背景
背景:在实际使用中,尤其并发场景,想要保持原子性如果是使用redis,可以使用lua脚本来保证原子性。截止目前redis版本已经提供了大概有1000多个命令,但是在某些场景,想要实现某些指令原子性实现时,需要扩充进行使用,原生命令无法实现,所以自从Redis 2.6版本引入了lua脚本
Redis允许用户在服务器上上传和执行lua脚本,脚本可以使用编程,并在执行时使用大多数命令来操作数据库,由于脚本在服务器中执行,因此脚本的读取和写入数据非常高效,
任何事物,都有好有坏,我们要做的只是权衡利弊
使用lua脚本的好处:
1、原子操作,一个lua脚本被当作一个整体执行,中途不会被打断,也不会有其他命令干扰插入,正式因为这种原子性,lua脚本可以代替multi和exec的事务功能
2、减少网络开销,可以将多个请求的操作写为一个脚本,有效减少客户端请求数量
3、复用,lua脚本可以一直缓存在redis服务器当作,在使用的时候,可以直接拿来复用,
LUA
lua是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放,其目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制能力
菜鸟教程目前Redis支持单个脚本引擎,Lua5.1解释器
命令
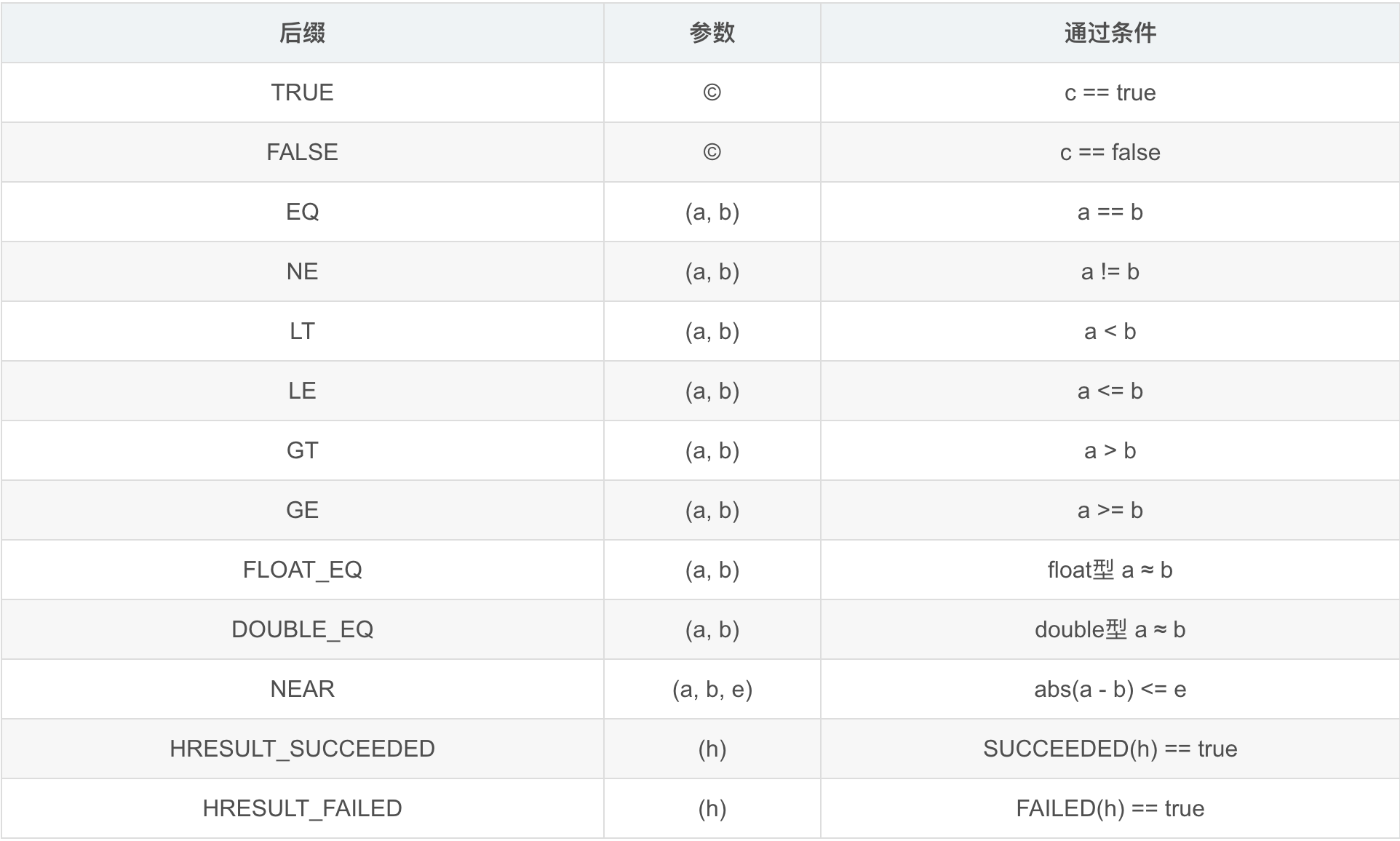
EVAL
EVAL script numbers [key [key ...]] [arg [arg ...]]
