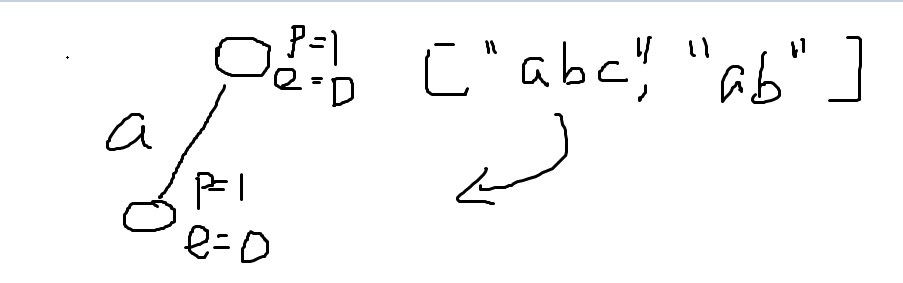矩阵求导的性质
\]
\]
若上述式子中A为对称矩阵,则第二条性质可变为如下形式:
\]
上述的性质前提为:使用分母布局
矩阵求导的应用——线性回归

根据上面的表格,可以绘制出散点图

不难发现图中有一条较为明显的线性关系。可以将其称之为估计值,其中y1为直线的截距,而y2则为直线的斜率
\]
对于上图中的数据而言,此时的y1与y2还可以称之为较好运算,但当数据维度过大时,计算就变得复杂。所以可以使用矩阵来大幅度简化运算的复杂性。其中就会用到矩阵求导。
但求解具体过程之前,还有一些前置概念如下:
当我们带入一个新的x1想要估计其对应的身高时,会根据预测直线的函数得到一个确定值,即
\]
根据具体的数据,我们还会有一个实际的身高值,姑且称之为z1
这二者之间会存在一个偏差,分两种情况可以进行计算:
- 估计值大于实际值
- 估计值小于实际值
但二者的共同点就是,都是利用纵坐标的差值进行计算。只是最终的结果会有正有负。所以可以用平方来解决这个需要分类的问题。
\]
\]
\]
\]
上述这些估计和实际的值之差的平方有n组,对其进行求和运算,可以得到代价函数J
\]
如果我们现在找到一组y1,y2使得代价函数最小,此时的这个过程就叫做——线性回归
根据导数的定义,我们可以轻松得到如下关系:
\begin{aligned}
\frac{\partial J}{\partial y_{1}}=0 \\
\frac{\partial J}{\partial y_{2}}=0 \\
\end{aligned}
\right.\]
求解上述方程组,可以得到我们想要的y1以及y2,但这里有个问题,代价函数中的未知数很多,并且式子展开也较复杂,求解起来很麻烦,所以这时我们尝试用矩阵进行求解。并且目前计算机中GPU对矩阵的计算效率很高,所以也会更加利于计算机编程。
于是乎我们尝试将估计直线的方程进行矩阵形式的改写,如下图所示

此时就可以将代价函数改写为矩阵相乘的形式

于是乎我们就可以对代价函数进行展开,并进行求导,求解我们需要的矩阵y,而求解的过程中就用到了开头中矩阵求导的两则性质。
第一个红框用到了矩阵求导性质中的第一个$$\frac{\partial A\vec{y}}{\partial \vec{y}} =A^{T} $$
第二个红框用到了矩阵求导性质的第二个,因为x的转置与x相乘得到的新矩阵是对称的
\]

至此,求解完毕。
梯度下降法
虽然上述方法可以求解出需要的两个y,但需要注意的是,最终得到的y的表达式中,括号中左乘的逆矩阵不一定有解,很多情况下是无解的,所以说就无法算出解析解。
在机器学习中,有一个简单的方法叫梯度下降法。其实上图中J对y向量的导数,就是J在y向量方向上的梯度。
梯度下降法有两步:
- 第一步是定义初始的y*
- 第二步是使得y=y-α▽,其中α称作学习率,在此处无限循环,直到得到一个满意解
当学习率过低时,得到的解会和解析解相差较大,这是因为学习率过低导致学习的太慢了
当学习率过大时,大概率得到的解会爆掉,这是因为在极值点附近左右横跳,类似山谷小球。
观察解析解可以得知,y1是y2的100多倍,相差很大,所以说可以选择将学习率构造为一个2x2的矩阵,其中主对角线上的元素分别对应y1和y2的学习率,y1的学习率大一些,y2的学习率小一些。
但事实上在实际情况中这样肯定是不行的,只是举例的问题很特殊,毕竟你不可能提前知道上述的这些条件。还有精力去给不同的y分配不同的学习率。
所以会对z与x进行归一化处理,将其拉到一个统一的区域内,这样就方便使用同一个学习率了。