1 txt文件
1.1 写操作
import numpy as np
def write(fileName,data):
file=open(fileName,'w')
row,col=data.shape
string=""
for i in range(row):
for j in range(col-1):
string+=str(data[i][j])+'\t'
string+=str(data[i][col-1])+'\n'
file.write(string)
file.flush()
file.close()
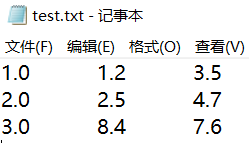
data=np.array([[1,1.2,3.5],[2,2.5,4.7],[3,8.4,7.6]])
write('test.txt',data)
1.2 读操作
| file.read([size]) | 读取 size 个字符,并将指针移到这次读取的最后一个字符的后面。当 size 省略时,表示读取所有内容 |
|---|---|
| file.readline() | 读取第一行的内容,并将指针移到下一行 |
| file.readlines() | 读取所有内容,并把每行的内容放到一个list里面 |
| file.seek(offset) | 指针移到 offset 处 |
import numpy as np
def read(fileName):
file=open(fileName,'r')
list=file.readlines()
file.close()
row=len(list)
col=len(list[0].split())
data=np.zeros((row,col),dtype='float32')
for i in range(row):
data[i,:]=list[i].split()
return data
data=read('test.txt')
print(data)
[[1. 1.2 3.5]
[2. 2.5 4.7]
[3. 8.4 7.6]]
2 cvs文件
2.1 cvs包
(1)写操作
import numpy as np
import csv
def write(fileName,data):
file=open(fileName,'w',newline='')
writer=csv.writer(file)
row,col=data.shape
for i in range(row):
writer.writerow(data[i,:])
file.flush()
file.close()
data=np.array([[1,1.2,3.5],[2,2.5,4.7],[3,8.4,7.6]])
write('test.csv',data)
(2)读操作
import numpy as np
import csv
def read(fileName):
file=open(fileName,'r')
reader=csv.reader(file)
data=[]
for row in reader:
data=data+[row]
file.close()
return np.array(data,dtype='float32')
data=read('test.csv')
print(data)
[[1. 1.2 3.5]
[2. 2.5 4.7]
[3. 8.4 7.6]]
2.2 pandas包
(1)写操作
import numpy as np
import pandas as pd
def write(fileName,data):
file=open(fileName,'w',newline='')
df=pd.DataFrame(data)
df.to_csv(file,header=None,index=False)
file.close()
data=np.array([[1,1.2,3.5],[2,2.5,4.7],[3,8.4,7.6]])
write('test.csv',data)
(2)读操作
import numpy as np
import pandas as pd
def read(fileName):
file=open(fileName,'r')
data=pd.read_csv(file,header=None).values.astype('float32')
file.close()
return data
data=read('test.csv')
print(data)
3 npy/npz文件
3.1 写操作
(1)npy 文件
import numpy as np
def write(fileName,data):
np.save(fileName,data)
data=np.array([[1,1.2,3.5],[2,2.5,4.7],[3,8.4,7.6]])
write('test.npy',data)
(2)npz 文件
npz 文件可以保存多个数组
import numpy as np
def write(fileName,data1,data2):
np.savez(fileName,data1=data1,data2=data2)
data1=np.array([[1,1.2,3.5],[2,2.5,4.7],[3,8.4,7.6]])
data2=np.array([1,2,3,4,5])
write('test.npz',data1,data2)

3.2 读操作
(1)npy 文件
import numpy as np
def read(fileName):
data=np.load(fileName)
return data
data=read('test.npy')
print(data)
[[1. 1.2 3.5]
[2. 2.5 4.7]
[3. 8.4 7.6]]
(2)npz 文件
import numpy as np
def read(fileName):
temp=np.load(fileName)
data1=temp['data1']
data2=temp['data2']
return data1,data2
data1,data2=read('test.npz')
print(data1)
print(data2)
[[1. 1.2 3.5]
[2. 2.5 4.7]
[3. 8.4 7.6]]
[1 2 3 4 5]
声明:本文转自Python中文件读写操作