redis2.6.0开始提供eval命令,用于执行lua脚本,script为脚本内容,key为需要操作的key值,arg为脚本运行时传入的参数,其中key 和 arg均在后面,混为一谈,区分不了key和arg在哪个地方分割,所以numbers表示key的数量

eval "return {KEYS[1], KEYS[2], ARGV[1], ARGV[2]}" 2 key1 key2 argv1 argv2
这里如果key、arg特别多不容易区分,偷懒写法为number为0,不管脚本的key或者arg全写为arg

丝毫不影响运行,但是为了规范起见还是将key和arg使用参数进行区分,另外KEYS、ARGS大小写敏感,需要全部大写
在lua脚本中,可以使用两个不同的函数来操作redis,可以通过redis.call或redis.pcall()从Lua脚本调用redis命令
两者几乎相同,都执行redis命令及其提供的参数,唯一区别在于执行redis.call()命令时直接将错误返回给客户端,而调用redis.pcall()函数时遇到的错误返回一个带 err 域的 Lua 表(table),用于表示错误

当遇到稍微复杂一点的脚本时,每当我们调用EVAL时,我们也会将脚本包含在请求中,反复调用相同的参数脚本,既浪费了网络带宽,参数编译也在redis中有一些开销,因此,redis提供了缓存机制。
脚本应当尽可能通用,尽量通过参数来传递变量,我们执行的EVAL每个脚本都存储在服务器保存的专用缓存当中,缓存的内容由sha1算法加密,因为涉及缓存,尽量保持脚本的通用性的原因是,在服务器执行脚本时,会先通过sha1摘要和脚本内容进行缓存
SCRIPT LOAD script
将脚本加载到服务器缓存当中,而不执行它,脚本缓存会一直存在,除非手动使用(SCRIPT FLUSH命令进行清除),返回值为SHA1加密值

EVALSHA sha1 numkeys [key [key ...]] [arg [arg ...]]
语法同eval基本类似,只是将script换成通过scripr load加载到的缓存的值

前面说到的lua脚本缓存性,可以将脚本一直缓存在服务器中,
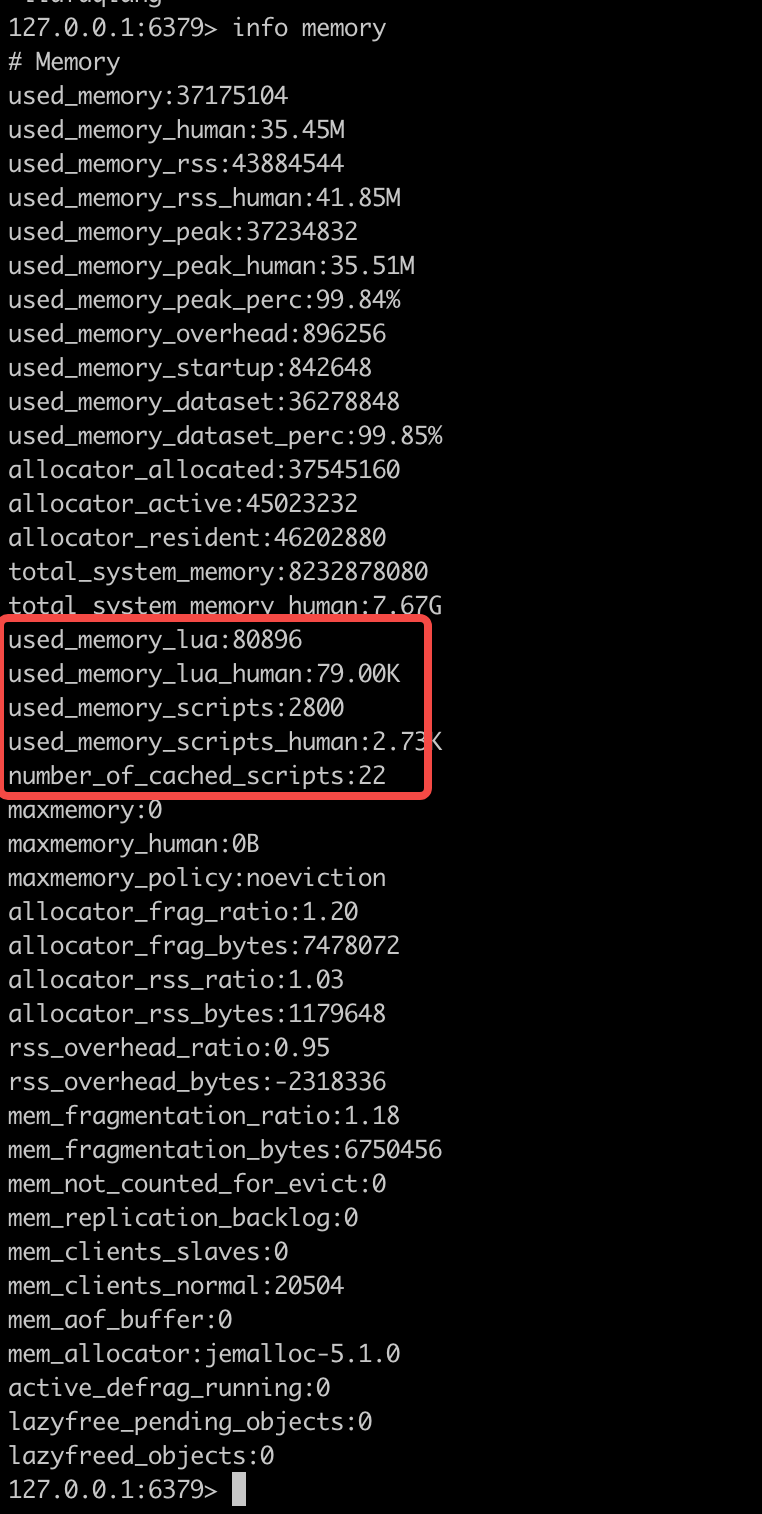
