静态链接详解
现在对ELF可重定位文件的整体轮廓和某些局部细节都有了一定了解。那么对于两个可重定位文件,如何将其链接起来形成可执行文件呢!
以如下两个文件为例:
/* main.c */
#include<stdio.h>
extern int shared;
int main()
{
int solo=100;
swap(&solo,&shared);
printf("solo=%d,shared=%d",solo,shared);
return 0;
}
/* swap.c */
int shared=200;
void swap(int *a,int *b)
{
int tmp=*a;
*a=*b;
*b=tmp;
}
相关指令:
gcc main.c swap.c -o test
或者
gcc main.c swap.c -c
gcc main.o swap.o -o test
链接方式
按序叠加
一个简单的方案是将输入的可重定向文件按照次序叠加起来。
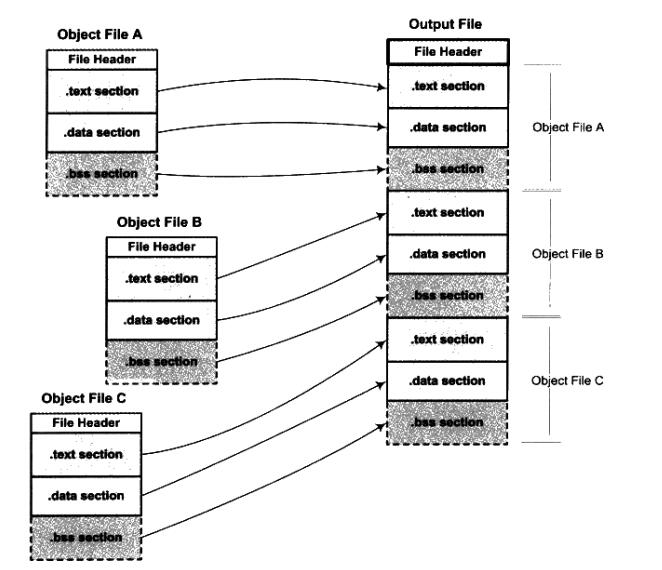
这种方案非常浪费空间,并不适用。
相似段合并
这种方案是将相同性质的段合并到一起。
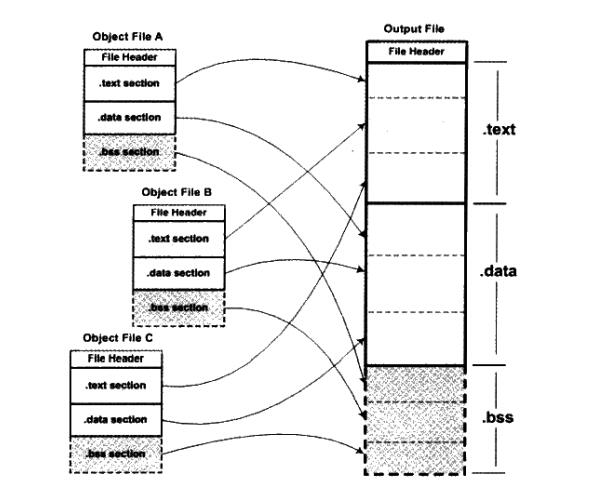
空间与地址分配
显然,上面两种可重定向文件合并都不可避免的涉及到了空间和地址的分配。
这里的地址和空间有两个含义:
- 输出的可执行文件的空间
- 装载后的虚拟地址中的虚拟地址空间
链接过程
现在的链接器空间分配策略基本都采用相似段合并的方式,整个链接过程分两步:
-
空间与地址分配:
扫描所有的输入目标文件, 并且获得它们的各个段的长度、属性和位置,并且将输入目标文件中的符号表中所有的符号定义和符号引用收集起来,统—放到一个全局符号表。这一步中,链接器将能够获得所有输入可重定向文件的段长度, 并且将它们合并, 计算出输出文件中各个段合并后的长度与位置, 并建立映射关系。
-
符号解析与重定位:
使用上面第一步中收集到的所有信息, 读取输入文件中段的数据、 重定位信息, 并且进行符号解析与重定位、 调整代码中的地址等。这一步是链接过程的核心, 特别是重定位过程。
 |
|---|
 |
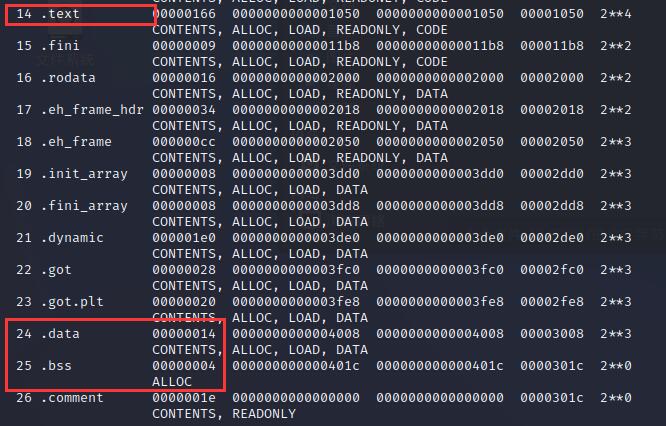 |
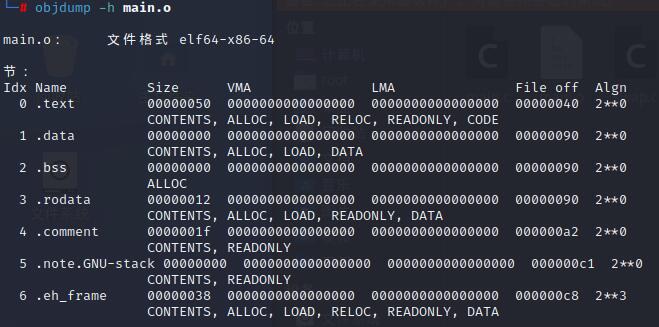
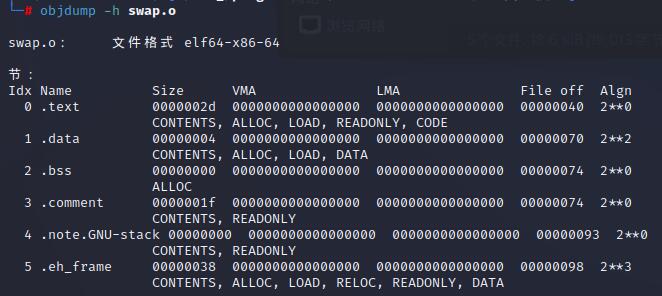
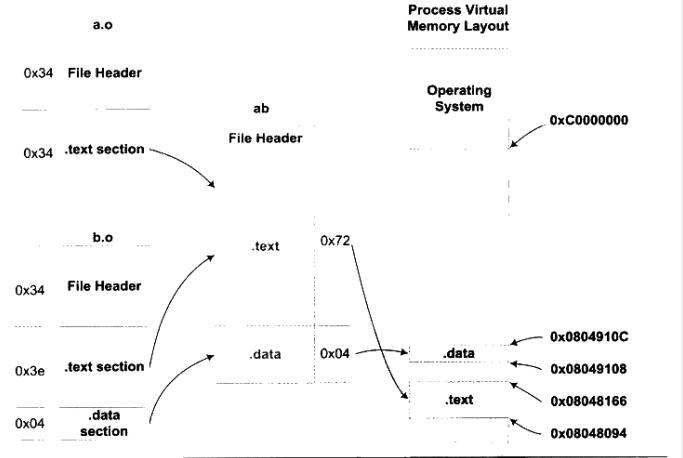
注:VMA【Virtual Memory Address】,即虚拟地址。LMA【Load Memory Address】,即加载地址。正常情况下这两个值是一样的。
链接前后的程序中所使用的地址已经是程序在进程中的虚拟地址,即上面各段中的VMA (Virtual Memory Address)和Size,而忽略文件偏移(File off)。可以看到,在链接之前,目标文件中的所有段的VMA都是0,因为虚拟空间还没有被分配,所以都默认为0。在链接之后,可执行文件"test"中各个段都被分配了相应的虚拟地址。
