RocketMQ的消费方式包含Pull和Push两种
-
Pull方式:用户主动Pull消息,自主管理位点,可以灵活地掌控消费进度和消费速度,适合流计算、消费特别耗时等特殊的消费场景。缺点也显而易见,需要从代码层面精准地控制消费,对开发人员有一定要求。 在 RocketMQ 中org.apache.rocketmq.client.consumer.DefaultMQPullConsumer 是默认的Pull消费者实现类。
-
Push 方式:代码接入非常简单,适合大部分业务场景。缺点是灵活度差,在了解其消费原理后,排查消费问题方可简单快捷。在RocketMQ 中org.apache.rocketmq.client.consumer.DefaultMQPushConsumer 是默认的Push消费者实现类
| 消费方式/对比项 | Pull | Push | 备注 |
|---|---|---|---|
| 是否需要主动拉取 | 理解分区后,需要主动拉取各个分区消息 | 自动 | Pull 消息灵活;Push 使用更简单 |
| 位点管理 | 用户自行管理或者主动提交给 Broker 管理 | Broker 管理 | Pull自主管理位点,消费灵活; Push 位点交由 Broker 管理 |
| Topic 路由变更是否影响消费 | 否 | 否 | Pull模式需要编码实现路由感知 Push 模式自动执行 Rebalance,以适应路由变更 |
Pull消费流程
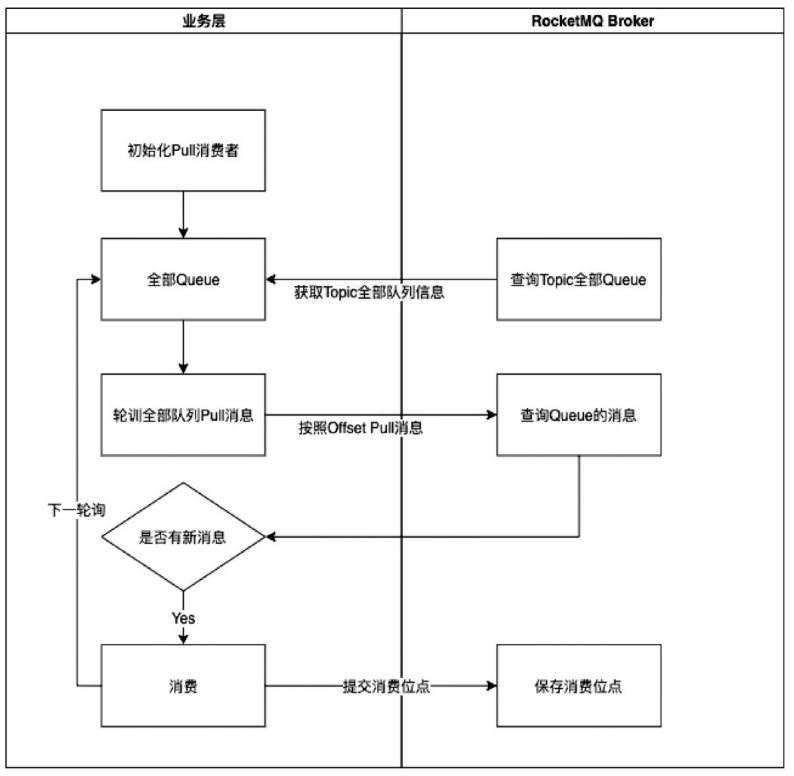
第一步: fetchSubscribeMessageQueues(StringTopic)。拉取全部可以消费的Queue。如果某一个Broker下线,这里也可以实时感知到。
第二步: 遍历全部Queue,拉取每个Queue可以消费的消息。
第三步: 如果拉取到消息,则执行用户编写的消费代码。
第四步: 保存消费进度。消费进度可以执行updateConsumeOffset()方法,将消费位点上报给Broker,也可以自行保存消费位点。比如流计算平台Flink使用Pull方式拉取消息消费,通过Checkpoint管理消费进度
Push消费流程
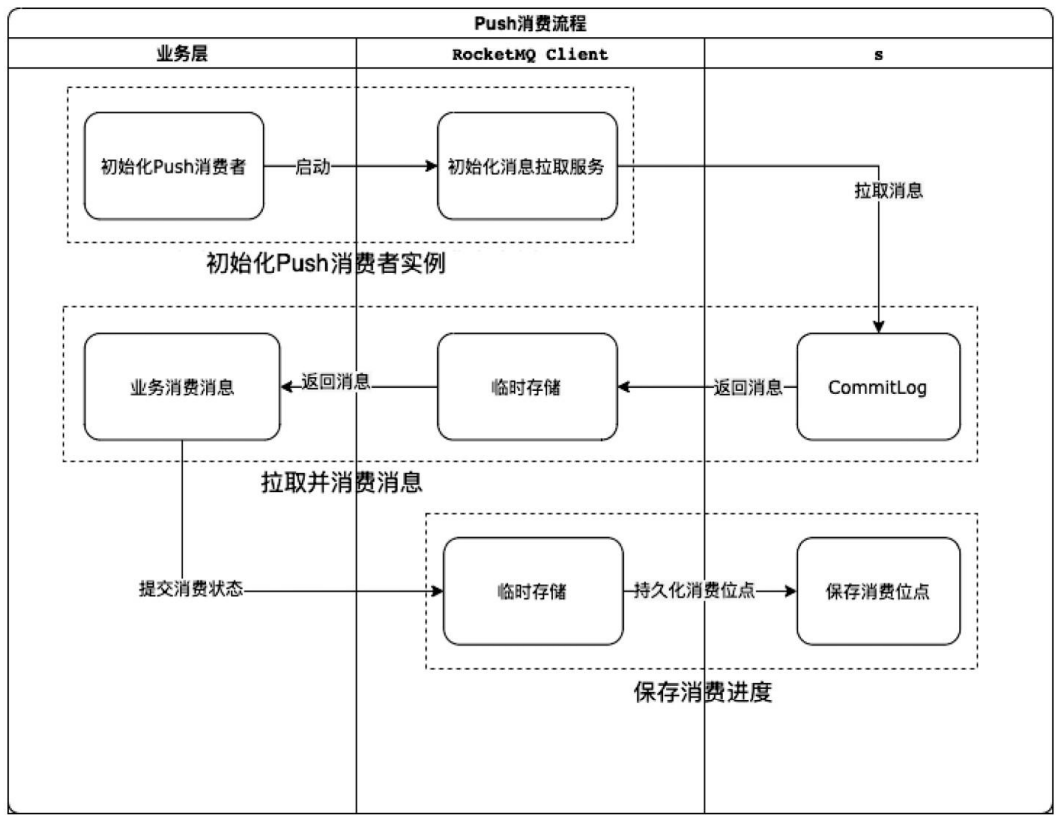