因为上一步我们执行过 script load "return redis.call('set', KEYS[1], ARGV[1])",当我们再次执行这个命令时,会发现这两个值没有丝毫变化,这是因为redis服务端已经将这个脚本进行了缓存,下一次执行相同的脚本时直接从缓存当中取,当我们执行一个没有执行过的脚本
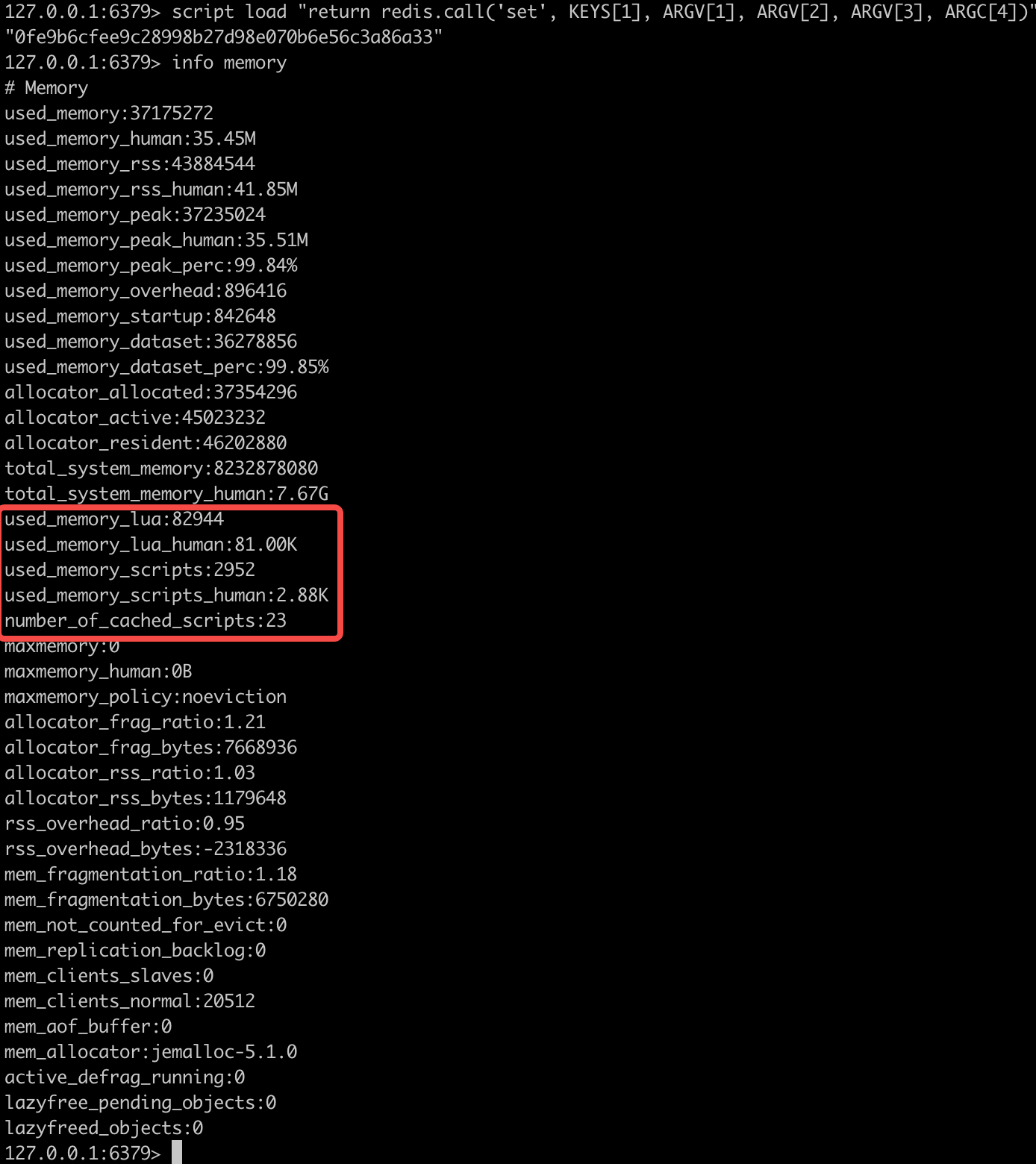
会发现这两个值会随着每个执行的新脚本而增长,所以我们尽量使用通用脚本,少使用动态生成的脚本
Reds脚本也并不是一直在缓存当中的,它不会被当作数据库的一部分,也不会持久化,当redis服务被重启时,在集群环境时,遇到故障切换到副本时,缓存可能会被清除,或者人为的调用script flush命令清除掉了,意味着缓存的脚本丢失了,
SCRIPT FLUSH [ASYNC | SYNC]
同步/异步清除脚本
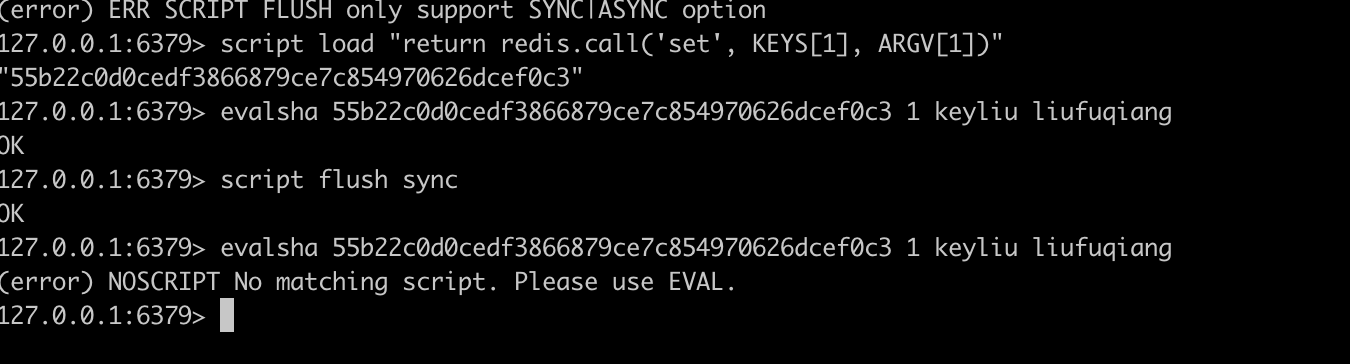
会发现脚本没有了,让我们使用eval来进行执行脚本
在这种情况下常理来说应该先判断是否存在sha1,存在则执行evalsha,如果不存在则script load加载到缓存中,再执行evalsha
SCRIPT EXISTS sha1 [sha1 ...]
