一、xpath:下图中,页面内容存储在页面元素中,可以使用xpath方法进行数据提取,具体事例参考下面几个链接的文字
1、https://www.cnblogs.com/becks/p/11335493.html
2、https://www.cnblogs.com/becks/p/11440333.html
3、https://www.cnblogs.com/becks/p/12249920.html
4、https://www.cnblogs.com/becks/p/14289094.html
5、https://www.cnblogs.com/becks/p/15194300.html
6、https://www.cnblogs.com/becks/p/16628335.html

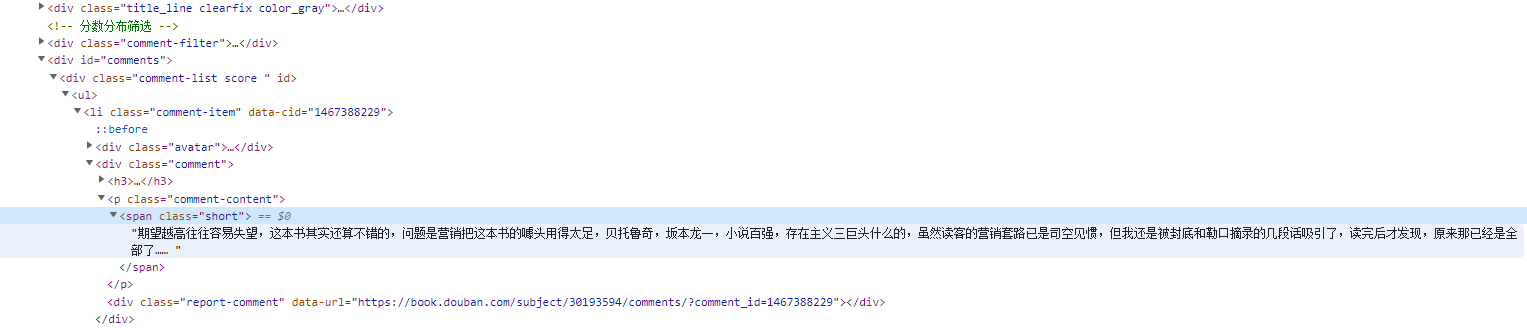
二、正则:上图内的页面结构,也可以通过正则方式取值,参考下面的链接
1、https://www.cnblogs.com/becks/p/12250310.html (这篇教程混合了xpath和正则取值)
2、https://www.cnblogs.com/becks/p/14500495.html
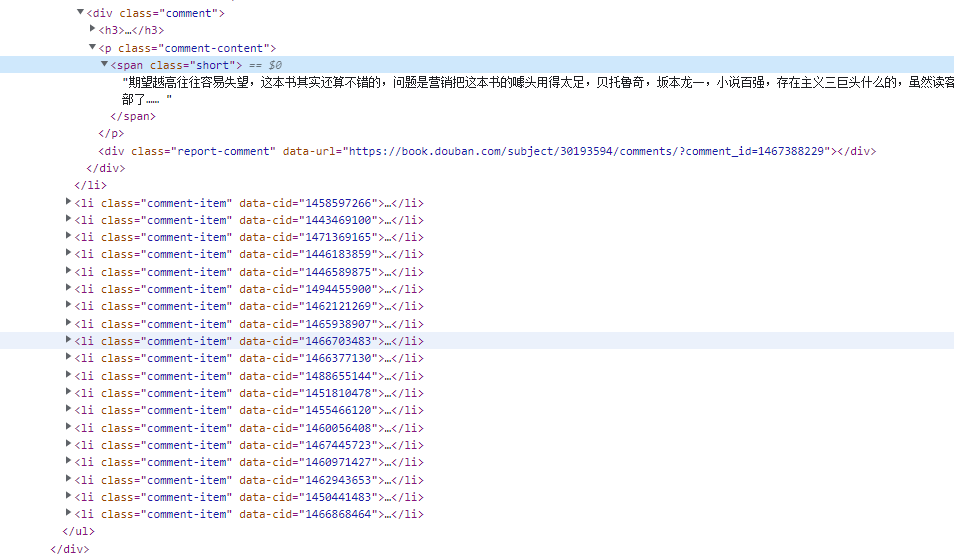
三、BeautifulSoup:如下图,内容存储在列表中,那么就可以使用BeautifulSoup方法标识一个相同的元素进行数据提取,具体参考:
1、https://www.cnblogs.com/becks/p/14540355.html
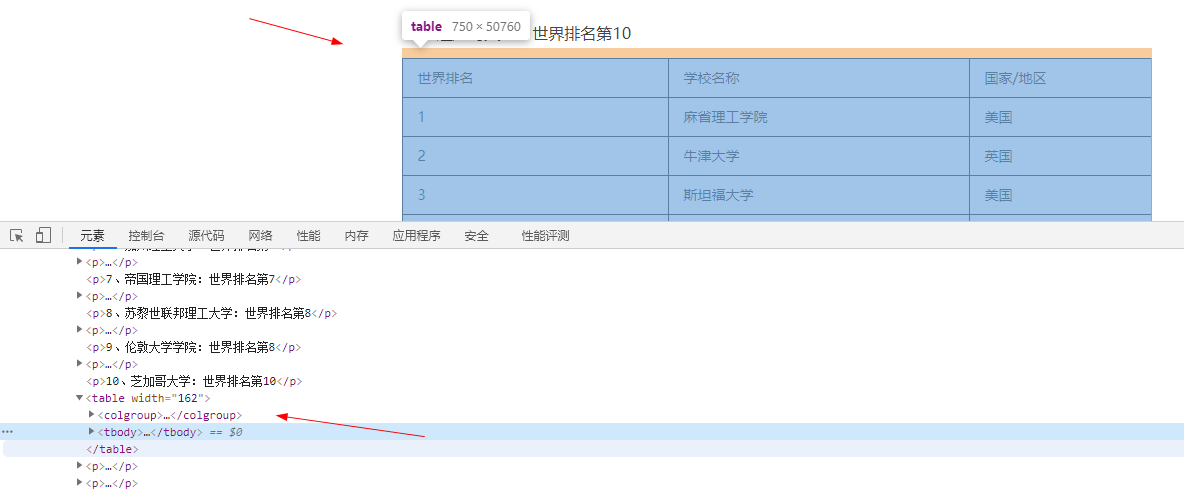
四、pandas:页面数据存储在tables中,可以使用pandas方法提取数据
1、https://www.cnblogs.com/becks/p/17125843.html
2、https://www.cnblogs.com/becks/p/14738496.html
3、https://www.cnblogs.com/becks/p/14743080.html
五、json:如果页面返回数据是json格式,那么可以直接提取json数据
1、https://www.cnblogs.com/becks/p/16349389.html
2、https://www.cnblogs.com/becks/p/16710968.html

六、css:同一,分析html页面结构数据
1、https://www.cnblogs.com/becks/p/17290681.html