元素的定位:
- 针对web而言,获取的每一个页面都是一个html页面;是由一系列标签所构成(html),而标签中又具有属性(键值对的形式存在的);
- 基本控件:文本框、下拉列表框、单选框、复选框、超链接、表格table、图片、按钮等
-
a常规的定位方式:八种:其语法(老语法)find_element_by_指定的类型(对应类型的属性值)
- 1.id定位方式:id一般在设计过程中都是设定为唯一标识;
- 问题:那么是否所有的定位都可以使用id完成?
- 分析:并不是所有的标签都存在id属性、还有id可能是动态的值
- 2.class定位方式:类名可以存在重名的;且类名的表现形式在标签中是以包、类名的形式存在的;那么针对该类型的类进行定位时只需要选择除了空格以外的其中一部分内容即可;
- 3.name定位方式:name也可以存在重名;在定位过程当中需要确保当前的name的值是唯一的;(如果多个元素的name属性都相同,那么就得需要使用过滤器进行进一步细化定位)
- name定位方式将会识别首个name属性等于定位值的页面元素。
- 以上三种属性是较为常用的,因为在实际前端开发过程中都会定义id、name、class
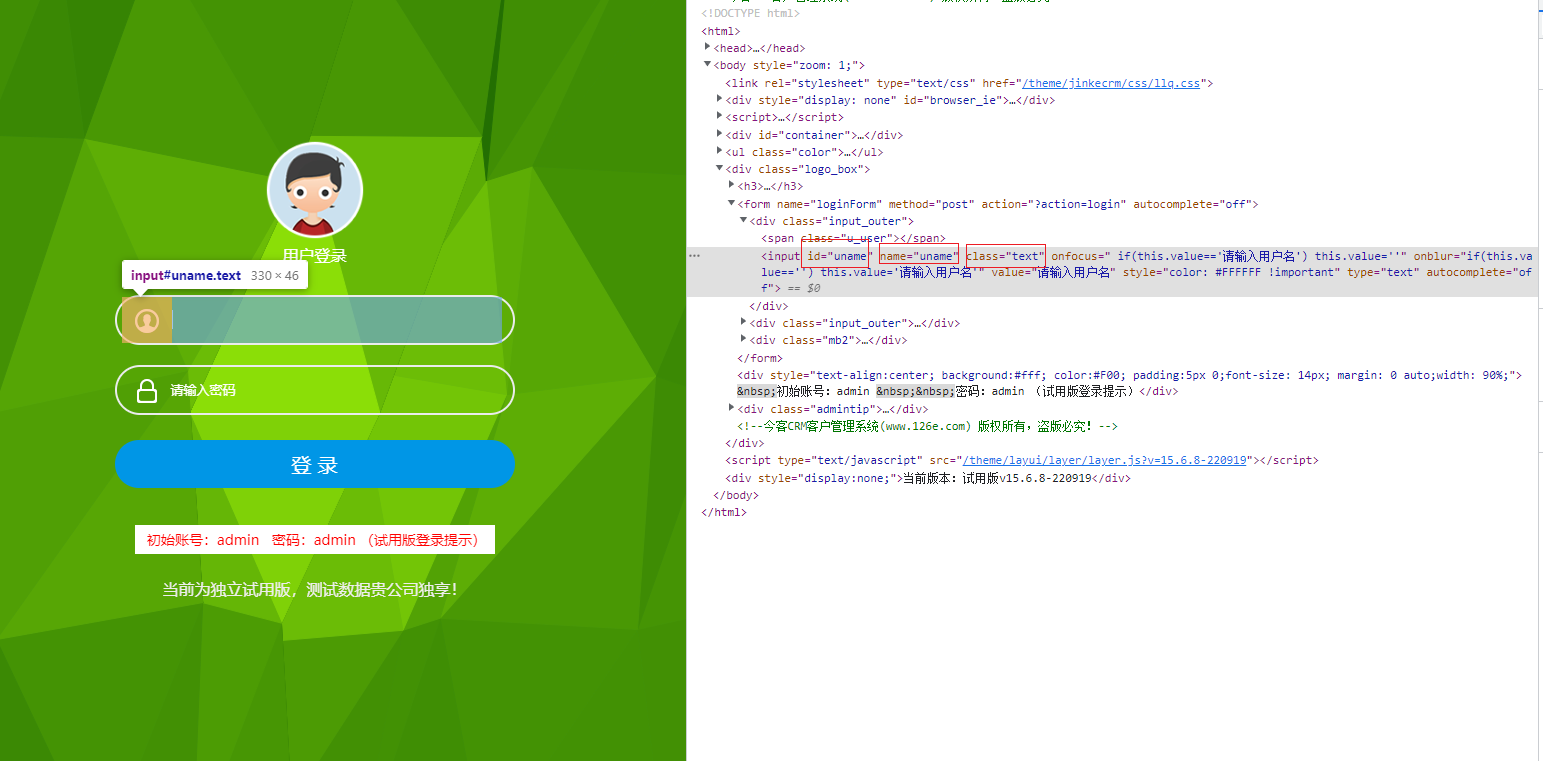
- 4.文本定位方式:link_text 一般针对的是超链接的文本进行定位
- partial_link_text定位是link_text的一种补充,有些文本较长时,可以提出文本的一部分进行定位,只要这一部分信息可以被唯一标识即可。
- 5.标签进行定位:tag_name:进行定位;一般都使用一组元素进行定位find_element_by_tag_name较少(使用find_elements_by_tag_name应用较多)

注意事项:1.如果在整个定位元素古过程中出现元素位置不存在的情况的话可能原因:元素定位方式真的错了、上下文操作、当前操作的页面数据加载没加载完成;
- 6.xpath定位方式:表示的由xml(extend markup language)可扩展标记语言,也是由一系列标签所构成,主要是实现数据文件(用于做配置文件))+path,以xml格式的树状结构形式进行递归逐级定位
- xpath的定位方式两种方式:绝对路径定位、相对路径定位
- 绝对路径:从顶级父标签到当前标签的整个路径结构称之为绝对路径;
-
- 在使用绝对路径时,如果同级中存在多个相同的标签的话,则通过索引进行具体选择(其索引的初始值是从1开始);但是在实际脚本开发过程中,一般不用,因为如果使用绝对路径则跨度较大,只需要页面稍微修改结构则整个定位失败;(稳定性极差)
-
- 相对路径:表示的是相对于当前标签而言的路径结构;
-
- i.属性定位语法://标签名[@属性名=属性值]
-
- 注意:1.标签名可以具体,也可以使用*(表示的任意标签,定义的范围会比具体的标签更广,可能定位多个对象) 2.属性值如果是字符串的话则需要使用引号;
-
value='//*[@id="uname"]'
-
- ii.使用逻辑运算符进行实现多个属性的定位:and or not
-
- 例子:
//input[@id="uname" and @class="text"]
- 但是一般组合的属性不会超过2个,因为设定属性过多其脚本的依赖性越高;
- 例子:
-
- iii.嵌入函数完成xpath定位:
-
- 1.文本函数定位://标签名[text()=对应标签的文本内容]2.包含函数定位:
- 文本内容中是否嵌入标签、文本内容表示的完整文本;
- 例子:
# 如果定位得到其中的一个元素,则该对象可以获取所有的其他属性信息
get_element=driver.find_element(by=By.XPATH,value='//label[text()="请输入密码"]')
print(get_element.get_attribute("class"))
- 2.包含函数定位://标签名[contains(@属性名,对应属性值的部分值)]
- 例子:
#3.通过属性值中的部分值进行定位
driver.find_element(by=By.XPATH,value='//input[contains(@id,"na")]').send_keys("admin")
- 例子:
- 3.以指定字符开头定位://标签名[starts-with(@属性名,对应属性名的前面部分值)]
- 例子:
-
#4.以指定字符开头定位
driver.find_element(by=By.XPATH,value='//input[starts-with(@id,"un")]').send_keys("admin") - 4.以指定字符结尾定位://标签名[ends-with(@属性名,对应属性名的前面部分值)]
- 说明:一般starts-with,ends-with都可以使用contains完成;
- 1.文本函数定位://标签名[text()=对应标签的文本内容]2.包含函数定位:
-
- i.属性定位语法://标签名[@属性名=属性值]
-
7.css定位方式:css表示的是层叠式样式;css定位方式效率更高;
- a.id定位表示方式:#+id的值
- b.class定位表示方式:.+class的值
- c.element1 > element2(element1 element2 ):表示的是指定element1下面的所有element2元素
- nth-child(n)表示指定父元素的第几个子元素、last-child:表示的是指定父元素的最后一个元素、first-child:表示的是指定父元素的第一个子元素
b.针对属性完全一致的且标签也一致,但是又存在id、name、class等属性的话则可以使用一组元素定位方式进行定位;find_elements_by_指定的类型;其返回的是指定类型的一组对象,然后可以通过其索引调用具体对象完成;
c.定位方式的另外一种表示形式:
- 新的方法:
导入包
from selenium.webdriver.common.by import By
实例:
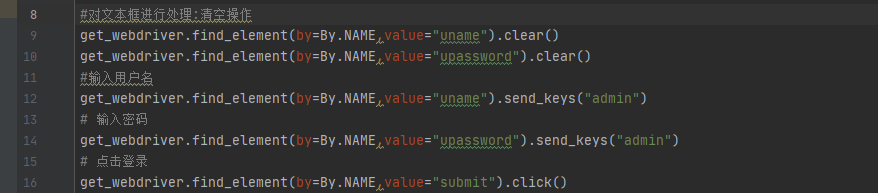

可以实现find_element()方法进行定位;该种方法需要传入参数,第一个参数表示的是定位的方式,第二个参数是定位方式所对应的值;