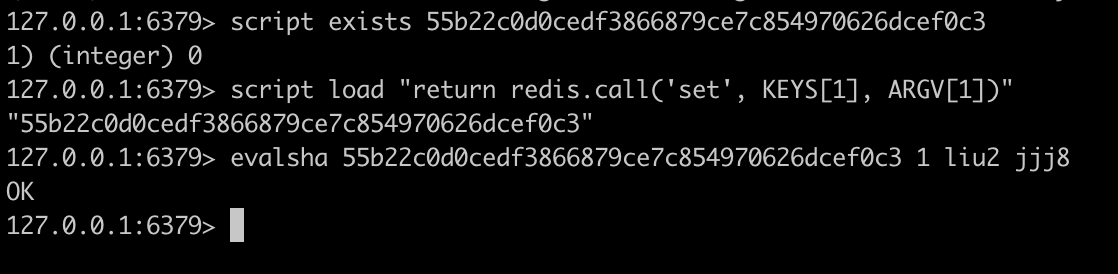
这样操作可以保证脚本的存在性,不存在则加载一次,存在则返回1,否则返回0
示例:
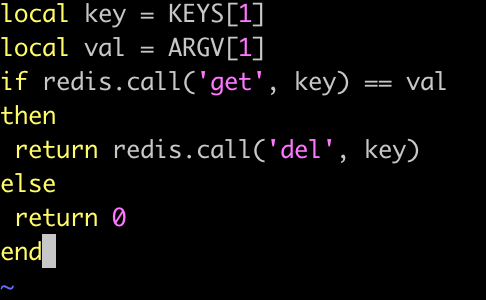
比如常用的释放锁的脚本:
local key = KEYS[1]
local val = redis.call('get', key)
if val == ARGV[1]
then
return redis.call('del', key)
else
return 0
end
redis-cli执行脚本
我们调试的时候也可以将脚本写入文件,利用redis-cli执行脚本
可以看到只有两个参数值,一个是key,一个是value,
redis-cli --eval Lua脚本路径 key [key …] , arg [arg …]
注意这里没有像eval命令一样有numbers key的数量, 而是在key和value之间用英文逗号分隔,\(\color{red}{逗号前后必须留有空格,不然部分命令会报错}\)

lua脚本与管道(piple)区别
我们知道,redis的管道也可以一次性执行多条命令,比如以srtingRedisTemplate为例,往list如果不存在则插入元素
String key = "key_pipeline";
String value = "apple";
