爬百度热点的多种方法
对比下多个方法
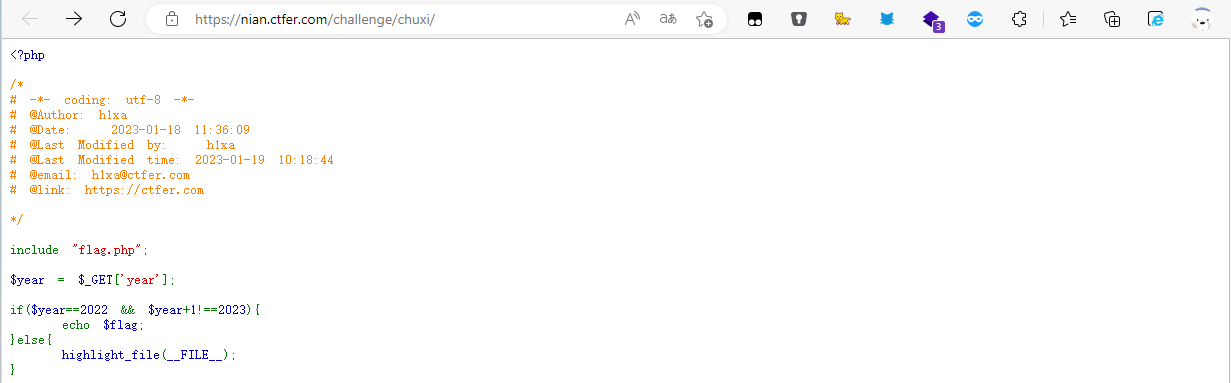
selenium爬取
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
ele_hots = driver.find_elements('css selector','.title-content-title')
for ele_hot in ele_hots:
print(ele_hot.text)
pyquery爬取
from pyquery import PyQuery as pq
from local_fake_useragent import UserAgent
ua_chrome = UserAgent('chrome')
baidu = pq(url='https://www.baidu.com/',headers={'user-agent':ua_chrome.rget})
hot_news = baidu('.title-content-title').items()
for hot in hot_news:
print(hot.text())
requests+lxml爬取
import requests
from lxml import etree
from local_fake_useragent import UserAgent
ua_chrome = UserAgent('chrome')
baidu_text = requests.get(url='https://www.baidu.com/',headers={'user-agent':ua_chrome.rget}).text
hot_news = etree.HTML(baidu_text).xpath('//*[@class="title-content-title"]')
for hot in hot_news:
print(hot.text)
对比
| 方案一 | 方案二 | 方案三 | |
|---|---|---|---|
| 库 | selenium | pyquery | requests+lxml |
| UI | √ | × | × |
| 需要ua | × | √ | √ |
| 定位方式 | css|xpath | css | xpath |
| 获取数据 | 需要操作 | 无需操作 | 无需操作 |
| 绕过鉴权 | 有多种方法 | 需要结合其他库 | 需要结合其他库 |
- selenium中的确可以隐藏界面,但在爬取的时候可能会失效
- selenium在该案例中无法提现优势,但在需要高度鉴权的一些场景中(如验证码),就比较方便,比如结合OCR技术,比如滑动鼠标操作,比如cookie、option的绕过等
- 但在获取所需数据的时候,纯粹的selenium是需要操作的(比如点击,跳转),而其他的库是不需要的,在效率上差距蛮大的。
- 这些都只是适合小型爬虫