作用,那么在此之后又会发生什么呢?
kafka的底层架构用的还是Netty,原理篇详情可以借鉴《深入理解kafka》这本书的2.2章节
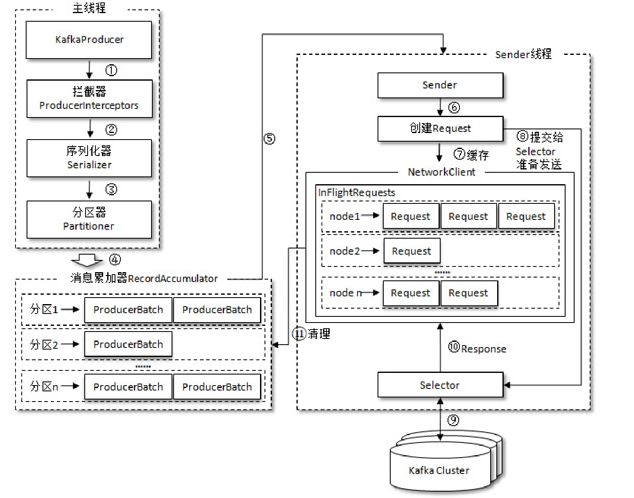
RecordAccumulator 主要用来缓存消息以便 Sender 线程可以批量发送,进而减少网络传输的资源消耗以提升性能。RecordAccumulator 缓存的大小可以通过生产者客户端参数buffer.memory 配置,默认值为 33554432B,即 32MB。如果生产者发送消息的速度超过发送到服务器的速度,则会导致生产者空间不足,这个时候KafkaProducer的send()方法调用要么被阻塞,要么抛出异常,这个取决于参数max.block.ms的配置,此参数的默认值为60000,即60秒
5.4 客户端重要参数
ack
用来指定分区中必须要有多少个副本收到这条消息,之后生产者才会认为这条消息是成功写入的
- ack=1 生产者发送消息之后,只要分区的leader副本成功写入消息,那么它就会收到来自服务端的成功响应
- acks=0。生产者发送消息之后不需要等待任何服务端的响应。如果消息从发送到写入Kafka的过程中出现某些异常,导致Kafka并没有收到这条消息,那么生产者也无从得知,消息也就丢失了。在其他配置环境相同的情况下,acks 设置为 0 可以达到最大的吞吐量
- acks=-1或acks=all。生产者在消息发送之后,需要等待ISR中的所有副本都成功写入消息之后才能够收到来自服务端的成功响应。在其他配置环境相同的情况下,acks 设置为-1(all)可以达到最强的可靠性。但这并不意味着消息就一定可靠,因为ISR中可能只有leader副本,这样就退化成了acks=1的情况。要获得更高的消息可靠性需要配合 min.insync.replicas 等参数的联动
max.request.size
这个参数用来限制生产者客户端能发送的消息的最大值,默认值为 1048576B,即 1MB
retries和retry.backoff.ms
retries参数用来配置生产者重试的次数,默认值为0,即在发生异常的时候不进行任何重试动作
compression.type
指定消息的压缩
更多参数的含义,参考ProducterConfig