Java内存区域
1、如何解释 Java 堆空间及 GC?
当通过 Java 命令启动 Java 进程的时候,会为它分配内存。内存的一部分用于创建
堆空间,当程序中创建对象的时候,就从对空间中分配内存。GC 是 JVM 内部的一
个进程,回收无效对象的内存用于将来的分配。
2、JVM 的主要组成部分及其作用?
组成部分:

-
JVM 包含两个子系统和两个组件,两个子系统为:Class loader(类装载)和
Executionengine(执行引擎);
-
两个组件为 Runtime data area(运行时数据区)、Native Interface(本地接
口)。
-
Class loader(类装载):
根据给定的全限定名类名(如:java.lang.Object)来装载class 文件到Runtime data area 中的 method area。
-
Execution engine(执行引擎):执行 classes 中的指令。
-
Native Interface(本地接口):与 native libraries 交互,是其它编程语言交
互的接口。
-
Runtime data area(运行时数据区域):这就是我们常说的 JVM 的内存。
作用:
首先通过编译器把 Java 代码转换成字节码,类加载器(ClassLoader)再把字节
码加载到内存中,将其放在运行时数据区(Runtime data area)的方法区内,而
字节码文件只是 JVM 的一套指令集规范,并不能直接交给底层操作系统去执行,因
此需要特定的命令解析器执行引擎(Execution Engine),将字节码翻译成底层系统
指令,再交由 CPU 去执行,而这个过程中需要调用其他语言的本地库接口(Native
Interface)来实现整个程序的功能。
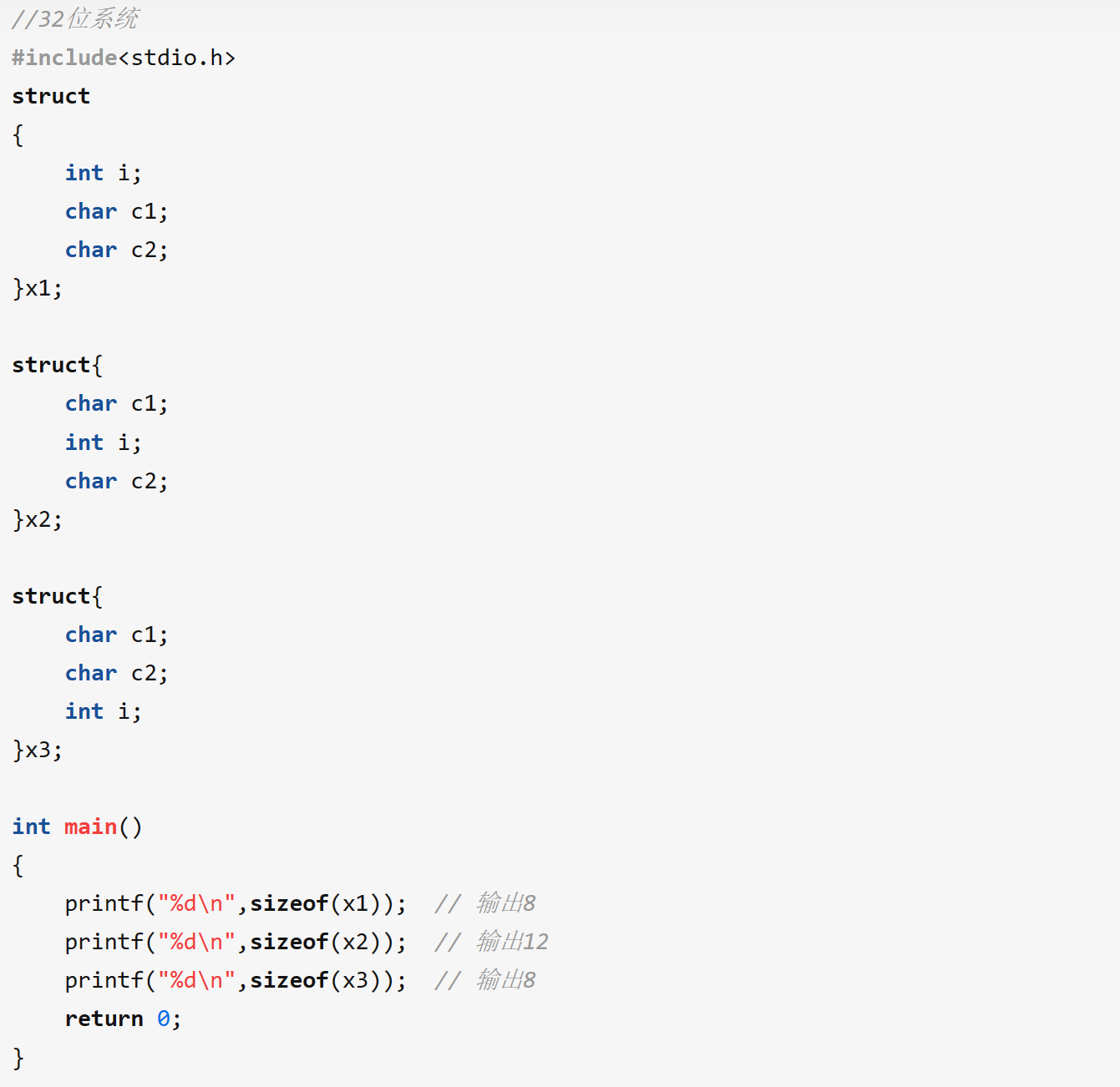
3、Java 程序运行机制详细说明
Java 程序运行机制步骤
-
首先利用 IDE 集成开发工具编写 Java 源代码,源文件的后缀为.java;
-
再利用编译器(javac 命令)将源代码编译成字节码文件,字节码文件的后缀名
为.class;
-
运行字节码的工作是由解释器(java 命令)来完成的。

从上图可以看,java 文件通过编译器变成了.class 文件,接下来类加载器又将这
些.class 文件加载到 JVM 中。
其实可以一句话来解释:类的加载指的是将类的.class 文件中的二进制数据读入到
内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个java.lang.Class
对象,用来封装类在方法区内的数据结构。
4、JVM 内存模型
