爬取内容为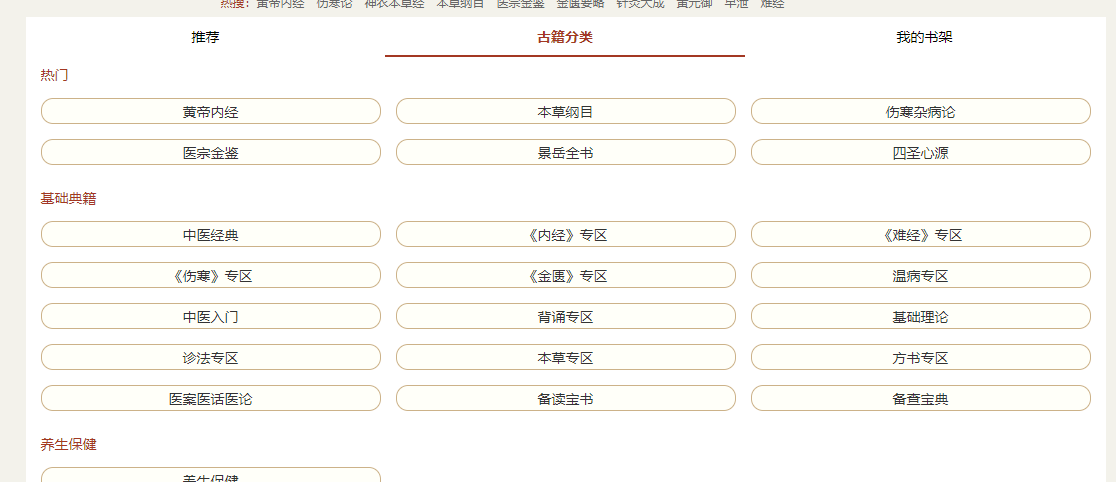
该图片下的七个分类, 然后对应的每个种类的书本信息(摘要和目录)
效果为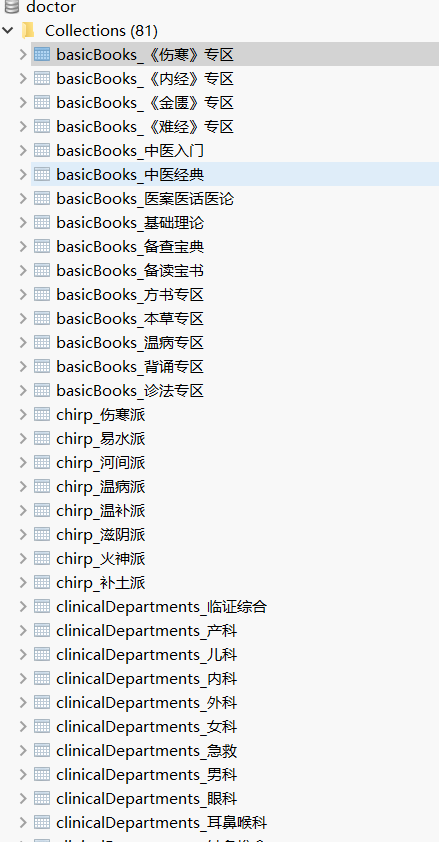
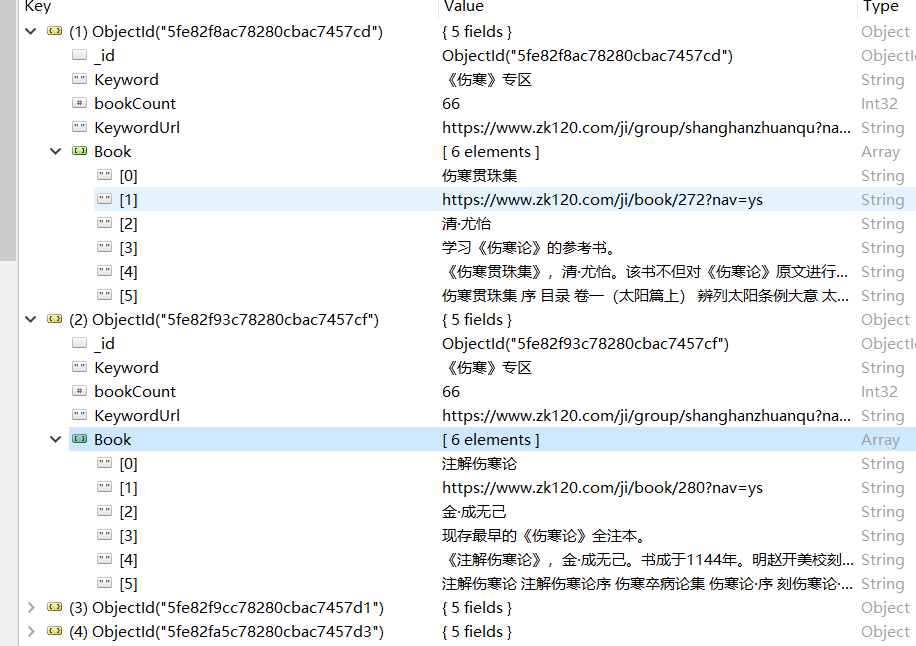
代码如下
import requests
from bs4 import BeautifulSoup
import re
import time
from selenium import webdriver
from selenium.common.exceptions import ElementNotInteractableException, NoSuchElementException
import pymongo
browser = webdriver.Chrome()
browser2 = webdriver.Chrome()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36 '
}
# 第一层的七个分类
allMap = {}
# 热门
hotMap = {} # range(0,6)
# 基础典籍
basicBooks = {} # range(6,21)
# 养生保健
health = {} # range(21,22)
# 孤本
orphan = {} # range(22,23)
# 临症各科
clinicalDepartments = {} # range(23, 35) 23 + 12
# 争鸣流派
chirp = {} # range(35, 44) +9
# 历代医家
doctors = {} # range(44, 82) +13*3-1
def toMongoDB(Keyword, name, bookCount, nameUrl, bookName, bookUrl, bookAuthor, bookDescription, digest, catlog):
myClient = pymongo.MongoClient("mongodb://localhost:27017/")
myDb = myClient["doctor"]
myCollection = myDb[str(Keyword) + "_" + str(name)]
myDictionary = {
"Keyword": name,
"bookCount": bookCount,
"KeywordUrl": nameUrl,
"Book": [
bookName, bookUrl, bookAuthor, bookDescription, digest, catlog
]
}
result = myCollection.insert_one(myDictionary)
print(result)
pass
def splitIntoSevenMap():
for i, (k, v) in enumerate(allMap.items()):
if i in range(0, 6):
hotMap[k] = v
# print(k, v)
if i in range(6, 21):
basicBooks[k] = v
# print(k, v)
if i in range(21, 22):
health[k] = v
# print(k, v)
if i in range(22, 23):
orphan[k] = v
# print(k, v)
if i in range(23, 35):
clinicalDepartments[k] = v
# print(k, v)
if i in range(35, 44):
chirp[k] = v
# print(k, v)
if i in range(44, 82):
doctors[k] = v
# print(k, v)
pass
def getSevenPart(html1, html2):
domain = 'https://www.zk120.com'
soup = BeautifulSoup(html1, 'html.parser')
# ResultSets = soup.find_all('h2', class_='group_title')
ResultSets = soup.find_all('h2', class_='group-hot-title')
# print(ResultSets) # 得到所有的标题 非热门的
for ResultSet in ResultSets:
tt = re.match('''<h2 class="group(.*)title">(.*)</h2>''', str(ResultSet))
liSoup = soup.find_all('li')
for i in liSoup:
lis = BeautifulSoup(str(i), 'html.parser')
