ZooKeeper概述
zookeeper介绍
zookeeper是一个开源的分布式协调服务框架,为分布式系统提供一致性服务。zookeeper是apache的一个子项目。
-
例如一个网上商城购物系统,并发量太大单机系统承受不住,那我们可以多加几台服务器支持大并发量的访问需求,这个就是所谓的cluster集群 。
-
如果我们将这个网上商城购物系统拆分成多个子系统,比如订单系统、积分系统、购物车系统等等,然后将这些子系统部署在不同的服务器上 ,这个时候就是Distributed分布式 。
-
对于集群来说,多加几台服务器就行(当然还得解决session共享,负载均衡等问题),而对于分布式来说,首先需要将业务进行拆分,然后再加服务器,同时还要去解决分布式带来的一系列问题。比如各个分布式组件如何协调起来,如何减少各个系统之间的耦合度,如何处理分布式事务,如何去配置整个分布式系统,如何解决各分布式子系统的数据不一致问题等等。ZooKeeper 主要就是解决这些问题的。
使用zookeeper的开源项目
-
Kafka : ZooKeeper 主要为 Kafka 提供 Broker 和 Topic 的注册以及多个 Partition 的负载均衡等功能。
-
Hbase : ZooKeeper 为 Hbase 提供确保整个集群只有一个 Master 以及保存和提供 regionserver 状态信息(是否在线)等功能。
-
Hadoop : ZooKeeper 为 Namenode 提供高可用支持。
-
Dubbo:阿里巴巴集团开源的分布式服务框架,它使用 ZooKeeper 来作为其命名服务,维护全局的服务地址列表。
zookeeper的三种运行模式
-
单机模式:这种模式一般适用于开发测试环境,一方面我们没有那么多机器资源,另外就是平时的开发调试并不需要极好的稳定性。
-
集群模式:一个 ZooKeeper 集群通常由一组机器组成,一般 3 台以上就可以组成一个可用的 ZooKeeper 集群了。组成 ZooKeeper 集群的每台机器都会在内存中维护当前的服务器状态,并且每台机器之间都会互相保持通信。
-
伪集群模式:这是一种特殊的集群模式,即集群的所有服务器都部署在一台机器上。ZooKeeper 允许你在一台机器上通过启动不同的端口来启动多个 ZooKeeper 服务实例,从而以集群的特性来对外服务。
ZooKeeper的组件及架构
ZooKeeper的特点

