计算机数据的表示
1. 数值数据的表示
1.1 各种进制数的表示
-
二进制 (Binary) :以
0b或0B开头,字符仅含0和1.- 用下标2或者数字后面加
B表示。如 $(1011)_2$ 或 $1011B$
- 用下标2或者数字后面加
-
八进制 (Octal) :以
0o或0O开头,字符含0-7.- 用下标8或者数字后面加
O表示。如 $(17)_8$ 或 $17O$
- 用下标8或者数字后面加
-
十六进制 (Hexadecimal) :以
0x或0X开头,字符含0-9、a-f(代表10-15).- 用下标16或者数字后面加
H表示。如 $(a1b1)_{16}$ 或 $a1b1H$
- 用下标16或者数字后面加
1.2 进制转换
R进制与十进制的转换
- R进制转十进制:按位权展开。计算每位数字与该位位权乘积的代数和然后相加。
- 十进制转R进制:除以 R 逆序取余。
二、八、十六进制互转
-
二转八进制:从右往左每三位转一位八进制,最左边不足三位添0补齐。反之八进制每一位转三位二进制。
-
二转十六进制:从右往左每四位转一位十六进制,最左边不足四位添0补齐。反之十六进制每一位转四位二进制。
python中的相关函数:
-
int(*x*,base=10)这个函数按照base进制对数x进行解释,返回一个使用数字或字符串生成的整数int对象,无实参返回0。
其中x为数字或字符串,base为进制,取值范围为[2,36]和0。
一个进制为n的整数包含0到n-1的整数,其中a-z(A-Z)表示10到35。
进制为0将会按照x字面的前缀进行解释,结果是2、8、10、16中的一个。
要清楚的一点是,在python中带有前缀的数字,例如0xa,0o12,0b1010它们的类型(type)都是 int 整数类型。
如果想知道它们十进制数值,可以直接print,或 print(int(x)) ,也可以 int(str(x),base=0)(?).
对这个函数的使用,主要分为三种情况:
- x为
int类型:无论带不带前缀,这个数的进制已经清楚,它表示一个确定大小的数字。该函数无法对一个进制清楚的非字符串类型进行转换(启用base关键字)。 - x为
str字符串类型:- 带前缀:表明这个数的进制已经清楚,base只能等于其前缀或0。
- 不带前缀:根据用法自由发挥。注意没有前缀且令base=0的话应注意x其形式。比如int("010",base=0)是非法的。因为解释器认为x是十进制数,但x形式是错误的。
- x为byte类型:暂时空缺。
x=int(156,base=2) #报错
x=int(0x156,base=0) #报错
x1="0101" #字符串
y1=int(x1,base=2) # 结果为整数5
y2=int(x1,base=8) # 结果为整数65
y3=int(x1,base=16) # 结果为整数257
y4=int(x1,base=35) # 结果为整数1226
x2="0xa5f1"
y5=int(x,base=16) # 结果为整数42481
y6=int(x,base=0) # 结果为整数42481
hex(x)
将整数转换为以0x为前缀的十六进制字符串。
bin(x)
将整数转换为以0b为前缀的二进制字符串。
oct(x)
将整数转换为以0o为前缀的八进制字符串。
1.3 机器码的表示
计算机中数的主要类型
- 整数(定点数)
- 无符号整数
- 8位($0~2^{8}-1$)
- 16位($0~2^{16}-1$)
- 32位($0~2^{32}-1$)
- 有符号整数
- 8位($-27~2-1$)
- 16位($-2{15}~2-1$) 16位整数
- 32位($-2{31}~2-1$) 短整数
- 64位($-2{63}~2-1$) 长整数
- 无符号整数
- 浮点数
- 32位(单精度浮点数)
- 64位(双精度浮点数)
- 128位(扩充精度浮点数)
真值、字长、机器数
-
机器数:0或1 + 二进制绝对值