整个链接过程前后,可重定向文件各段的分配、虚拟地址如下:
【注:图并未和上面的截图对应,贴上只为更好理解合并过程】
符号解析与重定位
汇编简单分析
首先我们分析一下"main.o"是如何使用"shared"变量和"swap"函数的。
#objdump -d main.o
main.o: 文件格式 elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp # 前3条指令开辟大小为0x10的栈空间
8: c7 45 fc 64 00 00 00 movl $0x64,-0x4(%rbp) # 局部变量solo=100
f: 48 8d 45 fc lea -0x4(%rbp),%rax
13: 48 8d 15 00 00 00 00 lea 0x0(%rip),%rdx # 1a <main+0x1a>,由于shared地址未知,用0替代
1a: 48 89 d6 mov %rdx,%rsi
1d: 48 89 c7 mov %rax,%rdi # 上面四条指令,将solo和shared的地址分别存入rdi,rsi
20: b8 00 00 00 00 mov $0x0,%eax
25: e8 00 00 00 00 call 2a <main+0x2a> # swap函数地址也用0替代了
2a: 8b 15 00 00 00 00 mov 0x0(%rip),%edx # 30 <main+0x30>
30: 8b 45 fc mov -0x4(%rbp),%eax
33: 89 c6 mov %eax,%esi
35: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 3c <main+0x3c>
3c: 48 89 c7 mov %rax,%rdi
3f: b8 00 00 00 00 mov $0x0,%eax
44: e8 00 00 00 00 call 49 <main+0x49>
49: b8 00 00 00 00 mov $0x0,%eax
4e: c9 leave
4f: c3 ret
通过上面的分析,我们可以知道,由于shared变量、swap函数地址暂时不知道,因而都暂时用0替代了。
那么我们现在分析"test"可执行程序的汇编代码。
0000000000001139 <main>:
1139: 55 push %rbp
113a: 48 89 e5 mov %rsp,%rbp
113d: 48 83 ec 10 sub $0x10,%rsp
1141: c7 45 fc 64 00 00 00 movl $0x64,-0x4(%rbp)
1148: 48 8d 45 fc lea -0x4(%rbp),%rax
114c: 48 8d 15 c5 2e 00 00 lea 0x2ec5(%rip),%rdx # 4018 <shared>
1153: 48 89 d6 mov %rdx,%rsi
1156: 48 89 c7 mov %rax,%rdi