Java 虚拟机在执行 Java 程序的过程中会把它所管理的内存区域划分为若干个不同
的数据区域。这些区域都有各自的用途,以及创建和销毁的时间,有些区域随着虚
拟机进程的启动而存在,有些区域则是依赖线程的启动和结束而建立和销毁。Java
虚拟机所管理的内存被划分为如下几个区域:

-
程序计数器(Program Counter Register):当前线程所执行的字节码的行
号指示器,字节码解析器的工作是通过改变这个计数器的值,来选取下一条
需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功
能,都需要依赖这个计数器来完成;
-
Java 虚拟机栈(Java Virtual Machine Stacks):用于存储局部变量表、操
作数栈、动态链接、方法出口等信息;
-
本地方法栈(Native Method Stack):与虚拟机栈的作用是一样的,只不
过虚拟机栈是服务 Java 方法的,而本地方法栈是为虚拟机调用 Native 方法
服务的;
-
Java 堆(Java Heap):Java 虚拟机中内存最大的一块,是被所有线程共享
的,几乎所有的对象实例都在这里分配内存;
-
方法区(Methed Area):用于存储已被虚拟机加载的类信息、常量、静态
变量、即时编译后的代码等数据。
深拷贝和浅拷贝
-
浅拷贝(shallowCopy)只是增加了一个指针指向已存在的内存地址;
-
深拷贝(deepCopy)是增加了一个指针并且申请了一个新的内存,使这个增
加的指针指向这个新的内存;
使用深拷贝的情况下,释放内存的时候不会因为出现浅拷贝时释放同一个内存的错
误。
-
浅复制:仅仅是指向被复制的内存地址,如果原地址发生改变,那么浅复制
出来的对象也会相应的改变。
-
深复制:在计算机中开辟一块新的内存地址用于存放复制的对象。
堆栈的区别
物理地址
-
堆的物理地址分配对对象是不连续的。因此性能慢些。在 GC 的时候也要考
虑到不连续的分配,所以有各种算法。比如,标记-消除,复制,标记-压缩,分代(即新生代使用复制算法,老年代使用标记——压缩)。 -
栈使用的是数据结构中的栈,先进后出的原则,物理地址分配是连续的。所
以性能快。
内存分别
-
堆因为是不连续的,所以分配的内存是在运行期确认的,因此大小不固定。一般
堆大小远远大于栈。
-
栈是连续的,所以分配的内存大小要在编译期就确认,大小是固定的。
存放的内容
-
堆存放的是对象的实例和数组。因此该区更关注的是数据的存储
-
栈存放:局部变量,操作数栈,返回结果。该区更关注的是程序方法的执行。
例如:
-
静态变量放在方法区
-
静态的对象还是放在堆
程序的可见度
-
堆对于整个应用程序都是共享、可见的。
-