List<Object> execute = stringRedisTemplate.execute((RedisConnection connection) -> {
Jedis jedis = (Jedis) connection.getNativeConnection();
Pipeline p = jedis.pipelined();
p.lrem(key, 1, value);
p.lpush(key, value);
return p.syncAndReturnAll();
});
System.out.println(JSONUtil.toJsonStr(execute));
最后的执行结果为[0,1]0表示之前没有这个元素,删除掉的元素个数为0,1表示push进入list元素的个数为1。
再比如排行榜的逻辑,有一本书的数据,可能需要刷新好几个排行榜,如果需要更新的榜单较多,不使用管道,来回网络传输所消耗的时间RTT(Round Trip Time),会浪费很长时间,也会浪费资源
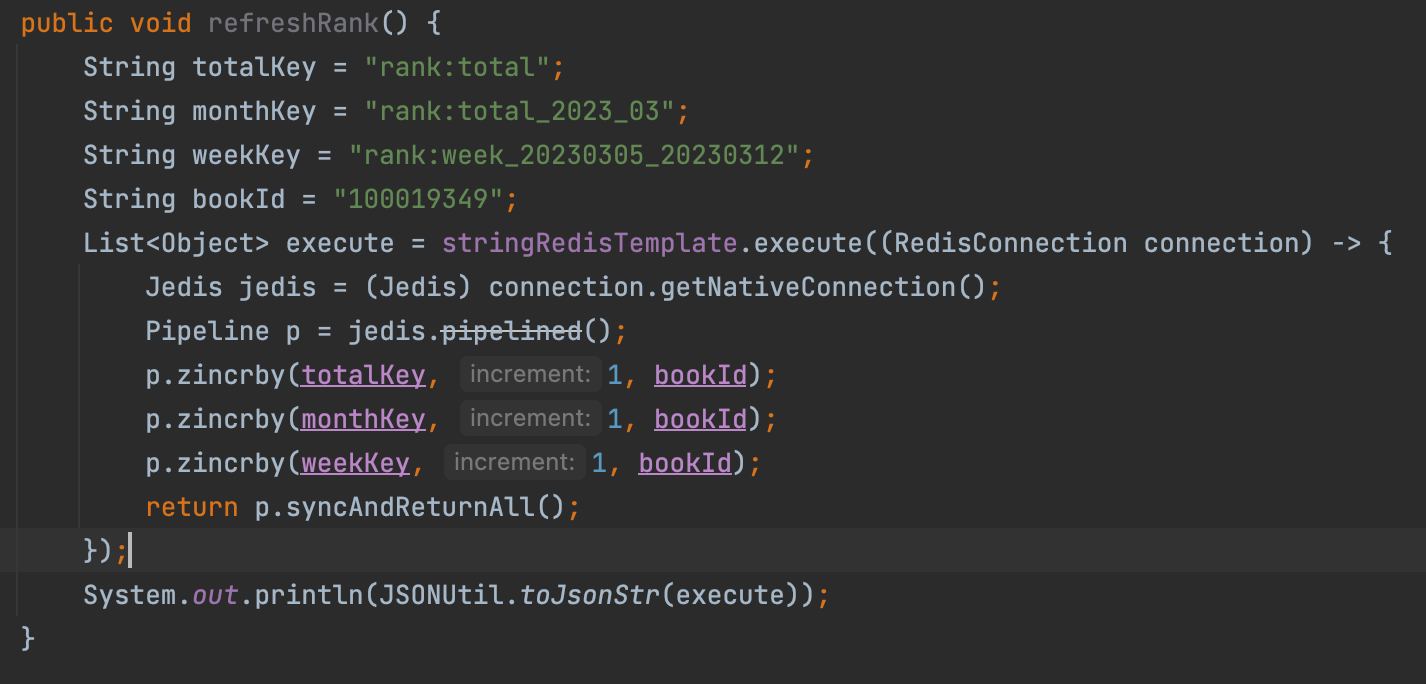
如果不使用管道,如果有连续操作,每次都需要客户端与redis进行连接,并返回结果给客户端。使用了管道之后 客户端一次性发送所有指令,并等待服务端执行完将结果一次性返回,而pipled实现的原理是队列,先进先出,保证了命令的有序性,所以结果也都一一对应。所以管道的使用场景为批量处理,两条命令关联性不是很高,原子性要求不是很高的场景中使用