-
集群:ZooKeeper是由一个Leader、多个Follower组成的集群
-
高可用性:集群中只要有半数以上的节点存活,ZooKeeper集群就能正常服务
-
全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的
-
更新请求顺序进行:来自同一个Client的更新请求按其发送顺序一次进行
-
数据更新原子性:一次数据更新要么成功,要么失败
-
实时性:在一定时间范围内,Client能读到最新数据
-
从设计模式角度来看,zk是一个基于观察者设计模式的框架,它负责管理跟存储大家都关心的数据,然后接受观察者的注册,数据反生变化zk会通知在zk上注册的观察者做出反应
-
Zookeeper是一个分布式协调系统,满足CP性
CAP、BASE理论
不管是CAP理论还是BASE理论,它们都需要算法来实现,这些算法有:2PC、3PC、Paxos、Raft、ZAB
它们所解决的问题全部都是:在分布式环境下,如何让系统尽可能的高可用,并且数据能最终达到一致
CAP理论
CAP定理:一个分布式系统必然会存在一个问题,因为分区容错性(partition tolerance)的存在,就必定要求我们需要在系统可用性(availability)和数据一致性(consistency)中做出权衡
-
P(partition):分区容错性,分区容错性是一定要被满足的
-
C(consistency):数据一致性
-
A(availability):可用性
举个例子来说明,假如班级代表整个分布式系统,而学生是整个分布式系统中一个个独立的子系统。这个时候班里的小红小明偷偷谈恋爱被班里的小花发现了,小花告诉了周围的人,然后小红小明谈恋爱的消息在班级里传播起来了。当在消息的传播(散布)过程中,你问班里一个同学的情况,如果他回答你不知道,那么说明整个班级系统出现了数据不一致的问题(因为小花已经知道这个消息了)。而如果他直接不回答你,因为现在消息还在班级里传播(为了保证一致性,需要所有人都知道才可提供服务),这个时候就出现了系统的可用性问题。在这个例子中,后者就是zookeeper的处理方式,它保证CP(数据一致性)
BASE理论
CAP理论中,P是必然要被满足的,因为是分布式系统,不能把所有应用都放到一台服务器中,所以只能在AP(可用性)和CP(一致性)中寻找平衡,在这种情况下衍生出了BASE理论:即使无法做到强一致性,当分布式系统可以根据自己的业务特点,采用适当的方式来使系统达到最终一致性。
BASE理论:Basically Available基本可用、Soft state软状态、Eventually consistent最终一致性
-
基本可用(Basically Available):基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。例如,电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层在该页面只提供降级服务。
-
软状态(Soft State): 软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有多个副本,允许不同节点间副本同步的延时就是软状态的体现。
-
最终一致性(Eventual Consistency): 最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
概括就是:平时系统要求是基本可用,运行有可容忍的延迟状态,但是,经过一段时间的延迟后系统必须达成数据是一致的。
ACID是创痛数据库常用的设计理念,追求强一致性模型;BASE支持的是大型分布式系统,通过牺牲强一致性获得高可用。
ZAB协议
ZooKeeper在解决分布式数据一致性的问题时没有直接使用Paxos,而是专门定制了一致性协议ZAB(ZooKeeper Automic Broadcast)原子广播协议,ZAB能够很好的支持崩溃恢复。
ZAB中的三个角色
-
Leader :集群中唯一的写请求处理者 ,能够发起投票(投票也是为了进行写请求)
-
Follower:能够接收客户端的请求,如果是读请求则可以自己处理,如果是写请求则要转发给 Leader 。在选举过程中会参与投票,有选举权和被选举权
-
Observer :就是没有选举权和被选举权的 Follower
在 ZAB协议中对 zkServer(即三个角色的总称) 还有两种模式的定义,分别是 消息广播 和 崩溃恢复 。
ZXID和myid
ZXID
ZooKeeper 采用全局递增的事务 id 来标识,所有 proposal(提议)在被提出的时候加上了ZooKeeper Transaction Id 。
ZXID是64位的Long类型,ZXID是保证事务的顺序一致性的关键。
ZXID中高32位表示纪元epoch,低32位表示事务标识xid。可以认为zxid越大说明存储数据越新,如下图所示:

-
epoch:每个leader都会具有不同的epoch值,表示一个纪元/朝代,用来标识 leader周期。每个新的选举开启时都会生成一个新的epoch,从1开始,每次选出新的Leader,epoch递增1,并会将该值更新到所有的zkServer的zxid的epoch。
-
xid:xid是一个依次递增的事务编号。数值越大说明数据越新,可以简单理解为递增的事务id。每次epoch变化,都将低32位的序号重置,这样保证了zxid的全局递增性。
myid
每个ZooKeeper服务器,都需要在数据文件夹下创建一个名为myid的文件,该文件包含整个ZooKeeper集群唯一的id(整数)
例如,某ZooKeeper集群包含三台服务器,hostname分别为zoo1、zoo2和zoo3,其myid分别为1、2和3,则在配置文件中其id与hostname必须一一对应,如下所示。在该配置文件中,server.后面的数据即为myid
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
历史队列
每一个follower节点都会有一个先进先出(FIFO)的队列用来存放收到的事务请求,保证执行事务的顺序。所以:
-
可靠提交由ZAB的事务一致性协议保证
-
全局有序由TCP协议保证
-
因果有序由follower的历史队列(history queue)保证
消息广播模式
ZAB协议两种模式:消息广播模式和崩溃恢复模式。

说白了就是 ZAB 协议是如何处理写请求的,上面说只有 Leader 能处理写请求,但是Follower 和 Observer 也需要同步更新数据
处理写请求的流程
Leader 会将写请求 广播 出去,Leader 询问 Followers 是否同意更新,如果超过半数以上的同意那么就进行 Follower 和 Observer 的更新(和 Paxos 一样)。
消息广播机制是通过如下图流程保证事务的顺序一致性的:

