1、inode和block概述
block:操作系统在读取硬盘的时候,会一次性读取一“块”(block),这种块是文件存取的最小的单位,block的大小常见的是4KB,即八个扇区构成。(硬盘的最小存储单位叫做扇区,每个扇区存储512字节,而连续的8个扇区组成了一个块)
inode:文件储存在block中,还必须找到一个储存文件的元信息,比如文件的创建者、创建日期、文件大小等等。这种储存文件元信息的区域就是inode。
2、inode由哪些信息组成
inode包含文件的属性信息有以下内容:
- 文件的字节数
- 文件拥有者的id
- 文件所属组id
- 文件的读写执行权限
- 文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动时间,atime指文件上一次打开时间。
- 链接数,既有多少个文件指向这个inode。
- 文件数据块的位置。
inode也会消耗硬盘空间,所以硬盘格式化的时候,操作系统自动将硬盘划分为两个区域。一个是数据区,存放文件数据,另一个是inode区(inode table),存放inode所包含的信息。
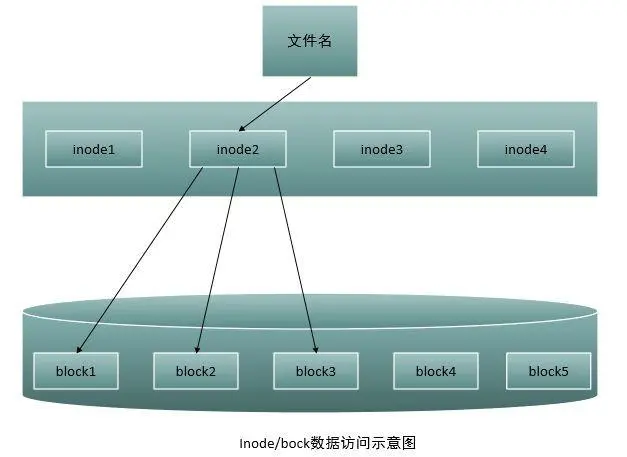
每一个文件都有一个inode,每个inode都有一个号码inode_num,操作系统用inode号码来识别不同的文件。
3、Linux打开文件原理
linux系统内部不使用文件名,而使用inode号码来识别文件,对于系统来说,文件名只是inode号码便于识别的别称,在我们的操作系统中表面上是通过文件名打开文件的,实际上分为以下三步:
- 查找文件名对应的inode号
- 通过inode号获取inode信息
- 根据inode信息,找到文件数据所在的block,读出数据
4、inode相关命令实操
下面我们为了更详细了解inode号,对其进行一系列实际操作。
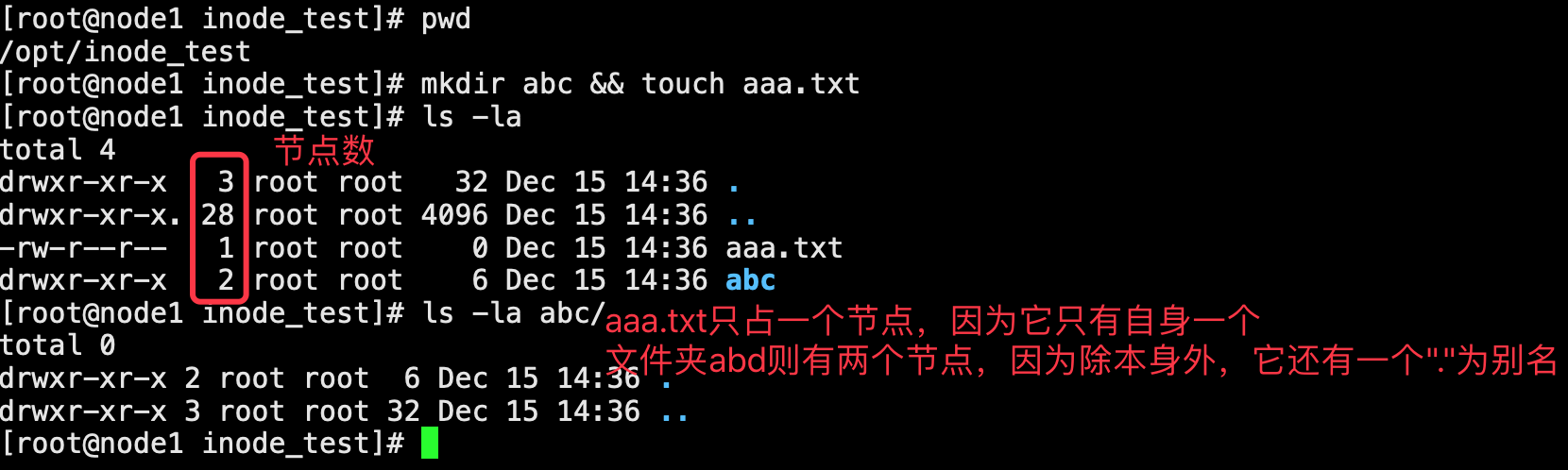
首先我们在/opt/inode_test下创建一个abc目录和aaa.txt文件然后用“ls -l”命令查看并对比他们之间的节点数。
查看节点号我们可以使用的有两个命令分别是“ls -i” 和“stat 要查看的文件”,前者只能单独查看文件的节点号,而后者在除了查看节点号外还可以查看文件的其他的一些详细信息。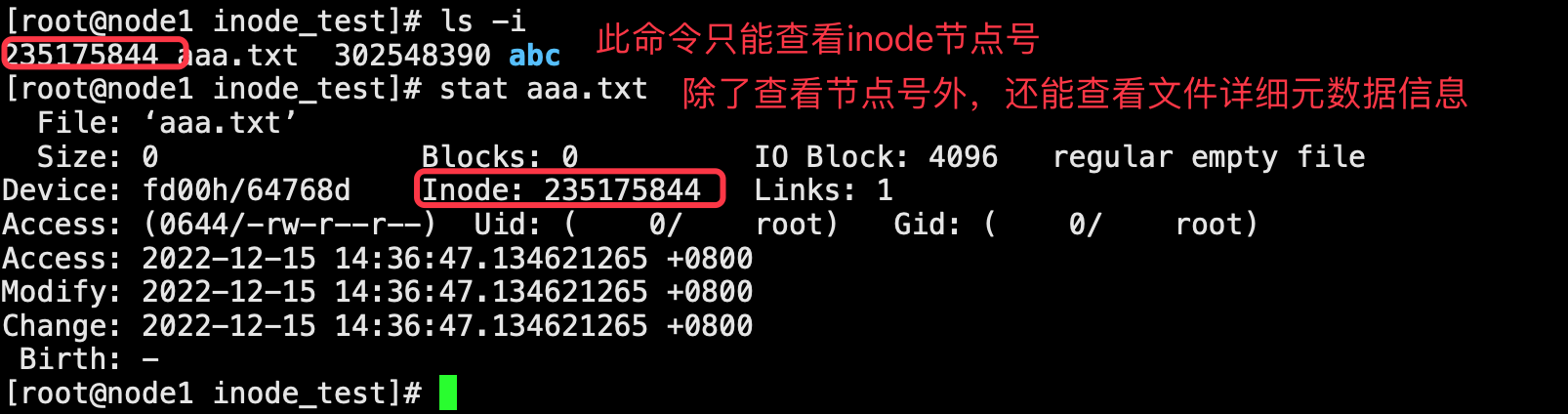
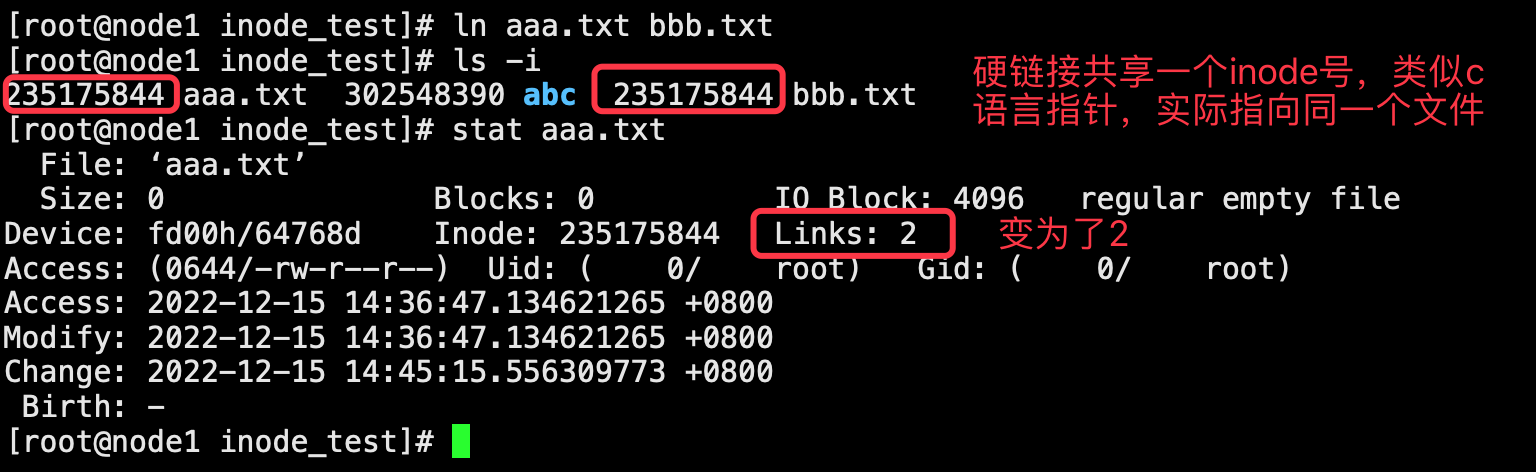
给一个文件创建一个硬链接后,二者在目录中分别属于两个文件,但是共享同一个节点号的。(硬链接详细介绍见:Linux 软链接和硬链接)
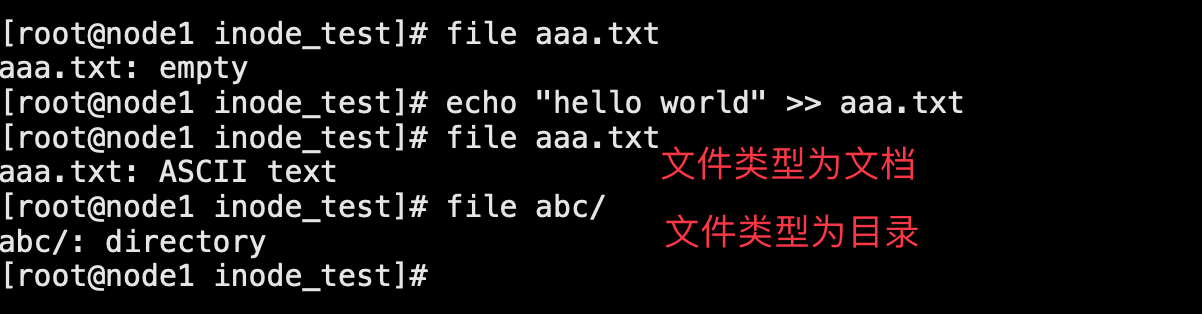
这里我们还有两条命令是可以查看文件类型的分别是“file 文件”和“ls -l”。前者可以直白的显示出文件的类型,后者则可以通过权限前面的符号来分别该文件是目录还是文档,当然除了这两种还有一种比较常见的,那就是根据文件显示的颜色来分辨。

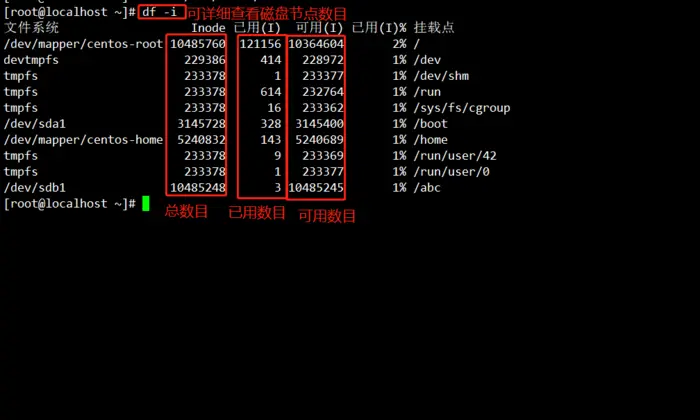
前面讲了如何查看文件的节点号,这里我们在讲一下磁盘的节点数目。此时磁盘sdb1共有一千多万节点,而且只使用了三个。
接下来我们进入目录abc并在其中创建十万个空文档。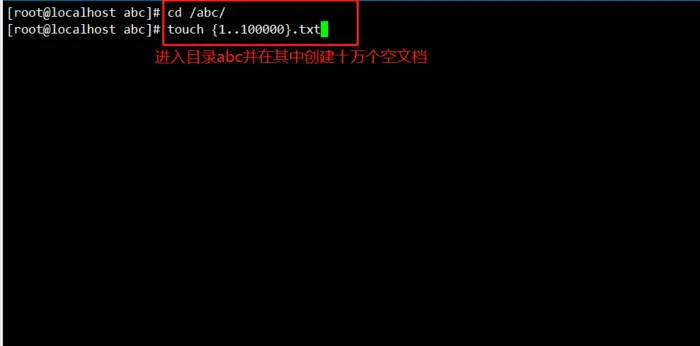
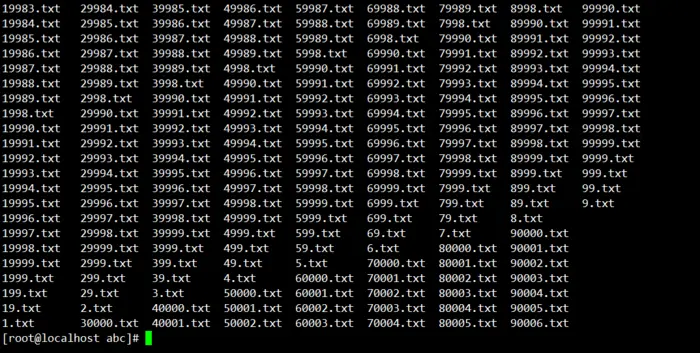
一个文档占据的就是一个节点,所以此时我们sdb1就已经使用了十万个节点了,占据总结点数百分之一,但内存只占据了80M,与节点数并不成正比,所以这也是我们实际情况中能见到的一种方式,使用空文档占满别人磁盘的节点,虽然磁盘空间还剩余很多但却已经写不进东西了。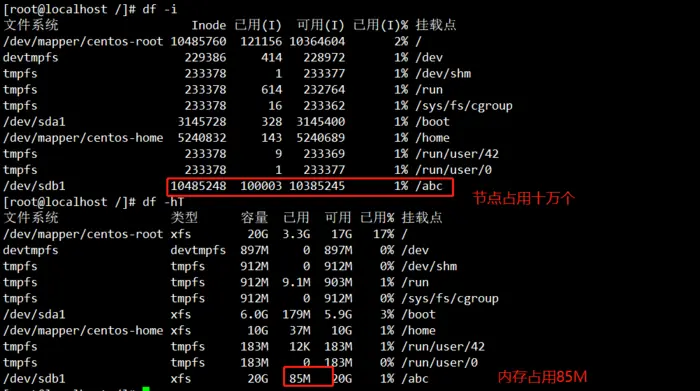
5、硬盘空间大小和inode数量关系
df -i 可以看到总量、可用、已用inode数量,一般来讲,mkfs的时候,会划分 x% 的空间存放inode的,可用inode数量是按照文件个数计算的,不是按照占用空间计算的,如:

500GB的磁盘,格式化为xfs后,可以使用的inode数量约 2.6亿; 那么1GB的磁盘格式化为xfs后,可用inode数量为 2.6亿/500 ~= 50万吗?测试如下:
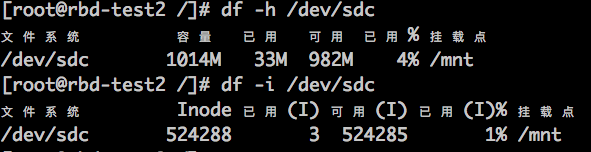
确实,1GB默认可以存放约52万个文件,注意: 目录也是占用inode的,而且也不可能把所有文件都放在一个目录的,所以真正计算inode的话,还需要把目录的数量算上。
另外,xfs是个比较智能的文件系统,没有固定大小的inode区域,随着磁盘的使用,inode的总数量也在变化,基本不会出现inode已用光,但是存储空间很空闲很多的情况。
