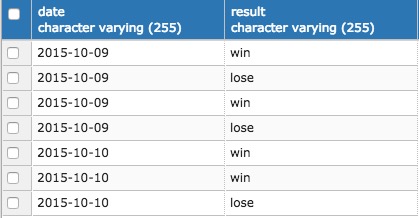
PostgreSQL的MVCC是直接在原表通过增加新tuple来实现的,决定了它在大结果集count的时候性能不会太理想,因为需要对大结果集做可见性判断将会是一项繁重的工作,比如下面这种SQL:
select count(*) from big_tab;
单纯依靠DB进行优化,确实不是一件容易的事情。本文整理了count(*)的几种方式,并就提升count性能做初步探讨,效果不太理想,如果后续有朋友找到更好的方法,期待分享。
测试表及数据准备
创建一个测试表,并导入5kw的数据量:
akendb=# create table aken01(id int,name text,info text,primary key(id));CREATE TABLEakendb=# insert into aken01 select id,'aken_'||id,md5(random()::text) from generate_series(1,50000000) as id;INSERT 0 50000000akendb=# akendb=# \d+ aken01;Table "public.aken01"Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+----------+--------------+-------------id | integer | | not null | | plain | | name | text | | | | extended | | info | text | | | | extended | | Indexes: "aken01_pkey" PRIMARY KEY, btree (id)akendb=#
PostgreSQL大表count的方式
在执行count之前先analyze一下:
akendb=# analyze aken01;ANALYZETime: 536.959 ms1.直接count原表统计。这是方式得到的结果是最真实的,但耗时较长:
akendb=# select count(*) from aken01;count----------50000000(1 row)Time: 22097.741 ms (00:22.098)
2.通过统计信息统计
这种方式因为可以直接从系统表里面拿到数据,结果较快,但只是一个估计值,该方式可以有下面几种方法:
1)方法一:
akendb=# select n_live_tup as estimate_rows from pg_stat_all_tables where relname = 'aken01';estimate_rows---------------50002378(1 row)Time: 13.768 msakendb=#
2)方法二:
akendb=# select reltuples::bigint as estimate_rows from pg_class where relname = 'aken01';estimate_rows---------------50002376(1 row)Time: 0.682 msakendb=#
3)方法三:
akendb=# select (reltuples/relpages) * (pg_relation_size('aken01')/(current_setting('block_size')::integer)) as rows from pg_class where relname = 'aken01'; rows ---------- 50002376(1 row)Time: 2.457 msakendb=#
4)方法四:通过函数或执行计划信息统计
这里参考Michael Fuhr提供的方法,创建一个function从count语句的执行计划统计:
akendb=# CREATE FUNCTION count_estimate(query text) RETURNS integer ASakendb-# $func$akendb$# DECLAREakendb$# rec record;akendb$# rows integer;akendb$# BEGINakendb$# FOR rec IN EXECUTE 'EXPLAIN ' || query LOOPakendb$# rows := substring(rec."QUERY PLAN" FROM ' rows=([[:digit:]]+)');akendb$# EXIT WHEN rows IS NOT NULL;akendb$# END LOOP;akendb$# RETURN rows;akendb$# ENDakendb$# $func$ LANGUAGE plpgsql;CREATE FUNCTIONTime: 1.023 msakendb=#
执行统计:
akendb=#SELECT count_estimate('select 1 FROM aken01'); count_estimate ---------------- 50002376(1 row)Time: 3.226 msakendb=#
4.触发器统计
这种方式对表的dml事件创建一个触发器,然后通过计数表进行rows统计,这样能得到一个真实的统计值,但会拖慢dml的性能。
具体可参考A. Elein Mustain的文章:
http://www.varlena.com/GeneralBits/120.php
5.通过扩展插件统计
我们还可以通过pgstattuple这个扩展实现,这种能得到真实的结果,但效率比较慢:
1)创建扩展:
akendb=# create extension pgstattuple;CREATE EXTENSIONakendb=# \dxList of installed extensionsName | Version | Schema | Description --------------------+---------+------------+------------------------------------------------------------------- pg_stat_error | 1.0 | public | track error code of all processes pg_stat_log | 1.0 | public | track runtime execution statistics of all SQL statements executed pg_stat_statements | 1.5 | public | track execution statistics of all SQL statements executed pglogical | 2.2.1 | pglogical | PostgreSQL Logical Replication pgstattuple | 1.5 | public | show tuple-level statistics plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language(6 rows)akendb=#
2)执行统计