-
leader从客户端收到一个写请求
-
leader生成一个新的事务并为这个事务生成一个唯一的ZXID
-
leader将这个事务发送给所有的follows节点,将带有 zxid 的消息作为一个提案(proposal)分发给所有 follower。
-
follower节点将收到的事务请求加入到历史队列(history queue)中,当 follower 接收到 proposal,先将 proposal 写到硬盘,写硬盘成功后再向 leader 回一个 ACK
-
当leader收到大多数follower(超过一半)的ack消息,leader会向follower发送commit请求(leader自身也要提交这个事务)
-
当follower收到commit请求时,会判断该事务的ZXID是不是比历史队列中的任何事务的ZXID都小,如果是则提交事务,如果不是则等待比它更小的事务的commit(保证顺序性)
-
Leader将处理结果返回给客户端
过半写成功策略
Leader节点接收到写请求后,这个Leader会将写请求广播给各个Server,各个Server会将该写请求加入历史队列,并向Leader发送ACK信息,当Leader收到一半以上的ACK消息后,说明该写操作可以执行。Leader会向各个server发送commit消息,各个server收到消息后执行commit操作。
-
Leader并不需要得到Observer的ACK,即Observer无投票权
-
Leader不需要得到所有Follower的ACK,只要收到过半的ACK即可,同时Leader本身对自己有一个ACK
-
Observer虽然无投票权,但仍须同步Leader的数据从而在处理读请求时可以返回尽可能新的数据
Follower/Observer也可以接受写请求,此时:
-
Follower/Observer接受写请求以后,不能直接处理,而需要将写请求转发给Leader处理
-
除了多了一步请求转发,其它流程与直接写Leader无任何区别
-
Leader处理写请求是通过上面的消息广播模式,实质上最后所有的zkServer都要执行写操作,这样数据才会一致
而对于读请求,Leader/Follower/Observer都可直接处理读请求,从本地内存中读取数据并返回给客户端即可。由于处理读请求不需要各个服务器之间的交互,因此Follower/Observer越多,整体可处理的读请求量越大,也即读性能越好。
崩溃恢复模式
恢复模式大致可以分为四个阶段:选举、发现、同步、广播。
选举阶段(Leader election):
-
当leader崩溃后,集群进入选举阶段(选举Leader),开始选举出潜在的准 leader,然后进入下一个阶段。
发现阶段(Discovery):
-
用于在从节点中发现最新的ZXID和事务日志。
-
准Leader接收所有Follower发来各自的最新epoch值。Leader从中选出最大的epoch,基于此值加1,生成新的epoch分发给各个Follower。
-
各个Follower收到全新的epoch后,返回ACK给Leader,带上各自最大的ZXID和历史提议日志。
-
Leader选出最大的ZXID,并更新自身历史日志,此时Leader就用拥有了最新的提议历史。(注意:每次epoch变化时,ZXID的第32位从0开始计数)。
同步阶段(Synchronization):
-
主要是利用 leader 前一阶段获得的最新提议历史,同步给集群中所有的Follower。
-
只有当超过半数Follower同步成功,这个准Leader才能成为正式的Leader。
-
这之后,follower 只会接收 zxid 比自己的 lastZxid 大的提议。
广播阶段(Broadcast):
-
集群恢复到广播模式,开始接受客户端的写请求。
脑裂问题
脑裂问题:所谓的“脑裂”即“大脑分裂”,也就是本来一个“大脑”被拆分了两个或多个“大脑”。
通俗的说,就是当 cluster 里面有两个节点,它们都知道在这个 cluster 里需要选举出一个 master。那么当它们两之间的通信完全没有问题的时候,就会达成共识,选出其中一个作为 master。但是如果它们之间的通信出了问题,那么两个结点都会觉得现在没有 master,所以每个都把自己选举成 master,于是 cluster 里面就会有两个 master。
ZAB为解决脑裂问题,要求集群内的节点数量为2N+1, 当网络分裂后,始终有一个集群的节点数量过半数,而另一个集群节点数量小于N+1(即小于半数), 因为选主需要过半数节点同意,所以任何情况下集群中都不可能出现大于一个leader的情况。
因此,有了过半机制,对于一个Zookeeper集群,要么没有Leader,要没只有1个Leader,这样就避免了脑裂问题。
Zookeeper选举机制
Leader 选举可以分为两个不同的阶段,第一个是 Leader 宕机需要重新选举,第二则是当 Zookeeper 启动时需要进行系统的 Leader 初始化选举。
zkserver的几种状态:
-
LOOKING 不确定Leader状态。该状态下的服务器认为当前集群中没有Leader,会发起Leader选举。
-