6、节点inode 使用率
每个文件都必须有一个 inode,用于储存文件的元信息,比如文件的创建者、创建日期,inode 也会消耗硬盘空间,大量的 cache 小文件也容易导致 inode 资源被使用耗尽。并且,有可能发生 inode 已经用光,但是硬盘还未存满的情况,此时就无法在硬盘上创建新文件。
而 inode 使用率的监控恰好就可以预先发现上述提到的这类情况,帮助用户知道集群 inode 的使用情况,防止因 inode 耗尽使得集群无法正常工作,提示用户及时清理临时文件。

7、总结
linux系统每个文件都必须有一个 inode,用于储存文件的元信息,比如文件的创建者、创建日期。linux系统内部不使用文件名,而使用inode号码来识别文件,对于系统来说,文件名只是inode号码便于识别的别称,在我们的操作系统中表面上是通过文件名打开文件的,实际上分为以下三步:
- 查找文件名对应的inode号
- 通过inode号获取inode信息
- 根据inode信息,找到文件数据所在的block,读出数据
另外,目前使用大部分操作系统都是使用xfs文件系统,xfs比较智能,没有固定大小的inode区域,随着磁盘的使用,inode的总数量也在变化,基本不会出现inode已用光,但是存储空间很空闲很多的情况。
参考:https://www.likecs.com/show-204143370.html
参考:https://blog.csdn.net/m0_71518373/article/details/125798445