- 计算机不认识除了0和1之外的任何符号,因此要专门留出一位用来表示正负号。
- 将符号数字化的数,是数字在计算机中的二进制表示形式。
-
真值:正负号 + 二进制绝对值
- 计算机中的二进制机器数分为“
有符号数”和“无符号数”两种。 - “无符号数”就是二进制数的每一位都代表对应位的数值;而在“有符号数”中规定最高位用来表示数据符号,其中1代表负,0代表正,这样一来机器数本身就不等于真正的数值了。例如有符号数10000101,其最高位1代表负,所以余下的“0000101”才是数值本身,所以其真正数值是-5,而如果是无符号数,则10000101所代表的是133。为区别起见,把带符号位的机器数所对应的真正数值称为机器数的“真值”。例:00100001的真值=0 0100001=+33(正号可以不写,可以直接写成33),10100011的真值=1 0100011=-35。
- 计算机中的二进制机器数分为“
-
字长
-
字:指计算机进行数据处理时,一次存取加工和传送的数据长度(字长度)。一个字通常是字节的整数倍。
-
字长 是指计算机一次可处理的二进制数的码位长度,是计算机进行数据存储和数据处理的运算单位。如我们通常所指的32位处理器,就是指该处理器的字长为32位,也就是一次能处理32位二进制数。通常称16位是一个字,32位是一个双字,64位是两个双字。
-
数值的转换结果是与字长有关的。如果计算机字长为8位,十进制中的数+5转换成二进制就是
00000101,-5转换成二进制就是10000101;但如果字长是16位,+5转换的结果就是00000000 00000101,而-5转换成二进制就是10000000 00000101了。也就是对应的机器数要转换为字长所代表的位数。 -
字长越长代表计算机的处理能力越强,可以处理的数越大。
-
在8位字长中,除去符号位,实际可以处理的数值大小范围为[-127,-0]~[+0,127](即$2^7 -1$),共256个数。
-
16位字长可以处理的数值大小是[-32677,-0]~[0,32767]($2^{15} -1$)。
-
64位字长计算机可以处理的二进制数码位长度最大为64位,去掉符号位,则表示计算机可以处理的最大二进制数为 $2^{63}-1$,最小二进制数就是 $-2^{63}$。
-
-
注意 以上的“-0”与“0”的机器数是不一样的,在8位字长中,-0为1 0000000,而+0为0 0000000;在16位字长中,-0为1 0000000 00000000,而+0为0 0000000 00000000。所以在二进制的机器数中,0也有两个(-0和0),且表示形式并不一样。
-
设机器字为8b字长,数N1的真值为 +1001110,数N2的真值为 -1001110,则N1、N2对应的机器数为:
01001110
11001110
原码表示法
符号位加数值的二进制。
有正零和负零之分。
反码表示法
-
正数的补码、反码和原码都相同
-
负数的符号位与原码、补码相同,数值将原码的数值位按位取反。
补码表示法
原码的计算不方便,因此引入补码的概念
-
正数的补码、反码和原码都相同
-
负数的的补码是先把除符号位外其他各位取反,再在末位加1。
| TH | 定点整数 | 定点小数 |
|---|---|---|
| 原码 | $-(2{n-1}-1),2-1$ | $(-1,1)$ |
| 反码 | $-(2{n-1}-1),2-1$ | $(-1,1)$ |
| 补码 | $-2{n-1},2-1$ | $[-1,1)$ |
- 运算前将所有参与运算的数据转换为补码
- 将转换后的数值进行运算
- 运算结果再次求补码,得到最后的结果
移码表示法
1.4 二进制逻辑运算
-
与运算 AND
- 又称逻辑乘。用符号$\land$ 或
·表示
对应位均为1结果才为1.
- 又称逻辑乘。用符号$\land$ 或
-
或运算 OR
- 又称逻辑加。用符号 $\lor$ 或
+表示
对应位有一个为1结果就为1.
- 又称逻辑加。用符号 $\lor$ 或
-
非运算 NOT
- 按位取反
-
异或运算 XOR
- 用符号$\bigoplus$ 表示
对应位相同结果为0 ,不同结果为1。
- 用符号$\bigoplus$ 表示
2. 非数值数据的表示
- 非数值数据:文字和符号(字符)、图像、声音等
- 非数值数据的表示:对其进行二进制编码。任何数据存储到计算机中都是二进制数。
字符编码
- 编码:编码是将源对象内容按照某种标准转换为另一种格式内容。解码是和编码对应的,它使用和编码相同的标准将编码内容还原为最初的对象内容。
- 码点:一个编码表中的某个字符对应的代码值。比如ASCII中字符
A的码点是65 - 字符集:某种编码标准所支持的所有字符及其对应码点的集合。(书写系统字母与符号的集合)
- 字符编码:字符到存储在计算机上的内容(特定的字节或字节序列)之间的映射,是一种规则。通常特定的字符集采用特点的编码方式。一种字符集可能有多种编码方案,比如
utf-8、utf-16等
- 字符编码:字符到存储在计算机上的内容(特定的字节或字节序列)之间的映射,是一种规则。通常特定的字符集采用特点的编码方式。一种字符集可能有多种编码方案,比如
ASCII码
常用的7位 $ASCII$ 码(American Standard Code for Information Interchange码,即美国信息交换标准代码)的每个字符都由7个二进制位b6~b0 表示,有128个编码,最多可表示128种字符。其中包括:
- 10个数字
0~9:30H~39H,48~57(十进制); - 26个小写字母
a~z:61H~7AH ,97~122; - 26个大写字母
A~Z:41H~5AH ,65~90; - 各种运算符号和标点符号等。
在计算机中,用1B(一个字节)表示一个ASCII码,其最高一位(b7位)填0,余下的7b可以给出128个编码,表示128个不同的字符和控制码。
其中95个编码,对应着计算机终端能敲入并且可以显示的95个字符,打印机设备也能打印这95个字符,如大小写各26个英文字母,0—9这10个数字符,通用的运算符和标点符号+,-,*,/,>,=,< 等等。
UTF-8编码
- Unicode字符集
- 在Unicode中,每个字符占据一个码位/Unicode 编号(用4位十六进制数表示,Code point:U+ FFFF),字符集中的字符与Unicode 编号一一映射。如
U+ 0000为“Null”,U+ 597D="好"。Unicode字符集共定义了1 114 112个这样的位,使用从0到10FFFF的十六进制数唯一地表示世界上几乎所有字符。NCR(Numeric Character Reference),以「&#」开头的后接十进制数字,以「&#x」开头的后接十六进制数字。
- 在Unicode中,每个字符占据一个码位/Unicode 编号(用4位十六进制数表示,Code point:U+ FFFF),字符集中的字符与Unicode 编号一一映射。如
由于计算机存储数据通常是以字节为单位的,而且出于兼容之前的ASCII(0x00-0x7F)、节省存储空间等诸多原因,需要一种具体的编码方式来对字符码位进行标识。规定每个字符的Unicode编号如何存储(用一个字节还是多个字节存储,用哪些字节来存储),常见的基于Unicode字符集的编码方式有UTF-8、UTF-16及UTF-32。
同一段二进制,每一个字节一个编号还是每两个字节一个编号,解码方式不一样,得到的编号不一样,对应的映射字符也不同,这就是乱码的原因。“锟斤拷”、“烫”就是这样来的。
汉字编码
对于汉字,计算机的处理技术必须解决三个问题:
- 汉字输入
- 汉字储存与交换
- 汉字输出
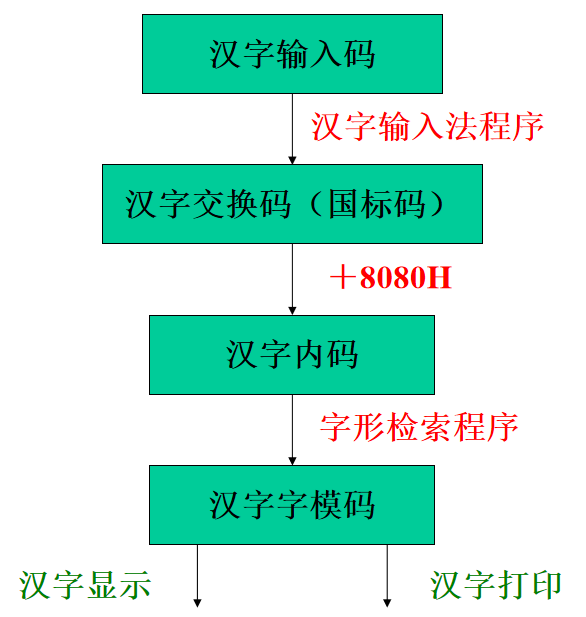
它们分别对应着汉字输入码、内码、字模码的概念。
因此,汉字编码系统存在以下三种编码:
- 汉字输入码
- 汉字内码
- 汉字字模码
汉字输入码
汉字输入码也称 外码 ,是为了将汉字输入计算机而编制的代码,是代表某一汉字的一串键盘符号。
汉字输入码种类:
- 数字编码:如区位码、国标码、电报码等。
- 拼音编码:如全拼码、双拼码、简拼码等。
- 字形编码:如王码五笔、郑码、大众码等。
- 音形编码:如表形码、智能ABC等。
两种典型的数字编码:
- 区位码:是将国家标准局公布的6763个两级汉字分为94个区,每个区分94位,实际上把汉字表示成二维数组,每个汉字在数组中的下标就是区位码。
- 例如“中”字位于54区48位,“中”字的区位码即为“5448”。
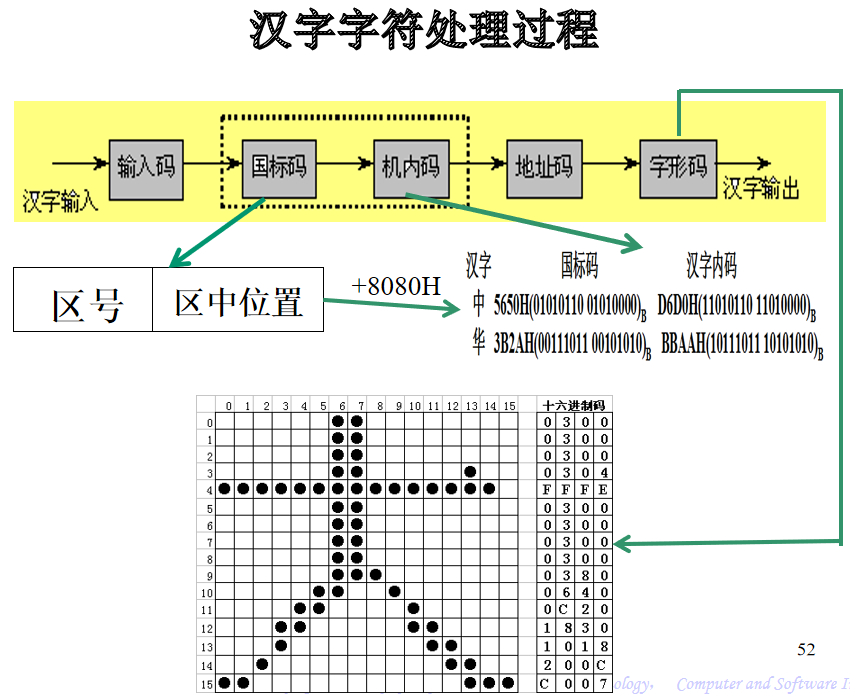
- 国标码:将区位码加2020H,占用两个字节。
- 例如“中”字的国标码为区位码5448的区码和位码转化为16进制,为3630H,再加2020H得国标码5650H。
- 汉字字符集与编码
- 1981年,GB2312-80国家标准,其字符及编码称为国标码又叫国际交换码。
- GB2312字符集的构成:
一级常用汉字3755个,按汉语拼音排列
二级常用汉字3008个,按偏旁部首排列
非汉字字符682个
一般用2个字节来存放汉字;
汉字分区,每个区94个汉字;
汉字内码
汉字内码是用于汉字信息的存储、交换、检索等操作的机内代码,一般采用两个字节表示。
-
汉字可以通过不同的输入法输入,但其内码在计算机中是唯一的。
-
英文字符的机内代码是7位的ASCII码,当用一个字节表示时,最高位为“0”。为了与英文字符能相互区别,汉字机内代码中两个字节的最高位均规定为“1”。
-
机内码等于汉字国标码加上8080H。
- 例如“中”字的机内码为5650H+8080H=D6D0H。
汉字字模码
汉字字模码又称汉字字形码,它是将汉字字形经过点阵数字化后形成的一串二进制数,用于汉字的显示和打印。
-
根据汉字输出的要求不同,点阵有以下几种:
- 简易型汉字:16×16, 32字节/汉字
- 普通型汉字:24×24, 72字节/汉字
- 提高型汉字:32×32,128字节/汉字。
-
汉字字库:将所有汉字的字模点阵代码按内码顺序集中起来,构成了汉字库。
-
汉字字形点阵中每个点的信息用一位二进制码来表示,“1”表示对应位置处是黑点,“0”表示对应位置处是空白。
例如16×16点阵,每个汉字就要占32个字节