allMap[lis.find('a').text] = domain + lis.find('a').get('href')
soup = BeautifulSoup(html2, 'html.parser')
ResultSets = soup.find_all('h2', class_='group_title')
for ResultSet in ResultSets:
tt = re.match('''<h2 class="group(.*)title">(.*)</h2>''', str(ResultSet))
liSoup = soup.find_all('li')
for i in liSoup:
lis = BeautifulSoup(str(i), 'html.parser')
allMap[lis.find('a').text] = domain + lis.find('a').get('href')
# for k, v in allMap.items():
# print(str(k) + " " + str(v))
def getFirstLevel(pageUrl):
res = requests.get(pageUrl, headers=headers)
res.encoding = "utf8"
print(res.url)
# 打印出页面的所有代码
# print(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
ResultSets = soup.find_all('section', class_='ice_bg space_pr space_pl')
# 生成七类
getSevenPart(str(ResultSets[0]), str(ResultSets[1]))
# 分类放入map中
splitIntoSevenMap()
def accordingPartGetResults(name):
print(name)
# 热门
if name == "hotMap":
for k, v in hotMap.items():
print(str(k) + " " + str(v))
getPerResults(name, str(k), str(v))
# 基础典籍
elif name == "basicBooks":
for k, v in basicBooks.items():
print(str(k) + " " + str(v))
getPerResults(name, str(k), str(v))
# 养生保健
elif name == "health":
for k, v in health.items():
print(str(k) + " " + str(v))
getPerResults(name, str(k), str(v))
# 孤本
elif name == "orphan":
for k, v in orphan.items():
print(str(k) + " " + str(v))
getPerResults(name, str(k), str(v))
# 临症各科
elif name == "clinicalDepartments":
for k, v in clinicalDepartments.items():
print(str(k) + " " + str(v))
getPerResults(name, str(k), str(v))
# 争鸣流派
elif name == "chirp":
for k, v in chirp.items():
print(str(k) + " " + str(v))
getPerResults(name, str(k), str(v))
# 历代医家
elif name == "doctors":
for k, v in doctors.items():
print(str(k) + " " + str(v))
getPerResults(name, str(k), str(v))
def getPerResults(KeywordName, name, nameUrl):
try:
browser.get(nameUrl)
js = 'window.scrollTo(0,document.body.scrollHeight)' # 下滑到底部
try:
try:
while browser.find_element_by_class_name('getMoreBtn') is not None:
browser.execute_script(js)
time.sleep(1)
browser.find_element_by_class_name('getMoreBtn').click()
except ElementNotInteractableException:
print("已经加载完毕")
except NoSuchElementException:
print("这个就一页")
time.sleep(1)
browser.execute_script(js)
webElement = browser.find_elements_by_class_name("book_wrapper")
bookCount = len(webElement)
print("书本的数量为 -> " + str(bookCount))
for i in webElement:
try:
bookUrl = i.find_element_by_tag_name('a').get_attribute('href')
except NoSuchElementException:
bookUrl = "没有给url"
try:
bookName = i.find_element_by_tag_name('a').text
except NoSuchElementException:
bookName = "没有给书名"
try:
bookAuthor = i.find_element_by_class_name('book-author').text
except NoSuchElementException:
bookAuthor = "没有给作者名字"
try:
bookDescription = i.find_element_by_class_name('book-description').text
except NoSuchElementException:
try:
bookDescription = i.find_element_by_class_name('book-comment').text
except NoSuchElementException:
bookDescription = "没有给书的描述"
print(str(name) + "中的----> " + str(bookName) + " " + bookUrl + " " + str(bookAuthor) + " " + str(
bookDescription))
browser2.get(bookUrl)
time.sleep(1)
try:
digest = browser2.find_element_by_css_selector(
"#book_abstract > div.abstract-wrapper-div.abstract_wrapper_div.abstract-wrapper-divnew > div")
except NoSuchElementException:
print(str(bookName) + "的摘要是使用了第二种方式")
digest = browser2.find_element_by_css_selector(
"#book_abstract > div.abstract_wrapper_div > div")
finally:
pass
catalog = browser2.find_element_by_xpath('''//*[@id="book_catalog"]/table/tbody''')
trLists = catalog.find_elements_by_tag_name('tr')
Text = ""
for tr in trLists:
Text = Text + str(
tr.find_element_by_tag_name('td').find_element_by_tag_name('a').get_attribute('innerHTML')) + " "
toMongoDB(KeywordName, name, bookCount, nameUrl, bookName, bookUrl, bookAuthor, bookDescription,
digest.text, Text)
time.sleep(1)
finally:
print(str(name) + " 已经爬取完毕")
pass
if __name__ == '__main__':
page1 = 'https://www.zk120.com/ji/group/?nav=ys'
getFirstLevel(page1)
# 下面的是依次获取每种分类的具体信息 需要爬取哪个类的就取注
# accordingPartGetResults("hotMap")
# accordingPartGetResults("basicBooks") # 备查宝典有几条没查完 备查宝典里的中医人名词典这里一直卡死
# accordingPartGetResults("health")
# accordingPartGetResults("orphan")
# accordingPartGetResults("clinicalDepartments")
# accordingPartGetResults("chirp")
# accordingPartGetResults("doctors")