1159: b8 00 00 00 00 mov $0x0,%eax
115e: e8 26 00 00 00 call 1189 <swap>
1163: 8b 15 af 2e 00 00 mov 0x2eaf(%rip),%edx # 4018 <shared>
1169: 8b 45 fc mov -0x4(%rbp),%eax
116c: 89 c6 mov %eax,%esi
116e: 48 8d 05 8f 0e 00 00 lea 0xe8f(%rip),%rax # 2004 <_IO_stdin_used+0x4>
1175: 48 89 c7 mov %rax,%rdi
1178: b8 00 00 00 00 mov $0x0,%eax
117d: e8 ae fe ff ff call 1030 <printf@plt>
1182: b8 00 00 00 00 mov $0x0,%eax
1187: c9 leave
1188: c3 ret
0000000000001189 <swap>:
1189: 55 push %rbp
118a: 48 89 e5 mov %rsp,%rbp
118d: 48 89 7d e8 mov %rdi,-0x18(%rbp)
1191: 48 89 75 e0 mov %rsi,-0x20(%rbp)
1195: 48 8b 45 e8 mov -0x18(%rbp),%rax
1199: 8b 00 mov (%rax),%eax
119b: 89 45 fc mov %eax,-0x4(%rbp)
119e: 48 8b 45 e0 mov -0x20(%rbp),%rax
11a2: 8b 10 mov (%rax),%edx
11a4: 48 8b 45 e8 mov -0x18(%rbp),%rax
11a8: 89 10 mov %edx,(%rax)
11aa: 48 8b 45 e0 mov -0x20(%rbp),%rax
11ae: 8b 55 fc mov -0x4(%rbp),%edx
11b1: 89 10 mov %edx,(%rax)
11b3: 90 nop
11b4: 5d pop %rbp
11b5: c3 ret
可以看到main函数的两个重定位入口都已经被修正到正确的位置。
重定位表
# objdump -r main.o
main.o: 文件格式 elf64-x86-64
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
0000000000000016 R_X86_64_PC32 shared-0x0000000000000004
0000000000000026 R_X86_64_PLT32 swap-0x0000000000000004
000000000000002c R_X86_64_PC32 shared-0x0000000000000004
0000000000000038 R_X86_64_PC32 .rodata-0x0000000000000004