实际find_element_by_指定类型等多个方法使用find_element()一个方法进行完成;
第一个参数需要引入By模块;该模块显示如下::from selenium.webdriver.common.by import By
高级定位方式:
d.父子定位、二次定位:
父子定位:如果当前标签或者子标签中不存在任何属性可以作为定位的方式时,则可以查找当前标签的父标签是否存在相应的可定位属性,如果父级还没有则可以查找上一级,以此类推,直到查找到可定位的标签为止

#父子定位:
get_webdriver.find_element(by=By.XPATH,value="//form[@name='loginForm']/div/input[@id='uname']").send_keys("admin")
二次定位:可以先定位到可定位的其中一级标签获取对象,然后再通过该对象进行作为基准再次定位(二次定位实际就是实现多个节点的划分,通过节点进行进一步明确定位的标签和元素)
#二次定位
# get_webdriver.find_element(By.XPATH,"//form[@name='loginForm']").find_element(By.XPATH,value="//div/input[@id='uname']").send_keys("admin")
e.通过js脚本进行定位:
- 1.getElementByld、getElementsByName,getElementsByClassName、getElementsByTagName、getQuerySelectorAll
- 以上方法都属于document对象的方法;document表示的是实际就是当前html页面的对象;
-
#js定位方式:
get_ById="document.getElementById('uname').value='admin'"
#执行js脚本
get_webdriver.execute_script(get_ById) -
get_webdriver.execute_script("document.getElementsByName('submit')[0].click()")- 注意:
- 1.在使用以上方式进行定位时,注意Name,ClassName,TagName,QuerySelectorAll返回的对象都是复数形式;所以需要通过索引进行获取其具体对象;
- 2.针对文本赋值的是该方法调用value属性,如果是按钮的话则直接使用click()方法
2.通过定位元素获取对应的对象,但是该对象无法直接完成某些事件的操作,则可以通过该对象调用该标签中所申明的操作事件的属性值(js脚本完成),则获取该属性后可直接使用execute_script进行执行即可;
f.对隐藏元素的相关操作;
- 隐藏元素如何进行定位?---面试经常问到
- 此句话是错误的描述;因为隐藏元素实际是可以被定位到,其定位方式与普通元素定位方式完全一样;只是无法直接对元素进行操作而已;
- 问题实际是:隐藏元素如何操作?