akendb=# select relname,(pgstattuple(relname)).tuple_count as rows from pg_class where relname='aken01'; relname | rows ---------+---------- aken01 | 50000000(1 row)Time: 10082.679 ms (00:10.083)akendb=# akendb=# insert into aken01(id,name,info) values(50000001,'aken01','aken'); INSERT 0 1Time: 2.459 msakendb=# select relname,(pgstattuple(relname)).tuple_count as rows from pg_class where relname='aken01'; relname | rows ---------+---------- aken01 | 50000001(1 row)Time: 10327.826 ms (00:10.328)akendb=#
优化尝试
对于数据库而言,SQL优化策略是尽量减少CPU的运算以及page的扫描数量。我们可以猜想,在没有任何谓词的count(*)查询,如果能有一个比原表小得多的索引覆盖到我们需要的数据,那么使用index-only scans的访问路径来替代seq scan,理论上应该是可以帮助我们实现优化的。
先来看最初的执行计划:
akendb=# explain (analyze,buffers,verbose) select count(*) from aken01; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------ Aggregate (cost=1140368.00..1140368.01 rows=1 width=8) (actual time=15423.918..15423.919 rows=1 loops=1) Output: count(*) Buffers: shared hit=156264 read=359104 I/O Timings: read=717.207 -> Seq Scan on public.aken01 (cost=0.00..1015368.00 rows=50000000 width=0) (actual time=0.034..7601.345 rows=50000001 loops=1) Output: id, name, info Buffers: shared hit=156264 read=359104 I/O Timings: read=717.207 Planning time: 0.074 ms Execution time: 15423.970 ms(10 rows)akendb=#
上面这里走的全表扫描Seq Scan on table,主键索引约为表的1/4:
akendb=# SELECT pg_size_pretty(pg_relation_size('aken01')); pg_size_pretty ---------------- 4026 MB(1 row)akendb=# SELECT pg_size_pretty(pg_relation_size('aken01_pkey')); pg_size_pretty ---------------- 1071 MB(1 row)akendb=#
我们尝试一下index only scans的效果:
akendb=# set enable_seqscan=off;set enable_bitmapscan = off;set enable_tidscan = off;explain (analyze,buffers,verbose) select count(*) from aken01;SETSETSETQUERY PLAN --------------------------------------------------------------------------------------------------------------------------------------------------------------Aggregate (cost=1938751.56..1938751.57 rows=1 width=8) (actual time=27290.551..27290.551 rows=1 loops=1)Output: count(*) Buffers: shared read=651983 I/O Timings: read=1998.864 -> Index Only Scan using aken01_pkey on public.aken01 (cost=0.56..1813751.56 rows=50000000 width=0) (actual time=0.051..18871.965 rows=50000001 loops=1)Output: idHeap Fetches: 50000001 Buffers: shared read=651983 I/O Timings: read=1998.864 Planning time: 0.204 ms Execution time: 27290.601 ms(11 rows)
IO基本在shared buffer,但index only scan比Seq Scan效率更差了,因该idx无vm文件,依旧要做可见性判断。如果是Oracle的同学,通常针对大表的优化,在资源充足的情况,使用分区或并行技术通常会是一个比较有效的方法,这也是AP系统主要的优化手段,这里我们在PostgreSQL开启32个并行:
akendb=# set parallel_tuple_cost =0;SETakendb=# set parallel_tuple_cost =0;SETakendb=# set max_parallel_workers_per_gather =32; SETakendb=# alter table aken01 set (parallel_workers =32);ALTER TABLEakendb=# explain (analyze,buffers,verbose) select count(*) from aken01;QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------------------------ Finalize Aggregate (cost=535899.34..535899.35 rows=1 width=8) (actual time=6150.317..6150.318 rows=1 loops=1)Output: count(*) Buffers: shared hit=155144 read=360224 I/O Timings: read=1641.442 -> Gather (cost=535899.25..535899.26 rows=32 width=8) (actual time=6150.267..6160.640 rows=9 loops=1)Output: (PARTIAL