0000000000000045 R_X86_64_PLT32 printf-0x0000000000000004
RELOCATION RECORDS FOR [.eh_frame]:
OFFSET TYPE VALUE
0000000000000020 R_X86_64_PC32 .text
链接器就是通过上面的重定位表,确定哪些指令需要被调整。
对于可重定位的 ELF 文件来说, 它必须包含有重定位表, 用来描述如何修改相应的段里的内容。 对于每个要被重定位的 ELF 段都有—个对应的重定位表, 而—个重定位表往往就是 ELF 文件中的一个段, 所以其实重定位表也可以叫重定位段。 比如代码段 “ .text" 如有要被重定位的地方, 那么会有一个相对应叫 “ .rel.text" 的段保存了代码段的重定位表;如果代码段 “ .data” 有要被重定位的地方, 就会有一个相对应叫“ .rel.data” 的段保存了数据段的重定位表。
每个要被重定位的地方叫一个重定位入口( Relocation Entry), 我们可以看到 “ main.o" 里面有五个重定位入口。 重定位入口的偏移 (Offset) 表示该入口在要被重定位的段中的位置,” RELOCATION RECORDS FOR [.text]" 表示这个重定位表是代码段的重定位表, 所以偏移表示代码段中须要被调整的位置。
符号解析
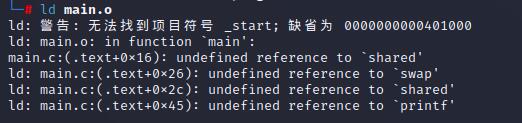
链接时符号未定义是很常见的问题。
导致这个问题的原因很多,最常见的一般都是链接时缺少了某个库,或者输入可重定向文件路径不正确或符号的声明与定义不一样。
因为重定位过程也伴随着符号的解析过程,每个可重定向文件都可能定义一些符号, 也可能引用到定义在其它可重定向文件的符号。重定位的过程中,每个重定位的入口都是对一个符号的引用,那么当链接器需要对某个符号的引用进行重定位时,它就要确定这个符号的目标地址。这时候链接器就会去查找由所有输入可重定向文件的符号表组成的全局符号表,找到相应的符号后进行重定位。
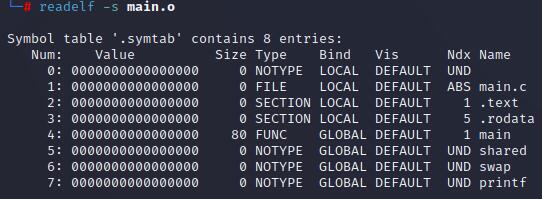
显然main.o中找不到相应符号,这也就导致了链接时符号未定义的问题。
指令具体修正方式

typedef struct
{
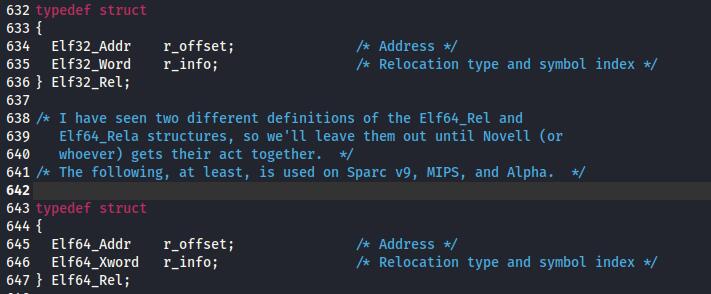
Elf64_Addr r_offset; /* Address */重定位入口的偏移
Elf64_Xword r_info; /* Relocation type and 重定位入口的类型和符号
symbol index */
} Elf64_Rel;
依据重定位表中的r_info,确定重定位修正方法是绝对寻址还是相对寻址。
其中 S、A、P的含义如下:
S = 符号的实际地址,即由r_info的高位指定实际地址【在符号解析时完成】
A = .o文件中被修正位置上的值【如上面提到的shared、swap 的地址暂时用0替代】
P = 被修正的位置【相当于被重定位处的虚拟地址或相对段开始的偏移量,可由r_offset计算得到】
COMMON块
留爪,暂过
静态库链接
