笔者这次是第一次写东西,主要是想把在运用中的一些实例给记录下来,分享给那些和笔者有同样需求的人。可能分享的方法有些累赘或者不准确,还望各位大佬勿喷,因为笔者也是python小白,这些都是通过搜索汇总得出来的。
需求:
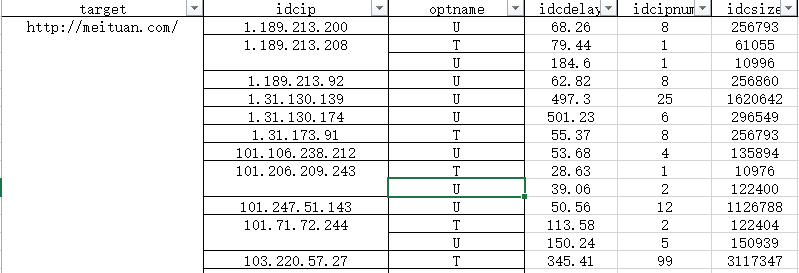
原数据格式:

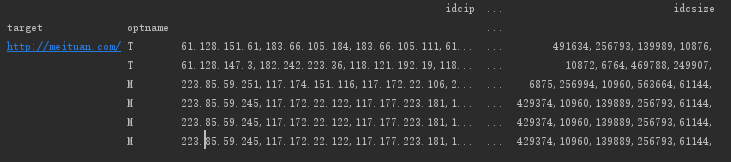
我们要变成下面的样子:(这里是做了分组和求和)
解决需求:
#数据是直接从数据库中查出来的,所以直接导入excel的数据,也可以直接连数据进行查询。
import pandas as pd
info_new2=pd.read_excel("E:/路径/文件名.xlsx", sheet_name='sheet名')
#将网站和运营商设置为索引
info_1 = info_new2.set_index(['target','optname'])
print(info_1)
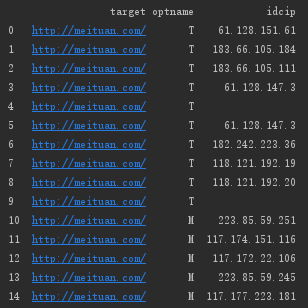
#筛选出IP字段
ip = info_1['idcip']
#将idcip列以‘,’分开,分成多列
ipdf = ip.str.split(',',expand = True)
#将列转换为行
ip = ipdf.stack()
#将最后一级索引删除
ip = ip.reset_index(drop=True,level=-1)
#再调用一次reset_index,会自动进行笛卡尔乘积
ipdf = ip.reset_index()
#将自动生成的0列进行重命名
ipdf = ipdf.rename(columns={0:'idcip'})
print(ipdf)
#后面将idcsize,idcdelay,idcipnum进行同样的操作。只是这三个字段在后面会求和计算,需要将类型转换为数字型。
#将时延列有文本转为数字型
info_delay= pd.to_numeric(delaydf['idcdelay'],errors='coerce')
#合并,按照网站和运营商和IP合并
info_two=pd.concat([ipdf,info_delay,info_ipnum,info_size],axis=1)
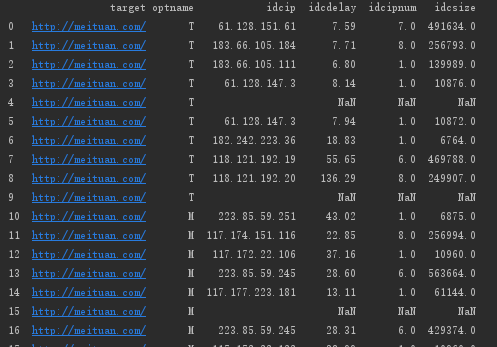
#去除idcdelay列为空的行
info_two = info_two[info_two['idcdelay'].notna()]
#按照'target','idcip','optname'分组,'idcdelay','idcipnum','idcsize'分别求和
info_he=info_two.groupby(['target','idcip','optname'])['idcdelay','idcipnum','idcsize'].sum()
#写入excel
info_he.to_excel("E:\\地址\\文件名.xlsx", sheet_name=sheet名)
大功告成!(第一次发表,希望大家多多包涵!)