FOLLOWING 跟随者状态。表明当前服务器角色是Follower,并且它知道Leader是谁。
-
LEADING 领导者状态。表明当前服务器角色是Leader,它会维护与Follower间的心跳。
-
OBSERVING 观察者状态。表明当前服务器角色是Observer,与Folower唯一的不同在于不参与选举,也不参与集群写操作时的投票。
初始化Leader选举
假设我们集群中有3台机器,那也就意味着我们需要2台同意(超过半数)。这里假设服务器1~3的myid分别为1,2,3,初始化Leader选举过程如下:
-
服务器 1 启动,发起一次选举。它会首先 投票给自己 ,投票内容为(myid, ZXID),因为初始化所以 ZXID 都为0,此时 server1 发出的投票为(1, 0),即myid为1, ZXID为0。此时服务器 1 票数一票,不够半数以上,选举无法完成,服务器 1 状态保持为 LOOKING。
-
服务器 2 启动,再发起一次选举。服务器2首先也会将投票选给自己(2, 0),并将投票信息广播出去(server1也会,只是它那时没有其他的服务器了),server1 在收到 server2 的投票信息后会将投票信息与自己的作比较。首先它会比较 ZXID ,ZXID 大的优先为 Leader,如果相同则比较 myid,myid 大的优先作为 Leader。所以,此时server1 发现 server2 更适合做 Leader,它就会将自己的投票信息更改为(2, 0)然后再广播出去,之后server2 收到之后发现和自己的一样无需做更改。此时,服务器1票数0票,服务器2票数2票,投票已经超过半数,确定 server2 为 Leader。服务器 1更改状态为 FOLLOWING,服务器 2 更改状态为 LEADING。
-
服务器 3 启动,发起一次选举。此时服务器 1,2已经不是 LOOKING 状态,它会直接以 FOLLOWING 的身份加入集群。
运行时Leader选举
运行时候如果Leader节点崩溃了会走崩溃恢复模式,新Leader选出前会暂停对外服务,大致可以分为四个阶段:选举、发现、同步、广播(见4.5节),此时Leader选举流程如下:
-
Leader挂掉,剩下的两个 Follower 会将自己的状态 从 Following 变为 Looking 状态 ,每个Server会发出一个投票,第一次都是投自己,其中投票内容为(myid, ZXID),注意这里的 zxid 可能不是0了
-
收集来自各个服务器的投票
-
处理投票,处理逻辑:优先比较ZXID,然后比较myid
-
统计投票,只要超过半数的机器接收到同样的投票信息,就可以确定leader
-
改变服务器状态Looking变为Following或Leading
-
然后依次进入发现、同步、广播阶段
举个例子来说明,假设集群有三台服务器,Leader (server2)挂掉了,只剩下server1和server3。 server1 给自己投票为(1,99),然后广播给其他 server,server3 首先也会给自己投票(3,95),然后也广播给其他 server。server1 和 server3 此时会收到彼此的投票信息,和一开始选举一样,他们也会比较自己的投票和收到的投票(zxid 大的优先,如果相同那么就 myid 大的优先)。这个时候 server1 收到了 server3 的投票发现没自己的合适故不变,server3 收到 server1 的投票结果后发现比自己的合适于是更改投票为(1,99)然后广播出去,最后 server1 收到了,发现自己的投票已经超过半数,就把自己设为 Leader,server3 也随之变为Follower。
ZooKeeper数据模型
znode及其类型
znode
ZooKeeper 数据模型(Data model)采用层次化的多叉树形结构,每个节点上都可以存储数据,这些数据可以是数字、字符串或者是二级制序列。并且,每个节点还可以拥有 N 个子节点,最上层是根节点以 / 来代表。
-
每个数据节点在 ZooKeeper 中被称为 znode,它是 ZooKeeper 中数据的最小单元。并且,每个 znode 都一个唯一的路径标识。
-
由于ZooKeeper 主要是用来协调服务的,而不是用来存储业务数据的,这种特性使得 Zookeeper 不能用于存放大量的数据,每个节点的存放数据上限为1M。
和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
四种类型的znode
-
持久化目录节点 PERSISTENT:客户端与zookeeper断开连接后,该节点依旧存在。
-
持久化顺序编号目录节点 PERSISTENT_SEQUENTIAL:客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号。
-
临时目录节点 EPHEMERAL:客户端与zookeeper断开连接后,该节点被删除。
-
临时顺序编号目录节点 EPHEMERAL_SEQUENTIAL:客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号。
查看znode的信息
