今天尝试爬取新浪微博,但是爬取下来网页的源代码,以html形式打开却发现没有内容,如下图:

我查阅了一些资料,发现微博这种主流网页一般都是动态网页,都普遍采用了ajax加载数据,如果我用传统的爬虫post一个url或请求参过去,那么我接受相应的html代码会没有我想要的数据。
而抓取动态页面有两种常用的方法,一是通过JavaScript逆向工程获取动态数据接口(真实的访问路径),另一种是利用selenium库模拟真实浏览器,获取JavaScript渲染后的内容。
我之后以爬取新浪为例再把实践发表成博客。






猜你喜欢
-
 2023-04-01
2023-04-01【Jenkins系列】-权限管理
-

连载《一个程序猿的生命周期》-《发展篇》- 36.可能再次经历公司“分化”
2023-01-15 -

ASP.NET Core 借助 Helm 部署应用至K8S
2023-01-30 -

-

Cloud集群模式XXL-job开启自动注册执行器
2023-04-28 -
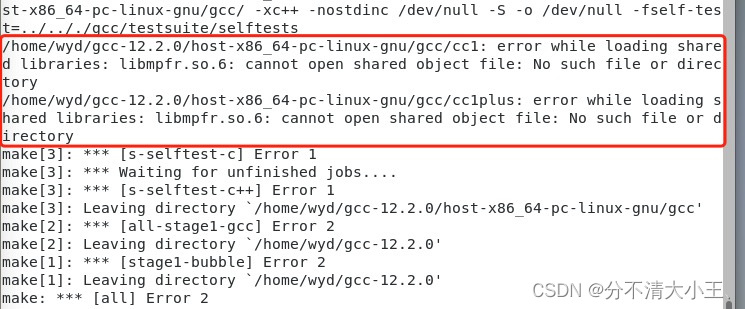
centOS 7安装gcc、g++
2023-04-21 -

离线部署clamAV
2023-09-01 -

12. Kubernetes – ingress-nginx
2023-03-03 -
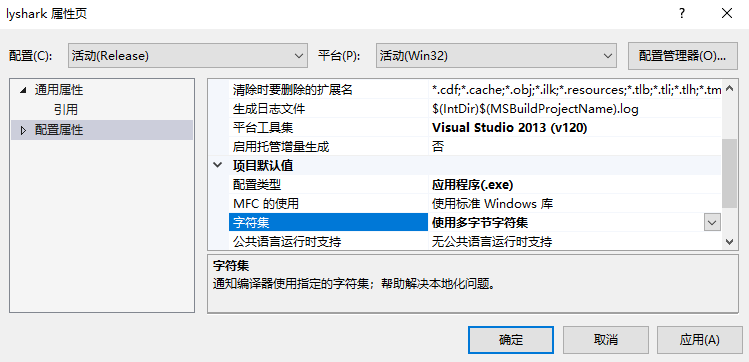
1.4 编写简易ShellCode弹窗
2023-08-28 -
![[MAUI] 在.NET MAUI中结合Vue实现混合开发](https://img2020.cnblogs.com/blog/644861/202201/644861-20220115101644699-398025165.gif)
[MAUI] 在.NET MAUI中结合Vue实现混合开发
2023-02-27