静态库可以简单看成一组可重定向文件的集合(即很多可重定向文件经过压缩打包后形成的文件)。【Linux 下的.a 、Windows 下的.lib】
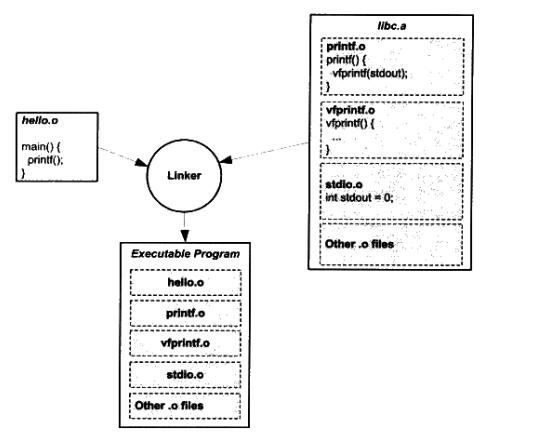
Q:为什么静态运行库里面一个可重定向文件只包含一个函数?
比如libc.a里面printf.o 只有printf()函数、strlen.o只有strlen()函数,为什么要这样组织?
A:我们知道,链接器在链接静态库的时候是以可重定向文件为单位的。比如我们引用了静态库中的printf()函数,那么链接器就会把库中包含printf()函数的那个可重定向文件链接进来, 如果很多函数都放在一个可重定向文件中,很可能很多没用的函数都被一起链接进了输出结果中。由于运行库有成百上千个函数,数量非常庞大,每个函数独立地放在一个可重定向文件中可以尽量减少空间的浪费,那些没有被用到的可重定向文件(函数)就不要链接到最终的输出文件中。
C++ 相关问题
C++的一些语言特性使其必须由编译器和链接器共同支持才能完成工作。最主要的有两个方而, 一个是C++的重复代码消除, 还有一个就是全局构造与析构。 另外由于C++语言的各种特性,比如虚拟函数、函数重载、继承、异常等,使得它背后的数据结构异常复杂, 这些数据结构往往在不同的编译器和链接器之间相互不能通用,使得C++程序的二进制兼容性成了一个很大的问题。
重复代码消除
C++编译器在很多时候会产生重复的代码,比如模板(Templates)、外部内联函数(Extern lnline Function)和虚函数表(VirtualFunction Table)都有可能在不同的编译单元里生成相同的代码。
若不进行重复代码消除,会存在以下问题:
- 空间浪费。可以想象一个有几百个编译单元的工程同时实例化了许多个模板,最后链接的时候必须将这些重复的代码消除掉,否则最终程序的会很大。
- 地址容易出错。有可能两个指向同一个函数的指针会不相等。
- 指令运行效率较低。因为现代的CPU都会对指令和数据进行缓存,如果同样一份指令有多份副本,那么指令Cache的命中率就会降低。
重复代码消除方案:
以一个有几百个编译单元的工程同时实例化了许多个模板为例
比较有效的方案是,将每个模板的实例代码都单独存放于一个段内,也就是说每个段只包含一个模板实例。
比如有个模板函数是add<T>(),某个编译单元以int类型和float类型实例化了该模板函数,那么该编译单元的日标文件中就包含了两个该模板实例的段。为了简单起见,我们假设这两个段的名字分别叫.temp.add<int>和temp.add<tloat>。这样,当别的编译单元也以int或float类型实例化该模板函数后,也会生成同样的名字,这样链接器在最终链接的时候可以区分这些相同的模板实例段,然后将它们合并入最后的代码段。
同样地,对于内联函数和虚函数表的做法也类似。
函数级别链接
由于现在的程序和库通常来讲都非常庞大,一个可重定向文件可能包含成千上百个函数或变量,当我们须用到某个可重定向文件中的任意一个函数或变拱时,就需要把它整个地链接进来,也就是说那些没有用到的函数也被一起链接了进来。 这样的后果是链接输出文件会变得很大, 所有用到的没用到的变量和函数都一起塞到了输出文件中。