在zookeeper客户端使用get命令可以查看znode的内容和状态信息:
[zk: 10.0.0.81:2181(CONNECTED) 0] ls /
[mytest, cluster, controller, brokers, zookeeper, admin, isr_change_notification, log_dir_event_notification, controller_epoch, testNode, consumers, latest_producer_id_block, config]
[zk: 10.0.0.81:2181(CONNECTED) 1] get /mytest
test2 data2
cZxid = 0x200000006 # create ZXID,即该数据节点被创建时的事务 id
ctime = Wed Mar 01 17:06:20 CST 2023 # create time,znode 被创建的毫秒数(从1970 年开始)
mZxid = 0x200000008 # modified ZXID,znode 最后更新的事务 id
mtime = Wed Mar 01 17:08:14 CST 2023 # modified time,znode 最后修改的毫秒数(从1970 年开始)
pZxid = 0x200000006 # znode 最后更新子节点列表的事务 id,只有子节点列表变更才会更新 pZxid,子节点内容变更不会更新
cversion = 0 # znode 子节点变化号,znode 子节点修改次数,子节点每次变化时值增加 1
dataVersion = 1 # znode 数据变化号,节点创建时为 0,每更新一次节点内容(不管内容有无变化)该版本号的值增加 1
aclVersion = 0 # znode 访问控制列表(ACL )版本号,表示该节点 ACL 信息变更次数
ephemeralOwner = 0x0 # 如果是临时节点,这个是 znode 拥有者的 sessionid。如果不是临时节,则 ephemeralOwner=0
dataLength = 11 # znode 的数据长度
numChildren = 0 # znode 子节点数量
ZooKeeper监听通知机制
Session会话
session可以看作是ZooKeeper服务器与客户端之间的一个tcp长连接,客户端与服务端之间的任何交互操作都和session有关。
client端连接Server端默认的2181端口,也就是session会话。
ZooKeeper客户端通过tcp长连接连接到服务集群,会话session从第一次连接开始就已经建立,之后通过心跳检测机制来保持有效的会话状态。通过这个连接,客户端可以发送请求并接收响应,同时也可以接收到watch事件的通知。
当由于网络故障或客户端主动断开等原因,导致连接断开,此时只要在会话超时时间之内重新建立连接,则之前创建的会话依然有效。
watcher监听机制
wantcher监听机制是ZooKeeper的重要特性,基于ZooKeeper上创建的节点,可以对这些节点绑定监听事件(比如可以监听节点数据变更、节点删除、子节点状态变更等事件),通过这个事件机制,可以基于ZooKeeper实现分布式锁、集群管理等功能。它有点类似于订阅的方式,即客户端向服务端注册指定的watcher,当服务端符合了watcher的某些事件或要求则会向客户端发送事件通知,客户端收到通知后找到自己定义的watcher,然后执行响应的回调方法。
当客户端在ZooKeeper上某个节点绑定监听事件后,如果该事件被触发,ZooKeeper会通过回调函数的方式通知客户端,但是客户端只会收到一次通知。如果后续这个节点再次发生变化,那么之前设置watcher的客户端不会再次收到消息(watcher是一次性的操作),可以通过循环监听去达到永久监听效果。
ZooKeeper 的 Watcher 机制,总的来说可以分为三个过程:
-
客户端注册 Watcher,注册 watcher 有 3 种方式,getData、exists、getChildren
-
服务器处理 Watcher
-
服务端回调 Watcher 客户端
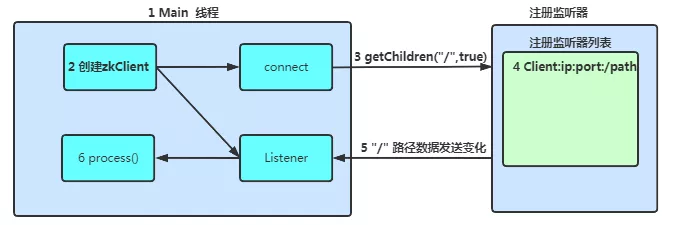
监听通知机制的流程
-
首先要有一个main()线程
-
在main线程中创建zkClient,这时就会创建两个线程,一个负责网络连接通信(connet),一个负责监听(listener)
-
通过connect线程将注册的监听事件发送给Zookeeper
-
在Zookeeper的注册监听器列表中将注册的监听事件添加到列表中
-
Zookeeper监听到有数据或路径变化,就会将这个消息发送给listener线程
-
listener线程内部调用了process()方法
ZooKeeper分布式锁
分布式锁是雅虎研究员设计Zookeeper的初衷。利用Zookeeper的临时顺序节点,可以轻松实现分布式锁。
获得锁
首先,在Zookeeper当中创建一个持久节点ParentLock。当第一个客户端想要获得锁时,需要在ParentLock这个节点下面创建一个临时顺序节点 Lock1:

之后,Client1查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock1是不是顺序最靠前的一个。如果是第一个节点,则成功获得锁:

这时候,如果再有一个客户端 Client2 前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock2:

Client2查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock2是不是顺序最靠前的一个,结果发现节点Lock2并不是最小的。
于是,Client2向排序仅比它靠前的节点Lock1注册Watcher,用于监听Lock1节点是否存在。这意味着Client2抢锁失败,进入了等待状态:

这时候,如果又有一个客户端Client3前来获取锁,则在ParentLock下再创建一个临时顺序节点Lock3:

Client3查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock3是不是顺序最靠前的一个,结果同样发现节点Lock3并不是最小的。于是,Client3向排序仅比它靠前的节点Lock2注册Watcher,用于监听Lock2节点是否存在。这意味着Client3同样抢锁失败,进入了等待状态。
这样一来,Client1得到了锁,Client2监听了Lock1,Client3监听了Lock2。这恰恰形成了一个等待队列。
释放锁
任务完成,客户端显示释放
当任务完成时,Client1会显示调用删除节点Lock1的指令:

任务执行过程中,客户端崩溃
获得锁的Client1在任务执行过程中,如果崩溃,则会断开与Zookeeper服务端的链接。根据临时节点的特性,相关联的节点Lock1会随之自动删除:

由于Client2一直监听着Lock1的存在状态,当Lock1节点被删除,Client2会立刻收到通知。这时候Client2会再次查询ParentLock下面的所有节点,确认自己创建的节点Lock2是不是目前最小的节点。如果是最小,则Client2顺理成章获得了锁:

同理,如果Client2也因为任务完成或者节点崩溃而删除了节点Lock2,那么Client3就会接到通知:

最终,Client3成功得到了锁:

ZooKeeper和Redis分布式锁的比较

ZooKeeper和Redis实现的分布式锁都支持可重入(两者都可以在客户端实现可重入逻辑)
什么是 “可重入”:可重入就是说某个线程已经获得某个锁,可以再次获取锁而不会出现死锁
ZooKeeper的应用场景
数据发布/订阅
当某些数据由几个机器共享,且这些信息经常变化数据量还小的时候,这些数据就适合存储到ZK中
-
数据存储:将数据存储到ZooKeeper上的一个数据节点
-
数据获取:应用在启动初始化节点从ZooKeeper数据节点读取数据,并且在该节点上注册一个数据变更watcher
-
数据变更:当变更数据时会更新ZooKeeper对应节点的数据,ZooKeeper会将数据变更通知发到各客户端,客户端接受到通知后重新读取变更后的数据即可
统一配置管理
本质上,统一配置管理和数据发布/订阅是一样的。分布式环境下,配置文件的同步可以由Zookeeper来实现:
-
将配置文件写入Zookeeper的一个ZNode
-
各个客户端服务监听这个ZNode
-
一旦ZNode发生改变,Zookeeper将通知各个客户端服务

统一集群管理
可能我们会有这样的需求,我们需要了解整个集群中有多少机器在工作,我们想对集群中的每台机器的运行时状态进行数据采集,对集群中机器进行上下线操作等等。
例如,集群机器监控:这通常用于那种对集群中机器状态,机器在线率有较高要求的场景,能够快速对集群中机器变化作出响应。这样的场景中,往往有一个监控系统,实时检测集群机器是否存活。过去的做法通常是:监控系统通过某种手段(比如ping)定时检测每个机器,或者每个机器自己定时向监控系统汇报“我还活着”。 这种做法可行,但是存在两个比较明显的问题:
-
集群中机器有变动的时候,牵连修改的东西比较多。
-
有一定的延时。
利用ZooKeeper有两个特性,就可以实时另一种集群机器存活性监控系统:
-
客户端在某个节点上注册一个Watcher,那么如果该节点的子节点变化了,会通知该客户端。
-
创建EPHEMERAL类型的节点,一旦客户端和服务器的会话结束或过期,那么该节点就会消失。
如下图所示,监控系统在/manage节点上注册一个Watcher,如果/manage子节点列表有变动,监控系统就能够实时知道集群中机器的增减情况,至于后续处理就是监控系统的业务了。