count(*)) Workers Planned: 32 Workers Launched: 8 Buffers: shared hit=155144 read=360224 I/O Timings: read=1641.442 -> Partial Aggregate (cost=534899.25..534899.26 rows=1 width=8) (actual time=6123.835..6123.835 rows=1 loops=9)Output: PARTIAL count(*) Buffers: shared hit=155144 read=360224 I/O Timings: read=1641.442 Worker 0: actual time=6078.874..6078.874 rows=1 loops=1 Buffers: shared hit=17161 read=40125 I/O Timings: read=158.571 Worker 1: actual time=6145.014..6145.014 rows=1 loops=1 Buffers: shared hit=16900 read=39533 I/O Timings: read=177.511 Worker 2: actual time=6145.094..6145.094 rows=1 loops=1 Buffers: shared hit=17266 read=40933 I/O Timings: read=93.361 Worker 3: actual time=6145.392..6145.392 rows=1 loops=1 Buffers: shared hit=17111 read=39107 I/O Timings: read=247.815 Worker 4: actual time=6079.581..6079.582 rows=1 loops=1 Buffers: shared hit=17405 read=39287 I/O Timings: read=90.894 Worker 5: actual time=6145.646..6145.646 rows=1 loops=1 Buffers: shared hit=17199 read=39618 I/O Timings: read=245.592 Worker 6: actual time=6145.679..6145.679 rows=1 loops=1 Buffers: shared hit=17273 read=41417 I/O Timings: read=219.668 Worker 7: actual time=6079.707..6079.707 rows=1 loops=1 Buffers: shared hit=16844 read=40581 I/O Timings: read=159.558 -> Parallel Seq Scan on public.aken01 (cost=0.00..530993.00 rows=1562500 width=0) (actual time=0.032..3845.940 rows=5555556 loops=9) Buffers: shared hit=155144 read=360224 I/O Timings: read=1641.442 Worker 0: actual time=0.032..3666.180 rows=5557782 loops=1 Buffers: shared hit=17161 read=40125 I/O Timings: read=158.571 Worker 1: actual time=0.032..3601.889 rows=5475027 loops=1 Buffers: shared hit=16900 read=39533 I/O Timings: read=177.511 Worker 2: actual time=0.031..4047.629 rows=5646302 loops=1 Buffers: shared hit=17266 read=40933 I/O Timings: read=93.361 Worker 3: actual time=0.041..3998.200 rows=5454196 loops=1 Buffers: shared hit=17111 read=39107 I/O Timings: read=247.815 Worker 4: actual time=0.040..3864.664 rows=5500164 loops=1 Buffers: shared hit=17405 read=39287 I/O Timings: read=90.894 Worker 5: actual time=0.034..3586.671 rows=5512289 loops=1 Buffers: shared hit=17199 read=39618 I/O Timings: read=245.592 Worker 6: actual time=0.027..3921.528 rows=5693970 loops=1 Buffers: shared hit=17273 read=41417 I/O Timings: read=219.668 Worker 7: actual time=0.026..4269.655 rows=5571265 loops=1 Buffers: shared hit=16844 read=40581 I/O Timings: read=159.558 Planning time: 0.191 ms Execution time: 6160.723 ms(67 rows)akendb=#akendb=#select count(*) from aken01;count----------50000001(1 row)Time: 4447.033 ms (00:04.447)akendb=#
使用并行本质上是通过资源消耗替代时间消耗,在资源充足的情况下对SQL性能能起到提升作用,但资源不充足情况下,过大的并行度会加剧CPU的消耗,SQL效率则有可能变得更差。
附加:
查询不走索引的情况:
1、条件字段选择性弱,查出的结果集较大,不走索引;
查询结果集占数据行比例对执行计划的影响没有明确的数据界限,可能的比例界限在2%-3%之间
2、where条件等号两边字段类型不同,不走索引;(pg不受影响)
3、索引字段 is null 不走索引;
4、对于count(*)当索引字段有not null约束时走索引,否则不走索引;
5、like 后面的字符当首位为通配符时不走索引;
6、使用不等于操作符如:<>、!= 等不走索引;
7、索引字段前加了函数或参加了运算不走索引;
8,部分索引但查询条件包括不属于部分索引的数据
9、where条件中有or,且or条件两边字段不是都有索引
如果where条件都没有以上所述,那么考虑优化器分析的统计信息陈旧,需要更新这个表的统计信息或者重建索引
————————————————
版权声明:本文为CSDN博主「大妮哟」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44847119/article/details/120187409