全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
示例 2:
输入:nums = [0,1]
输出:[[0,1],[1,0]]
示例 3:
输入:nums = [1]
输出:[[1]]
思路
咋一看好像还可以用之前的套路
只要判断一下当前遍历值是否有使用过,有就跳过即可
但是这个“跳过”的操作如果还是使用beginIndex的话就会出错
一种经典的错误思路是:仍然使用beginIndex作为遍历时的起始值,当每次调用递归时就使用 当前位置+1 作为下次遍历的beginIndex
这样做的话最后只能得到一条路径上的结果,因为我们没办法即根据beginIndex去回溯又将beginIndex作为for循环的依据(递归可以回溯,for循环过了的东西是回不去的)
因此这里需要用used数组来记录当前遍历值是否出现过,如果出现过就直接跳过
停止条件也不太一样,因为我们又是需要找出所有的结果,所以实际上这里还是不需要停止条件的,不过我们需要在path数组保存到足够大小的排列值时将其保存至res结果数组
代码
代码比较套路就直接贴了
class Solution {
private:
vector<vector<int>> res;
vector<int> path;
void backtracking(vector<int>& nums, vector<bool>& used){
//确定终止条件,无
if(path.size() == nums.size()){//当path保存到足够的元素时,将其存至res
res.push_back(path);
return;
}
//确定单层处理逻辑
for(int i = 0; i < nums.size(); ++i){
//判断当前元素是否被使用过
if(used[i] == true) continue;
used[i] = true;//记录当前值
path.push_back(nums[i]);
backtracking(nums, used);
path.pop_back();//回溯
used[i] = false;
}
}
public:
vector<vector<int>> permute(vector<int>& nums) {
vector<bool> used(nums.size(), false);
backtracking(nums, used);
return res;
}
};
全排列II
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 1:
输入:nums = [1,1,2]
输出:
[[1,1,2],
[1,2,1],
[2,1,1]]
示例 2:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
思路
与第一题不同之处是题目给的nums中多了重复值
将例1的结果画出示例图如下:
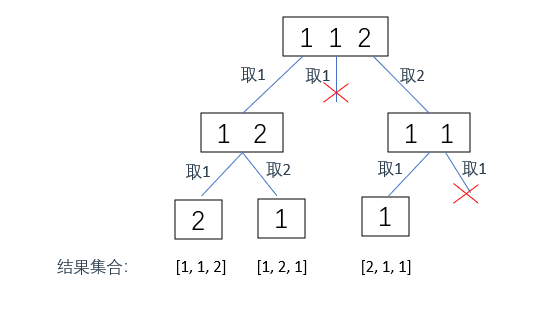
因此还需要在同层中去重,参考之前的去重操作即可(子集、组合总和II)
这里也需要在使用nums之前进行排序
代码分析
还是按规矩来写一遍
1、确定回溯函数的参数与返回值
跟上一题一样,不需要beginIndex,只需要used数组进行记录即可
class Solution {
private:
vector<vector<int>> res;
vector<int> path;
//确定回溯函数的参数与返回值
void backtracking(vector<int>& nums, vector<bool>& used){
}
public:
vector<vector<int>> permuteUnique(vector<int>& nums) {
}
};
2、确定终止条件
还是跟上一题一样
class Solution {
private:
vector<vector<int>> res;
vector<int> path;
//确定回溯函数的参数与返回值
void backtracking(vector<int>& nums, vector<bool>& used){
//确定终止条件,无
if(path.size() == nums.size()){//当path保存到足够的元素时,将其存至res
res.push_back(path);//此时说明找到了一组
return;
}
}
public:
vector<vector<int>> permuteUnique(vector<int>& nums) {
}
};
3、确定单层处理逻辑
在这里需要处理重复值
注意,我们需要处理的重复情况有两种:
1、相邻重复值(这个很熟了,见过蛮多次的)
2、单纯的nums里出现多次的值,例如:[1,2,8,2,4],这个2就属于此类重复值
class Solution {
private:
vector<vector<int>> res;
vector<int> path;
//确定回溯函数的参数与返回值
void backtracking(vector<int>& nums, vector<bool>& used){
//确定终止条件,无
if(path.size() == nums.size()){//当path保存到足够的元素时,将其存至res
res.push_back(path);//此时说明找到了一组
return;
}
//确定单层处理逻辑
for(int i = 0; i < nums.size(); ++i){
if(i > 0 && nums[i] < nums[i - 1] && used[i - 1] == 0){
continue;//当前元素重复,跳过
}
used[i] = 1;
path.push_back(nums[i]);
backtracking(nums, used);
path.pop_back();
used[i] = 0;
}
}
public:
vector<vector<int>> permuteUnique(vector<int>& nums) {
//先对nums进行排序
sort(nums.begin(), nums.end());
vector<bool> use(nums.size(), false);
backtracking(nums, used);
return res;
}
};
完整代码
在主函数中,需要对使用的nums数组先进行排序
class Solution {
private:
vector<vector<int>> res;
vector<int> path;
//确定回溯函数的参数与返回值
void backtracking(vector<int>& nums, vector<bool>& used){
//确定终止条件,无
if(path.size() == nums.size()){//当path保存到足够的元素时,将其存至res
res.push_back(path);//此时说明找到了一组
return;
}
//确定单层处理逻辑
for(int i = 0; i < nums.size(); ++i){
// used[i - 1] == true,说明同一树枝nums[i - 1]使用过
// used[i - 1] == false,说明同一树层nums[i - 1]使用过
// 如果同一树层nums[i - 1]使用过则直接跳过
if(i > 0 && nums[i] == nums[i - 1] && used[i - 1] == 0){
//找出相邻重复值
continue;//当前元素重复,跳过
}
//判断当前元素(非相邻重复值)是否被使用过
if(used[i] == true) continue;
used[i] = 1;
path.push_back(nums[i]);
backtracking(nums, used);
path.pop_back();
used[i] = 0;
}
}
public:
vector<vector<int>> permuteUnique(vector<int>& nums) {
//先对nums进行排序
sort(nums.begin(), nums.end());
vector<bool> used(nums.size(), false);
backtracking(nums, used);
return res;
}
};