HDFS最重要的就是写流程了,学校老师教的时候也是重点介绍这个过程(虽然我并没有在任何面试中被问到过)。下面从画图和文字两个过程介绍写流程,这次读了源代码之后对整个过程更加清晰了。
一、图解
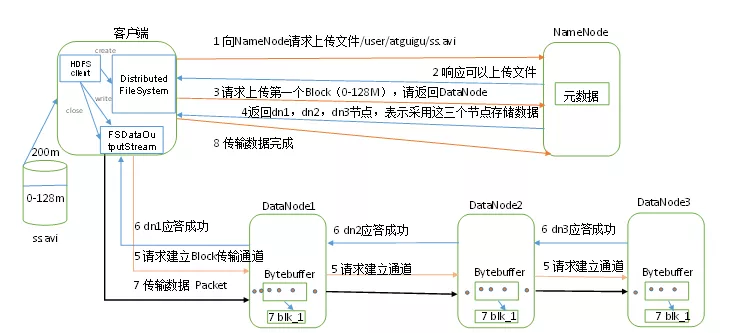
二、文字解说
HDFS客户端会先给NameNode发送请求上传文件a,代码层面上就是使用create方法,参数就是上传的文件路径,这个请求最本质的就是调用DFSOutputStream方法里的newStreamForCreate方法,这个方法总得就是返回一个DFSOutputStream对象,抽象层面上就是NameNode对请求进行了一个应答,源码层面上,newStreamForCreate干了两件事,第一件事就是通过RPC调用nameNode服务器上创建文件的操作,这个会返回一个status状态值,如果不合法则创建失败,那么DFSOutputStream对象也创建失败了,比如检查路径是否已经存在,如果存在是否可以覆盖,副本策略是否生效等,第二件事就是创建DFSOutputStream对象,这个创建过程会启动DFSOutputStream内部的一个DataStreamer线程,这个线程的run方法就是处理Data Queue队列信息以及向nameNode申请Block存储的节点信息以及创建对应的数据通信管道,总得如果没什么问题,我们自己写的create代码会返回一个由DFSOutputStream对象封装成的FSDataOutputStream对象,我们操作这个FSDataOutputStream对象进行write操作,回到顶层抽象层面,收到可以上传文件a的应答后,我们就向NameNode发送写数据请求,这个请求会唤醒之前说的DataStreamer线程,因为没写之前Data Queue数据队列是空的,进行wait操作(这里采用了生产者消费者模式),DataStreamer线程唤醒后执行run方法里,run方法有部分代码写的就是获取datanode,这里面也会通过RPC调用NameNodeRpcServer获取Block存储的节点信息,这里使用了就是机架感应策略,然后返回dn0,dn1,dn2,有了数据节点信息之后,DataStreamer还要干另一件事,与dn0建立输出流,具体的就是通过Sender类里的send方法通过socke发送Data queue中的packet,当然datanode中也会启动一个线程DataXceiverServer线程来工作,具体的就是BlockReceiver这个东西来写入磁盘,同时也会调用Sender里的send方法给下一个datanode交互,每次写入成功都会都会向前一个节点发出Responser应答,DataStreamer会处理这个应答,如果有这个应答,会将数据从ACK queue中移除,至此第一个block就结束了,之后的就是其他block的了,也是同理的。
上一段没有讲讲我们调用的write方法,进入源码里,首先是写chunk,然后将chunk包装为packet,在写入datastreamer里的data queue里。
三、源码追踪

HDFS写流程主要是这两个方法
建议点进去看看,具体的流程图等我有时间再补补。重要的代码太多了也不方便截图,感兴趣的同学可以看看《Hadoop2.x HDFS源码剖析》
这个源码写的还是很牛的,需要掌握基础的多线程知识以及RPC知识,同时也要明白生产者消费者模式。







![[.Net 6] RabbitMQ入门看这篇就够了](https://s2.loli.net/2022/04/23/SaWzHiQk8Bu1fG5.png)