1.单个训练样本(损失函数)
在逻辑回归中我们需要做的就是变换参数w和b的值,来最小化损失函数
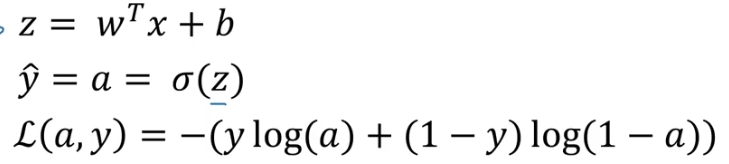
a也就是sigmoid函数,也就是a=1/(1+e^(-z)),所以dL/dz=dL/da * da/dz = a-y
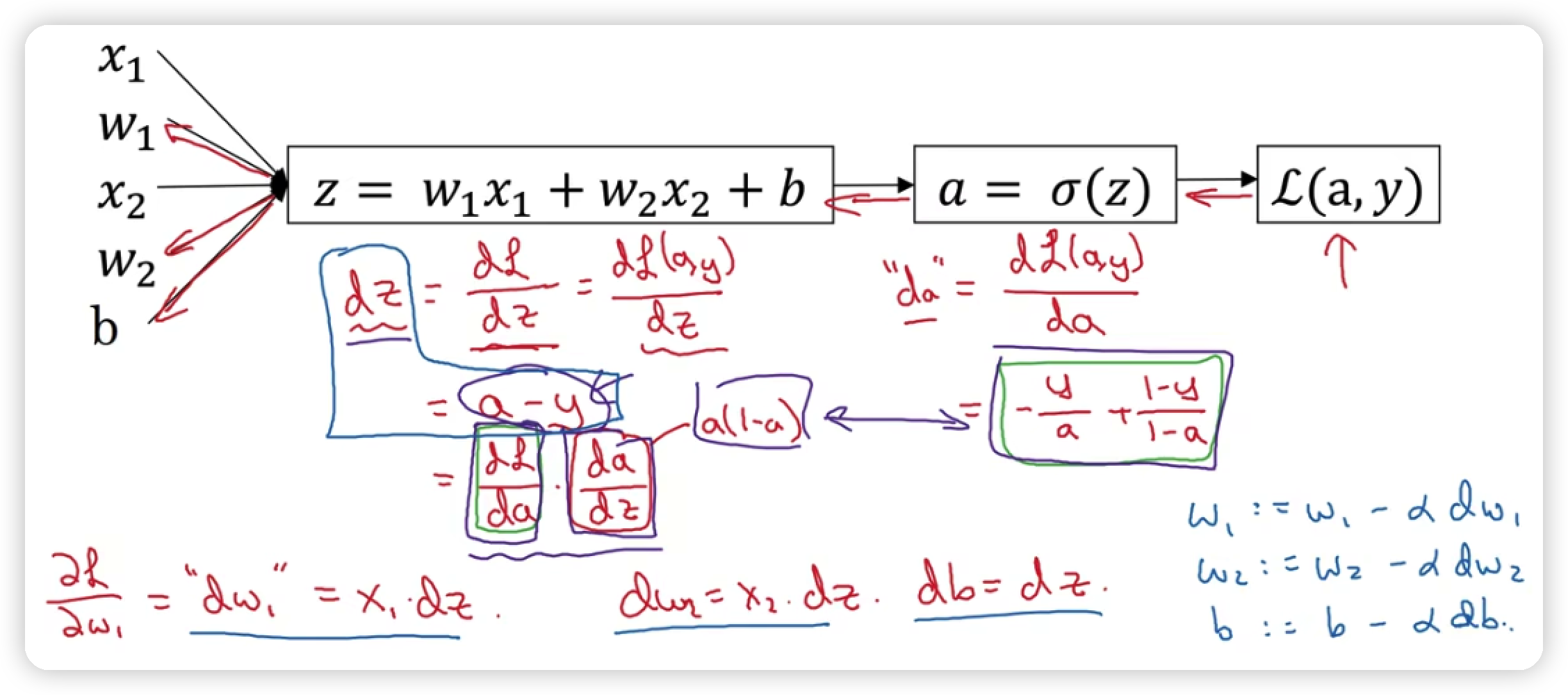
这就是单个样本实例的一次梯度更新的步骤
2.多个训练样本
下图中有一个很明显的问题就是如果特征数量比较多for循环显示化会导致代码效率极低,因此为了解决这个问题,后面就引入了向量化的概念。
m是样本的数量,其中dw1,dw2,最终得到的值是在整个样本上得到的值,而dz的值则表示的是在第i个样本上得到的值