第一步: 初始化Push消费者实例。业务代码初始化DefaultMQPushConsumer实例,启动Pull服务PullMessageService。该服务是一个线程服务,不断执行run()方法拉取已经订阅Topic的全部队列的消息,将消息保存在本地的缓存队列中。
第二步: 消费消息。由消费服务ConsumeMessageConcurrentlyService或者ConsumeMessageOrderlyService将本地缓存队列中的消息不断放入消费线程池,异步回调业务消费代码,此时业务代码可以消费消息。
第三步: 保存消费进度。业务代码消费后,将消费结果返回给消费服务,再由消费服务将消费进度保存在本地,由消费进度管理服务定时和不定时地持久化到本地(LocalFileOffsetStore支持)或者远程Broker(RemoteBrokerOffsetStore支持)中。对于消费失败的消息,RocketMQ客户端处理后发回给Broker,并告知消费失败
Push消费者如何拉取消息消费
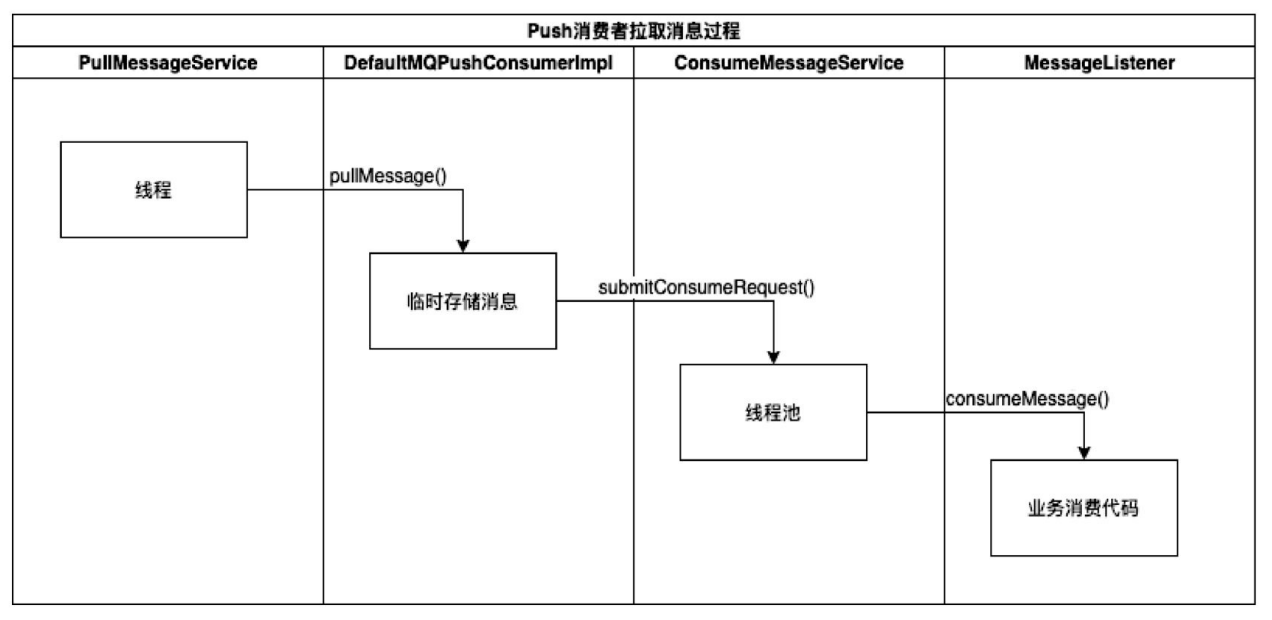
第一步:PullMessageService 不断拉取消息。如下源代码是PullMessageService.run()方法,pullRequestQueue 中保存着待拉取的 Topic 和 Queue 信息,程序不断从pullRequestQueue中获取PullRequest并执行拉取消息方法。
第二步:消费者拉取消息并消费
(1)基本校验。校验ProcessQueue是否dropped;校验消费者服务状态是否正常;校验消费者是否被挂起。
(2)拉取条数、字节数限制检查。如果本地缓存消息数量大于配置的最大拉取条数(默认为1000,可以调整),则延迟一段时间再拉取;如果本地缓存消息字节数大于配置的最大缓存字节数,则延迟一段时间再拉取。这两种校验方式都相当于本地流控
(3)并发消费和顺序消费校验,在并发消费时,processQueue.getMaxSpan()方法是用于计算本地缓存队列中第一个消息和最后一个消息的offset差值
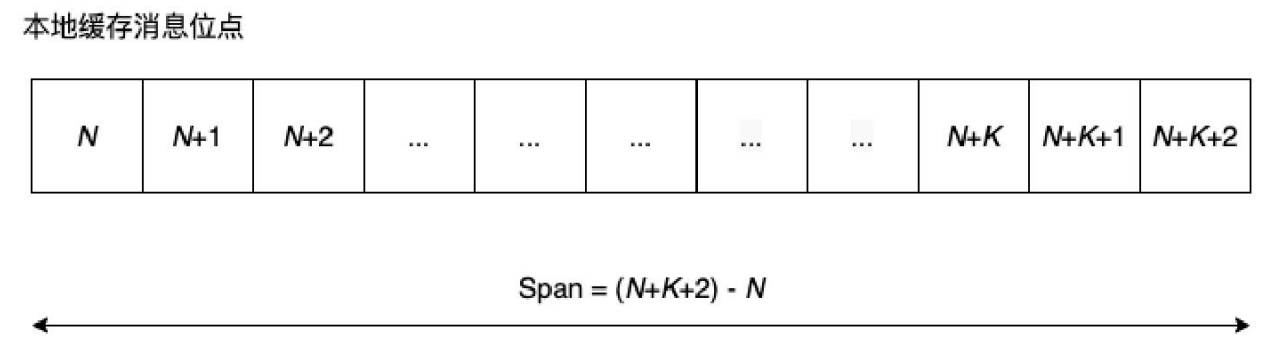
本地缓存队列的Span如果大于配置的最大差值(默认为2000,可以调整),则认为本地消费过慢,需要执行本地流控
顺序消费时,如果当前拉取的队列在 Broker 端没有被锁定,说明已经有拉取正在执行,当前拉取请求晚点执行;如果不是第一次拉取,需要先计算最新的拉取位点并修正本地最新的待拉取位点信息,再执行拉取
(1)订阅关系校验。如果待拉取的Topic在本地缓存中订阅关系为空,则本地拉取不执行,待下一个正常心跳或者Rebalance后订阅关系恢复正常,方可正常拉取。
(2)封装拉取请求和拉取后的回调对象 PullCallback。这里主要将消息拉取请求和拉取结果处理封装成 PullCallback,并通过调用PullAPIWrapper.pullKernelImpl()方法将拉取请求发出去
ConsumeMessageService 是一个通用消费服务接口
public interface ConsumeMessageService {
/**
* 启动服务时使用
*/
void start();
/**
* 关闭服务时使用
* @param awaitTerminateMillis
*/
void shutdown(long awaitTerminateMillis);
/**
* 更新消费线程池的核心线程数。
* @param corePoolSize
*/
void updateCorePoolSize(int corePoolSize);
/**
* 增加一个消费线程池的核心线程数。
*/
void incCorePoolSize();
/**
* 减少一个消费线程池的核心线程数
*/
void decCorePoolSize();
/**
* 获取消费线程池的核心线程数
* @return
*/
int getCorePoolSize();
/**
* 如果一个消息已经被消费过了,但是还想再消费一次,就需要实现这个方法
* @param msg
* @param brokerName
* @return
*/
ConsumeMessageDirectlyResult consumeMessageDirectly(final MessageExt msg, final String brokerName);
/**
* 将消息封装成线程池任务,提交给消费服务,消费服务再将消息传递给业务消费进行处理
* @param msgs
* @param processQueue
* @param messageQueue
* @param dispathToConsume
*/
void submitConsumeRequest(
final List<MessageExt> msgs,
final ProcessQueue processQueue,
final MessageQueue messageQueue,
final boolean dispathToConsume);
}
消费消息主要分为消费前预处理、消费回调、消费结果统计、消费结果处理4个步骤
第一步:消费执行前进行预处理。执行消费前的hook和重试消息预处理。消费前的hook可以理解为消费前的消息预处理(比如消息格式校验)。如果拉取的消息来自重试队列,则将Topic名重置为原来的Topic名,而不用重试Topic名。
第二步:消费回调。首先设置消息开始消费时间为当前时间,再将消息列表转为不可修改的List,然后通过listener.consumeMessage(Collections.unmodifiableList(msgs),context)方法将消息传递给用户编写的业务消费代码进行处理。
第三步:消费结果统计和执行消费后的hook。客户端原生支持基本消费指标统计,比如消费耗时;消费后的hook和消费前的hook要一一对应,用户可以用消费后的hook统计与自身业务相关的指标。
第四步:消费结果处理。包含消费指标统计、消费重试处理和消费位点处理。消费指标主要是对消费成功和失败的TPS的统计;消费重试处理主要将消费重试次数加1;消费位点处理主要根据消费结果更新消费位点记录
顺序消息的 ConsumeRequest 中并没有保存需要消费的消息,在顺序消费时通过调用ProcessQueue.takeMessags()方法获取需要消费的消息,而且消费也是同步进行的
msgTreeMap:是一个TreeMap<Long,MessageExt>类型,key是消息物理位点值,value是消息对象,该容器是ProcessQueue用来缓存本地顺序消息的,保存的数据是按照key(就是物理位点值)顺序排列的。
consumingMsgOrderlyTreeMap:是一个TreeMap<Long,MessageExt>类型,key是消息物理位点值,Value是消息对象,保存当前正在处理的顺序消息集合,是msgTreeMap的一个子集。保存的数据是按照key(就是物理位点值)顺序排列的。
batchSize:一次从本地缓存中获取多少条消息回调给用户消费