因此出现了函数级别链接这个机制。具体作用就是让所有的函数都像前面模板函数一样, 单独保存到一个段里。 当链接器需要用到某个函数时, 它就将它合并到输出文件中,对于那些没有用的函数则将它们抛弃。
这种做法可以很大程度上减小输出文件的长度,减少空间浪费。但是这个优化选项会减慢编译和链接过程,因为链接器须要计算各个函数之间的依赖关系,并且所有函数都保持到独立的段中,目标函数的段的数量大大增加,重定位过程也会因为段的数目的增加而变得复杂,目标文件随着段数目的增加也会变得相对较大。
全局构造与析构
我们知道一般的一个C/C++程序是从 main 开始执行的, 随着 main 函数的结束而结束。然而其实在 main 函数被调用之前,为了程序能够顺利执行,要先初始化进程执行环境, 比如堆分配初始化 (malloc、 free)、 线程子系统等.c++的全局对象构造函数也是在这一时期被执行的,我们知道 C++ 的全局对象的构造函数在 main 之前被执行 C++全局对象的析构函数在 main 之后被执行.
Linux 系统下一般程序的入口是 “ _start",这个函数是 Linux 系统库 (Glibc) 的一部分.当我们的程序与 Glibc 库链接在一起形成最终可执行文件以后,这个函数就是程序的初始化部分的入口, 程序初始化部分完成一系列初始化过程之后,会调用 main 函数来执行程序的主体。在 main 函数执行完成以后,返回到初始化部分,它进行一些清理工作,然后结束进程。对于有些场合,程序的一些特定的操作必须在 main 函数之前被执行,还有一些操作必须在main函数之后被执行, 其中很具有代表性的就是 C++的全局对象的构造和析构函数。
因此ELF文件还定义了两种特殊的段。
- .init 该段里面保存的是可执行指令,它构成了进程的初始化代码。因此, 当一个程序开始运行时, 在main函数被调用之前,Glibc的初始化部分安排执行这个段的中的代码。
- .fini 该段保存着进程终止代码指令。因此,当一个程序的main函数正常退出时,Glibc 会安排执行这个段中的代码。
这两个段.init和.fini的存在有着特别的目的,如果一个函数放到.init段,在main函数执行前系统就会执行它。 同理, 假如一个函数放到.fini段, 在main函数返回后该函数就会被执行。 利用这两个特性, C++的全局构造和析构函数就由此实现。
C++&ABI&AP
两个不同编译器编译出来的可重定向文件互相链接需满足以下条件:
- 采用相同的可重定向文件格式
- 拥有同样的符号修饰标准
- 变量的内存分布方式相同
- 函数的调用方式相同
而上面这些与可执行代码二进制兼容性相关的内容称为ABI(Application Binary Interface)。
ABI与API其实都是所谓的应用程序接口,但是它们所描述的接口所在的层面不一样。
API往往指源代码级别的接口,如API标准、Windows所规定的编程接口
ABI是指二进制层面的接口,ABI的兼容程度比API更为严格,如C++的对象内存分布。