栈只对于线程是可见的。所以也是线程私有。他的生命周期和线程相同。
Java 中堆和栈的区别
JVM 中堆和栈属于不同的内存区域,使用目的也不同。栈常用于保存方法帧和局部
变量,而对象总是在堆上分配。栈通常都比堆小,也不会在多个线程之间共享,而堆
被整个JVM 的所有线程共享。
队列和栈是什么?有什么区别?
队列和栈都是被用来预存储数据的。
-
操作的名称不同。队列的插入称为入队,队列的删除称为出队。栈的插入称
为进栈,栈的删除称为出栈。
-
可操作的方式不同。队列是在队尾入队,队头出队,即两边都可操作。而栈
的进栈和出栈都是在栈顶进行的,无法对栈底直接进行操作。
-
操作的方法不同。队列是先进先出(FIFO),即队列的修改是依先进先出的
原则进行的。新来的成员总是加入队尾(不能从中间插入),每次离开的成员
总是队列头上(不允许中途离队)。而栈为后进先出(LIFO),即每次删除(出
栈)的总是当前栈中最新的元素,即最后插入(进栈)的元素,而最先插入的
被放在栈的底部,要到最后才能删除。
虚拟机栈(线程私有)
-
它是描述 java 方法执行的内存模型,每个方法在执行的同时都会创建一个栈帧
(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。
每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到
出栈的过程。
-
栈帧( Frame)是用来存储数据和部分过程结果的数据结构,同时也被用来处
理动态链接(Dynamic Linking),方法返回值和异常分派(DispatchException)。
栈帧随着方法调用而创建,随着方法结束而销毁——无论方法是正常完成还是
异常完成(抛出了在方法内未被捕获的异常)都算作方法束。

程序计数器(线程私有)
一块较小的内存空间, 是当前线程所执行的字节码的行号指示器,每条线程都
要有一个独立的程序计数器,这类内存也称为“线程私有” 的内存。
正在执行 java 方法的话,计数器记录的是虚拟机字节码指令的地址(当前指
令的地址) 。如果还是 Native 方法,则为空。这个内存区域是唯一一个在
虚拟机中没有规定任何 OutOfMemoryError 情况的区域。
什么是直接内存?
直接内存并不是 JVM 运行时数据区的一部分, 但也会被频繁的使用: 在JDK 1.4 引入
的 NIO 提供了基于 Channel 与 Buffer 的 IO 方式, 它可以使用 Native 函数库直接
分配堆外内存, 然后使用 DirectByteBuffer 对象作为这块内存的引用进行操作(详见:
Java I/O 扩展), 这样就避免了在 Java 堆和 Native 堆中来回复制数据, 因此在一些
场景中可以显著提高性能。