- 可以通过js脚本定位到该元素获取对应的元素对象,然后通过其removeAttribute和seAttribute两个方法完成属性的删除或者重新赋值操作即可将当前的元素进行显示,显示即可操作;但是在实际操作中是不存在此种场景(可能由某一个功能触发该属性的值发生变化);
- demo网页:
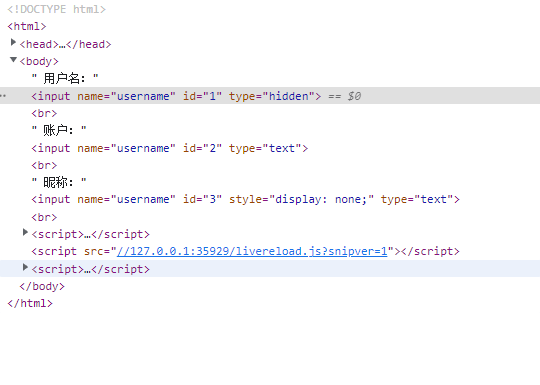
- 界面展示:
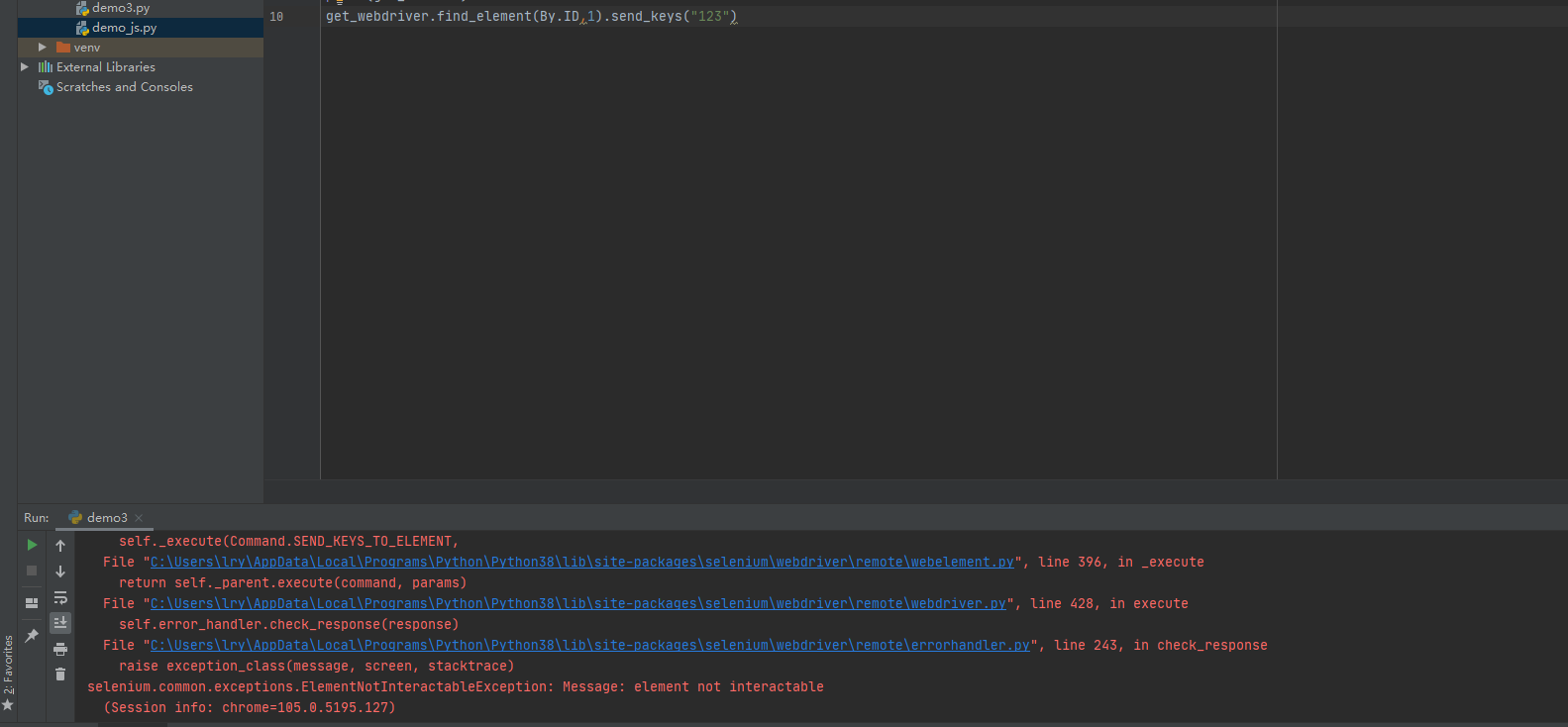
- 此时可以定位到元素

- 但是不可以对其进行操作(报错提示显示的是元素不可见)
- 解决方法:
-
#使用js脚本中的removeAttribute移除属性1
get_webdriver.execute_script("document.getElementById(3).removeAttribute('style');")
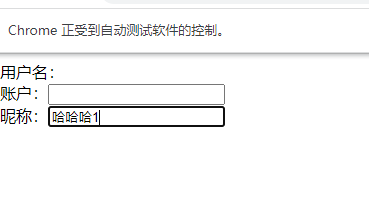
