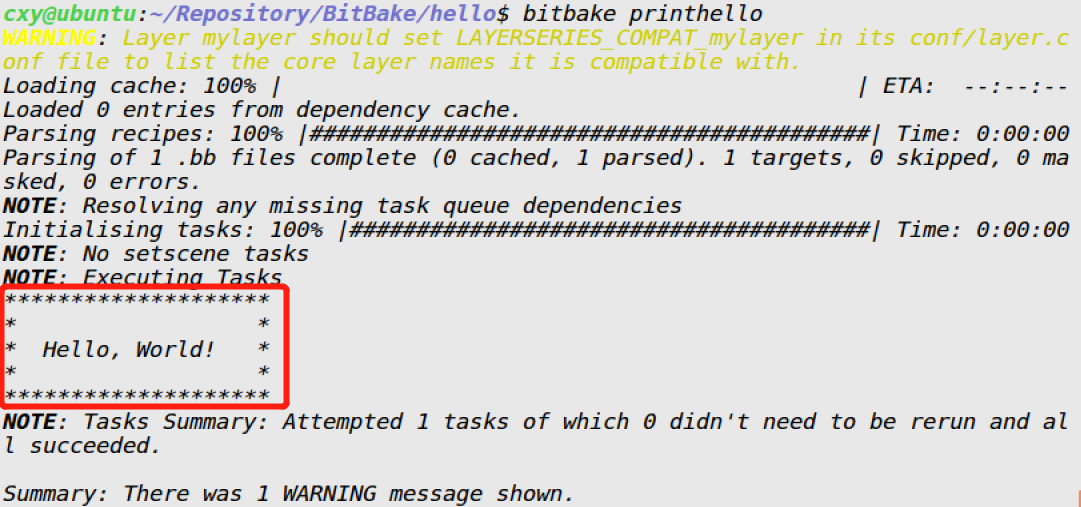
前言
连接(Join)是关系数据库重要特性,它和事务常被作为数据库与文件系统的两个重要区别项。程序员江湖一直流传着某某 baba 的神秘开发宝典,其中数据库部分有重要一条避免过多表的 Join,奈何 Join 特性实在是好用,广大程序员们无视着宝典的谆谆教诲,依旧每天乐此不疲的使用这 Join 特性。那数据库有哪些连接算法呢?它们的实现方式是怎样呢?它们之间又有什么区别呢?为什么需要这么多不同的连接算法呢?如果你也好奇这些问题,那么请继续往下阅读,本文将逐一回答上述问题。
关联算法简介
关系型数据库主要有三种 Join 算法:Nested Loop Join,Hash Join、 Merge Join,像 Oracle、SqlServer 、DB2 这几位数据库中的老炮均支持三种 Join 方式;MySQL 长久以来只支持 NLJ 或其变种,直到8.0.18 版本后才有限的支持 Hash Join。在 「程序员必备的数据库知识:数据存储结构」一文中介绍了数据库几种常见的数据存储结构,存储引擎之上是计算引擎。以 MySQL 数据库为例,计算引擎层通常包括 SQL 接口、解析器、查询优化器、缓存等组件,数据库 Join 实现就在计算引擎的查询优化器中。
以 MySQL 数据库为例,计算引擎层
然而数据库具体选择哪种连接算法,是由本身决定的,主要根据当前的优化器模式、表大小、连接列是否有索引和排序等因素决定。
多表连接方式又分为:内连接(等值连接)、外连接和交叉连接,外连接又分为:左外连接、右外连接和全外连接。对于不同方式的连接查询,使用相同的 Join 算法也会有不同的成本产生,这和实现方式紧密相关的。本文不涉及同一个 Join 算法在不同连接方式的情况。
Nested Loop Join
NLJ 是 MySQL 最重要的连接方式,也是 MySQL 长期唯一支持的连接方式,直到 8.0.18 版本 MySQL 才有限的支持 Hash Join。那什么是 NLJ 呢?从概念上讲,NLJ 相当于两个嵌套循环,用第一张表做 Outter Loop,第二张表做 Inner Loop,Outter Loop 的每一条记录跟 Inner Loop 的记录作比较,最终符合条件的就将该数据记录。
可以用以下伪代码表示:
NLJ 可以用伪代码表示
如果忽略内存和 CPU 的时间,它的成本是:
Cost(NLJ) = Read(M) + M * Read(N) (其中M和N表示需要读两个关联表中的数据行数)
NLJ 的算法比较简单,并且对 Join 的连接条件没有特殊要求(Hash Join 通常只支持等值,Merge Join 一般不支持不等和like),在有索引过滤性较好的 OLTP 场景下,它的查询效率很高。缺点也同样明显,由于它的成本是:Read(M) + M * Read(N) 。在 OLAP 需要大表间 Join 场景下,它的查询效率变得比较差。在 MySQL 中 NLJ 还有两个变种:Index Nested Loop Join(INLJ)、Block Nested Loop Join(BNLJ),本文不涉及这方面的扩展,有兴趣的同学可以深入研究。
Hash Join
Hash Join 是Oracle、SQLServer 、PostgreSQL 中重要的关联算法,当两个表关联时,选择一张表按照 join 条件给的列构建 hash 表,然后将第二张表的每行记录去探测 hash 表中的数据,如果符合连接条件就输出该数据。前一张表我们叫做 build 表,后一张表我们的叫做 probe 表。为了减少内存使用量,通常选择小表作为 hash 表,大表作为 probe 表。
Hash Join
经典 Hash Join 主要有两个步骤:选择 hash 表,扫描该表并创建 hash 表;将另一个作为 probe 表,扫描每一行数据,然后在 hash 表中找寻对应的满足条件的记录。忽略内存和 CPU 时间,它的成本是:
Cost(HJ) = Read(M) + Read(N)
Hash Join 需要把表放到内存中,如果内存不够怎么办?为了处理这种情况,又诞生一些 Hash Join 的变种,比如 Grace Hash Join 。简单说是通过分区方式实现,根据关联字段将两个表的数据分区,然后对同一分区的数据再进行原生 Hash join 的 build 与 probe 过程,最后将所有分区的数据合并成最后的结果集。当然在实际中会更复杂,比如在大数据量的情况下,有概率出现不同数据的 HASH 值却是相同的问题。
总的来说,Hash Join 是处理大表间 Join 的不错选择。MySQL 在 8.0.18 前一直没有 Hash join 的实现,甚至在5.5以前只有最原始的 NLJ,5.5后才有 NLJ 优化变种的 B(Block)NLJ。但 Oracle 早在7.3版本之后就引入了 Hash join 算法,在 OLAP 领域中 Hash join 更是绝对的标配,Greenplum 和 Spark SQL 就充分利用了它。但是它也有缺点,比如只能使用等值查询、需要更多的内存资源等。
Merge Join
Merge Join ,准确地说它叫 Sort Merge Join, 在合并关联查询时要先确保两个关联表是按关联字段相同排序的。如果关联字段有可用的索引(配合聚集索引服用效果更佳)并且排序一致,则可以直接进行Merge 操作,否则要先对关联表按照关联字段进行一次排序。排好序后,再从每个表取一条记录开始匹配,如果符合关联条件,则放入结果集中;否则将关联字段值较小的记录抛弃,从这条记录对应的表中取下一条记录继续进行匹配,直到整个循环结束。因此它的成本是这样的:
COST(MJ) = Read(M) + Sort(M) + Read(N) + Sort(N)
显然,Merge Join 适合在关联列上有索引的表,最好在关联列还有相同的排序方式,在这种情况下它的关联查询效率是最高的。但是关联字段如果没有排序,那么它的排序阶段则比较耗时。
总结
通过前文的分析,我们基本可以回答文章最开头的几个问题了,更多信息可以看下表格。另外,除了上述常见的三种数据库Join方式外,还有 Hive 支持 Map Join 和 Reduce Join。
常见 Join 算法的优势对比总览
作者
司马辽太杰是 NineData 工程师。NineData 向企业和个人提供高效、安全的数据库 SQL 开发、数据库备份、数据复制/迁移/集成、数据对比等功能,是一个 SaaS 服务开箱即用,可以快速提升企业 SQL 开发效率,保障企业数据安全。NineData 地址:https://www.ninedata.cloud/