对于原子性要求不是很高的场景下可以使用管道,比如上面这个排行榜,总榜里面有一本书,但是在月榜里面没有执行成功,这完全没人发现,也不过分
但是对于可靠性特别高的,每次操作都需要立即返回结果的场景就不适合管道,一定意义上来说,redis的管道不具备原子性,只是在批量处理的场景中有优势
lua是将需要执行的多个命令写为一个脚本被当作一整条命令来执行, 因为redis单线程执行的原因,这条命令不受其他影响,要么成功,要么失败。但是我们不应该在lua脚本中写入过于复杂的逻辑, 否则会造成阻塞,因此lua适合相对简单的事务场景
java代码使用lua例子
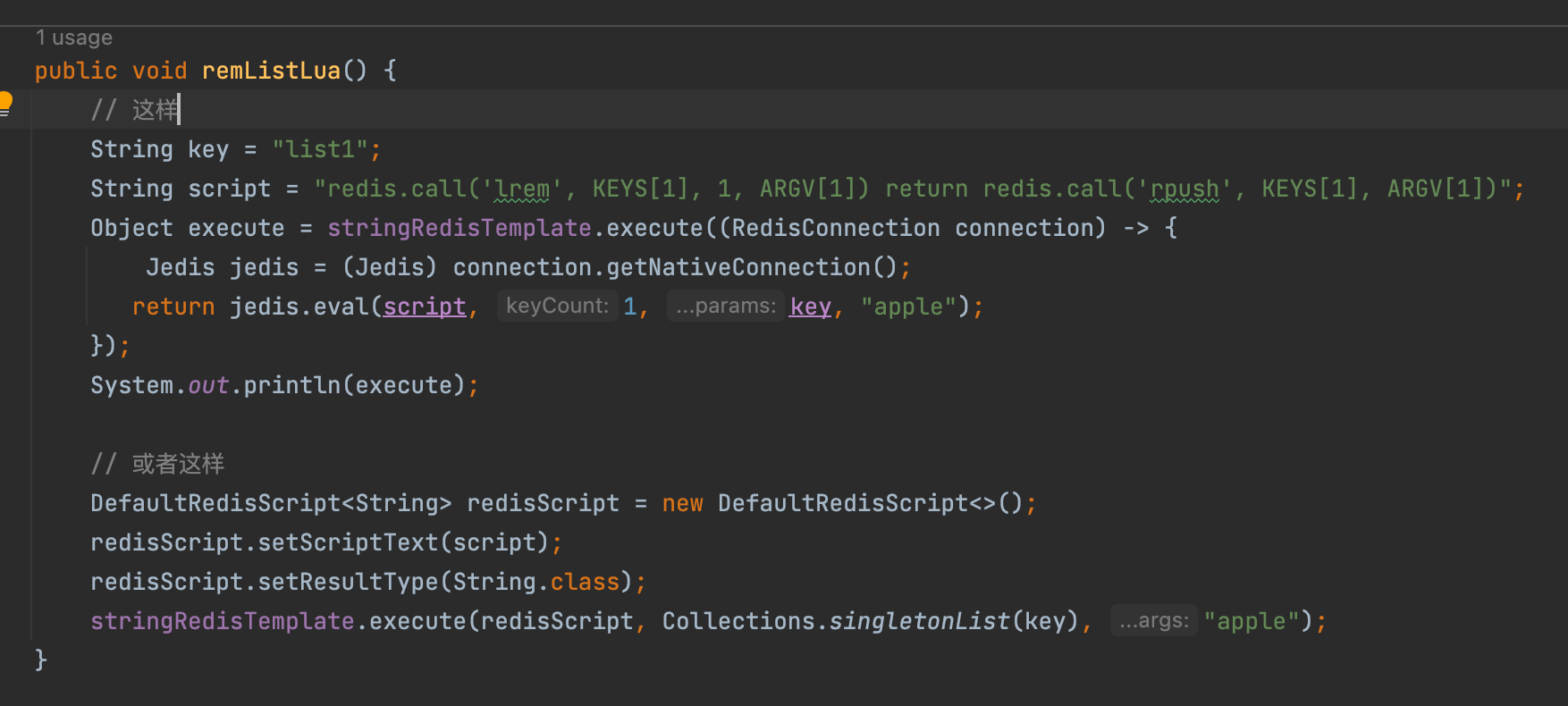
比如这里有个场景使用list,往list当中插入元素时需要判断是否存在这个元素,不存在再插入,需要保证list的元素唯一
在redis的list命令中没有判断list当中是否有某个元素的命令,在6.0.6之后提供了LPOS可以取得这个值对应的索引值,但是低版本还是用不了,所以我用了下面的暴力写法
总结:
redis的lua脚本,在实际开发中用途不是特别多,但是用到了绝对能解决很多并发出现的原子性问题,lua脚本类似于关系数据库的存储过程,虽然功能强大,但是不好维护,
实际使用的时候应该避免脚本参数为用户生成内容UGC生成,这样可能会被黑客植入代码获取到服务器的权限,一般建议redis以普通用户的身份启动