get_webdriver.find_element(By.ID,3).send_keys("哈哈哈") 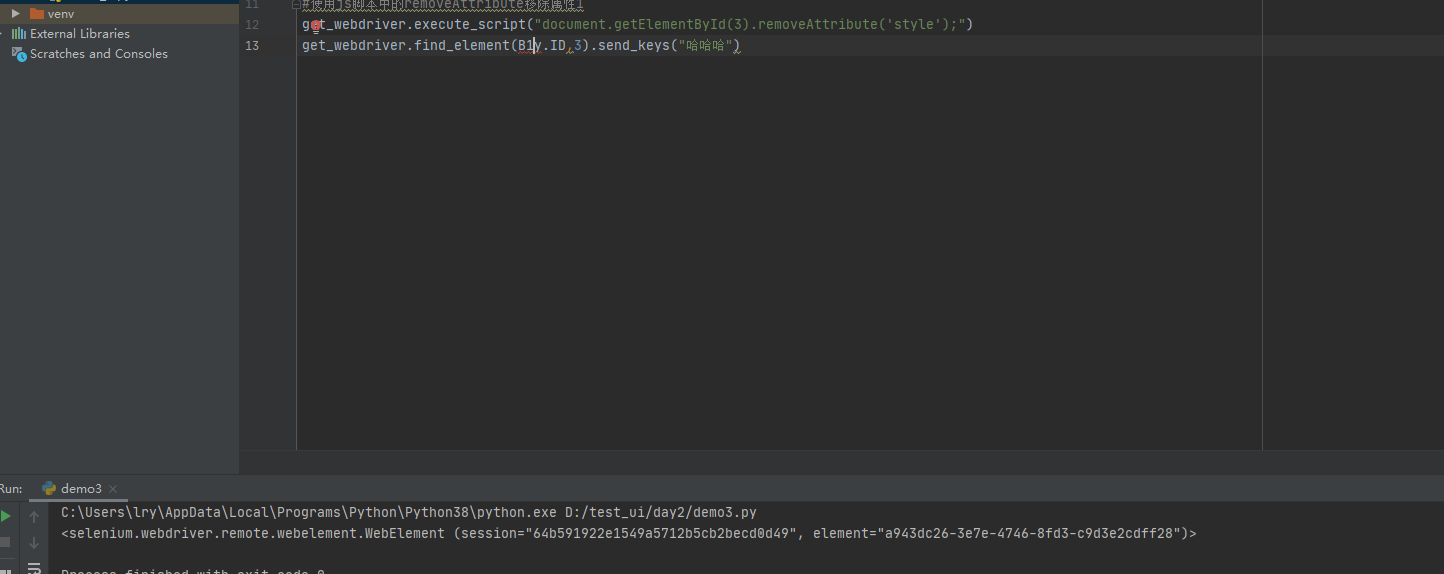
- 展示效果图:
-
浏览器的滚动条操作:浏览器滚动条是无法直接进行定位,所以也需要借助js脚本完成操作;
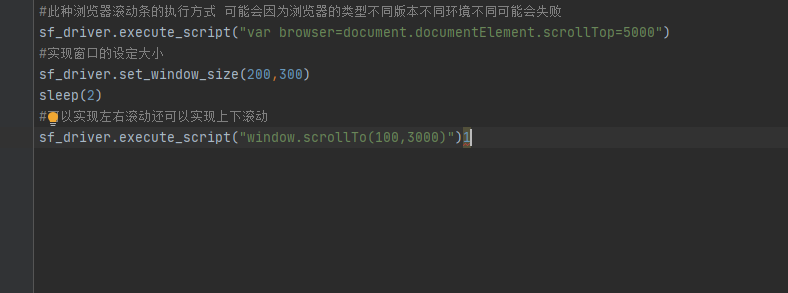
- 1. 指定上下滚动的高度;#此种浏览器滚动条的执行方式 可能会因为浏览器的类型不同版本不同环境不同可能会失败
sf_driver.execute_script("var browser=document.documentElement.scrollTop=5000) -
2.可以实现左右滚动还可以实现上下滚动;调用的脚本是我window.scollTo(x,y)其中x表示的是横向滚动,y表示的是纵向滚动;表示的是相对于原点进行滚动