负载均衡

负载均衡可以通过nginx在服务端进行配置,也可以通过ZooKeeper在客户端进行配置。
-
多个服务注册
-
客户端获取中间件地址集合
-
从集合中随机选一个服务执行任务
ZooKeeper负载均衡和Nginx负载均衡区别:
-
ZooKeeper不存在单点问题,zab机制保证单点故障可重新选举一个leader只负责服务的注册与发现,不负责转发,减少一次数据交换(消费方与服务方直接通信),需要自己实现相应的负载均衡算法。
-
Nginx存在单点问题,单点负载高数据量大,需要通过 KeepAlived + LVS 备机实现高可用。每次负载,都充当一次中间人转发角色,增加网络负载量(消费方与服务方间接通信),自带负载均衡算法。
命名服务

命名服务是指通过指定的名字来获取资源或者服务的地址,利用 zk 创建一个全局唯一的路径,这个路径就可以作为一个名字,指向集群中某个具体的服务器,提供的服务的地址,或者一个远程的对象等等。
注意:所有向 ZooKeeper 上注册的地址都是临时节点,这样就能够保证服务提供者和消费者能够自动感应资源的变化。
ZooKeeper的部署和操作
ZooKeeper单机部署
单机ZooKeeper的安装及配置
ZooKeeper需要java环境,需要安装jdk
# 1.安装jdk8
yum install -y java-1.8.0-openjdk
# 2.准备ZooKeeper的安装包
tar -zxf zookeeper-3.4.13.tar.gz -C /usr/local/
ln -s /usr/local/zookeeper-3.4.13 /usr/local/zookeeper
mkdir -pv /data/zookeeper/data/ # 创建一个存储ZooKeeper数据的data目录
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg # 创建配置文件
# 3.配置环境变量
sed -i '$aPATH="/usr/local:$PATH"' /etc/profile
source /etc/profile
# 4.修改ZooKeeper数据存储目录和端口号
vim /usr/local/zookeeper/conf/zoo.cfg
dataDir=/data/zookeeper/data/
clientPort=2181
# 5.启动ZooKeeper
zkServer start # 启动ZooKeeper
zkServer.sh status # 查看ZooKeeper状态,当前的单机运行模式
# 6.查看进程及端口
ps -ef |grep zookeeper
ss -tnl | grep 2181
ZooKeeper的配置文件
vim /usr/local/zookeeper/conf/zoo.cfg
tickTime=2000 # zookeeper时间配置的基本单位,follower和leader之间心跳检测间隔时间(单位毫秒,默认:2000)
initLimit=10 # 允许follower初始化连接到leader的最大时长,它表示tickTime时间倍数,即: initLimit*tickTime
# 也就是: 集群中的follower服务器与leader服务器之间初始连接时能容忍的最多心跳数(tickTime的数量)
syncLimit=5 # 允许follower与leader数据同步最大时长,它表示tickTime时间倍数,即: initLimit*tickTime
# 也就是: 集群中follower服务器跟leader服务器之间的请求和应答最多能容忍的心跳数(tickTime的数量)
# 即: 表示5*2000,结果: 10000毫秒
dataDir=../data # zookeeper数据存储目录及日志保存目录(如果没有指明dataLogDir,则日志也保存在这个文件中)
# 或者用下面方式,将数据和日志分开保存
# dataDir=../data # 数据目录
# dataLogDir=../log # 日志目录
clientPort=2181 # 对客户端提供的端口号
maxClientCnxns=60 # 单个客户端与zookeeper最大并发连接数
autopurge.snapRetainCount=3 # 保存的数据快照数量,之外的将会被清除
autopurge.purgeInterval=1 # 自动触发清除任务时间间隔,小时为单位,默认为0,表示不自动清除
ZooKeeper集群部署
基本集群环境
| 节点 | IP | Port | OS |
|---|---|---|---|
| node01 | 10.0.0.80 | 2181 | CentOS7.9 |
| node02 | 10.0.0.81 | 2181 | CentOS7.9 |
| node03 | 10.0.0.82 | 2181 | CentOS7.9 |
部署ZooKeeper集群
在每台节点上(node01、node02、node03)操作:
# 1.安装jdk8
yum install -y java-1.8.0-openjdk
# 2.准备ZooKeeper的安装包
tar -zxf zookeeper-3.4.13.tar.gz -C /usr/local/
ln -s /usr/local/zookeeper-3.4.13 /usr/local/zookeeper
mkdir -pv /data/zookeeper/data/ # 创建一个存储ZooKeeper数据的data目录
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg # 创建配置文件
# 3.配置环境变量
sed -i '$aPATH="/usr/local:$PATH"' /etc/profile
source /etc/profile
# 4.修改ZooKeeper数据存储目录和端口号,并配置集群信息
vim /usr/local/zookeeper/conf/zoo.cfg
dataDir=/data/zookeeper/data/
clientPort=2181
server.1=10.0.0.80:2888:3888 # server的格式:server是固定格式,server.1中的1表示集群中各个zk的编号,这里的1、2、3分别表示各个节点
server.2=10.0.0.81:2888:3888 # 这个编号需要在数据存储目录添加一个名为myid的文件,文件中的内容即为对应节点的编号
server.3=10.0.0.82:2888:3888 # 端口:
# 2888:表示follower跟leader的通信端口,简称服务内部通信的端口,默认为2888
# 3888:表示选举端口,默认为3888
# 5.创建myid文件
echo 1 > /data/zookeeper/data/myid # 注意:这里的文件名是固定的叫myid
# 每个节点操作的时候,要传入自己的编号,编号跟上面的配置文件中的对应
# 6.启动ZooKeeper
zkServer start # 启动ZooKeeper
zkServer.sh status # 查看ZooKeeper状态,Follower、Leader、Observer
ZooKeeper的数据持久化
-
zk的数据是运行在内存中,zk提供了两种持久化机制:事务日志、数据快照
事务日志
zk把执行的命令以日志形式保存在dataLogDir指定的路径中的文件中(如果没有指定dataLogDir,则按dataDir指定的路径)
数据快照
zk会在一定的时间间隔内做一次内存数据的快照,把该时刻的内存数据保存在快照文件中。
zk通过两种形式的持久化,在恢复时先恢复快照文件中的数据到内存中,再用日志文件中的数据做增量恢复,这样的恢复速度更快。
ZooKeeper命令行操作
系统服务相关
zkServer.sh start # 启动服务
zkServer.sh status # 查看服务状态
zkServer.sh restart # 重启服务
zkServer.sh stop # 停止服务
登录连接zk操作
# 客户端连接zk
zkCli.sh # 如果什么都不指定,则默认连接本机的2181端口
zkCli.sh -server 10.0.0.81:2181 # 指定IP和端口,可以连接集群中任何一个节点
# 查看节点
ls / # 查看 / 下有哪些节点
get / # 查看 / 节点的数据
get /mytest # /mytest 节点中的数据
# 创建节点
create /mytest "this is my test" # 在/下创建一个子节点/mytest,该节点的数据为 "this is my test"(默认创建的节点都是持久的)
get /mytest # 查看/mytest中的数据
set /mytest "test2" # 修改/mytest的数据
# 创建子节点
create /mytest/hahaha "my children" # 在/mytest节点下创建了子节点/mytest/hahaha,并存入数据
# 持久节点和临时节点:默认创建的都是持久节点,-e表示临时节点
# 带序号和不带序号节点:-s表示带序号
create -s /mytest2 "hello" # 创建一个带序号的持久节点/mytest2,并给定数据
create -e /mytest3 "xxx" # 创建一个临时节点/mytest3,并给定数据
create -s -e /mytest4 "hhh" # 创建一个带序号的临时节点/mytest4,并给定数据
# 查看节点的状态
stat /mytest
# 删除节点
rmr /mytest # 删除节点,包括下面的子节点,能递归删除
delete /mytest2 # 删除节点,delete不能递归删除,只能一级一级的删除
创建一个节点,让多个客户端同时监听该节点的数据变化(监听数据是否发生改变)
# 1.创建一个永久节点
create /mytestNode "hellohello"
# 2.获取该节点数据并监听该节点
get /mytestNode watch # 可以多个客户端同时监听该节点
# 注意:每次监听只能触发一次,监听一次后,在发生变化就不监听了,要想下次监听,就需要再执行一次带watch的命令
# 当另一个客户端修改了该节点的值后,当前这个客户端就会监听到
# 3.另起一个客户端,修改这个节点的值
set /mytestNode "hahaha" # 修改该节点的数据
# 4.此时之前的监听的客户端就会收到提示,监听到了有人修改了数据