sf_driver.execute_script("window.scrollTo(0,500)")
- 效果展示:
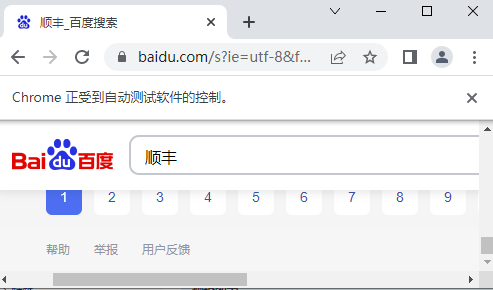
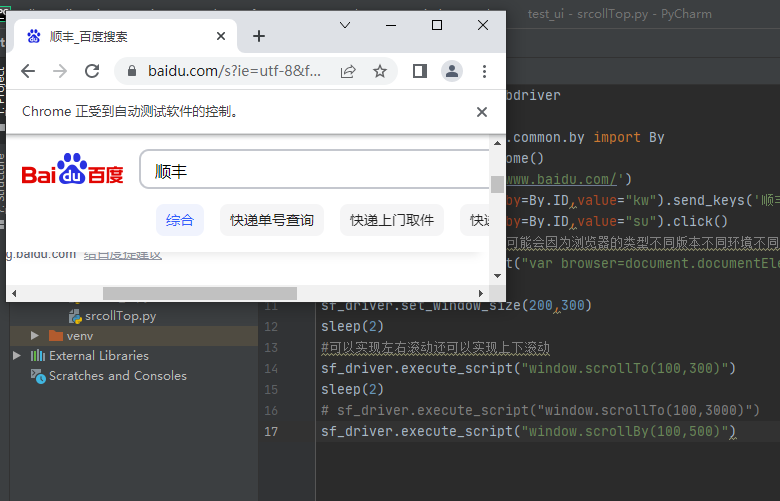
注意:第二种方法不具备叠加滚动的功能

window.scrollBy(x,y):表示的是相对当前的坐标点进行再次滚动指定的x,y坐标的值;
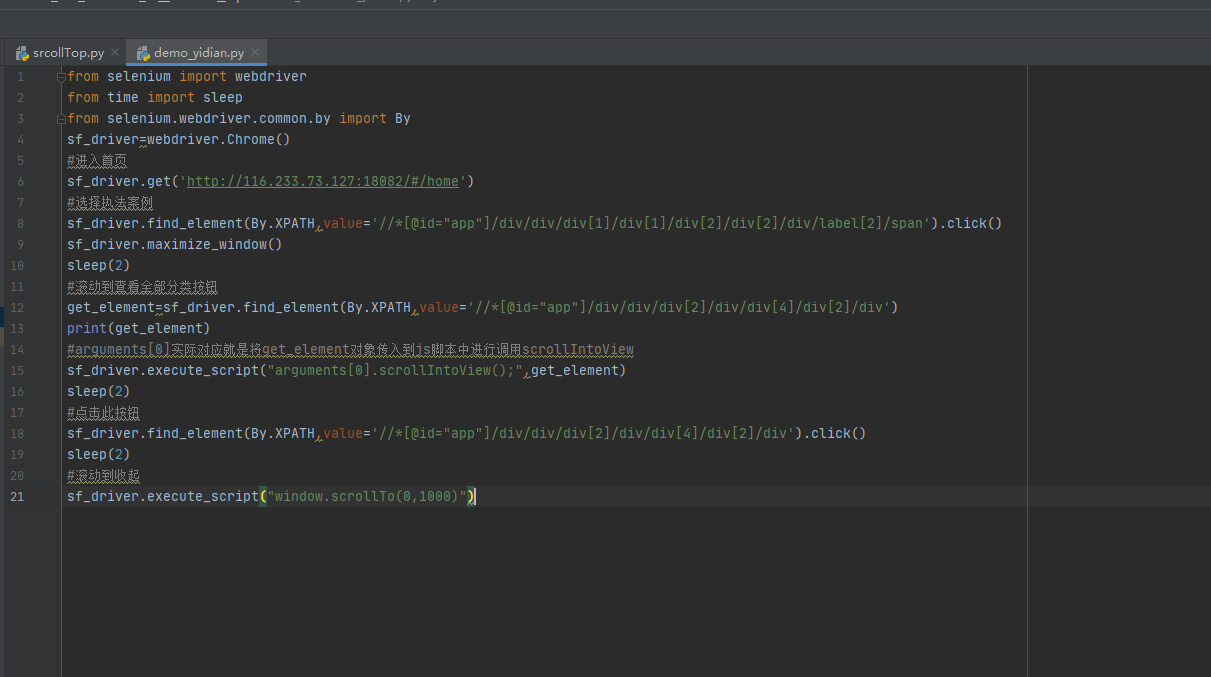
- 3.不考虑其横向滚动还是纵向滚动的坐标值,直接滚动到指定的元素位置;
- 使用的脚本语法:arguments[0].scrollIntoView();其中arguments[0]表示的是传入的定位参数的对象,在执行execute_script方法时传入的第二个参数;等价于直接使用js脚本的元素进行定位:document.getElementById("id的值").scrollIntoView();

demo: