数据抓取
上一节中,我们分析了网站的url,可以抓取视频的数据以及热词数据(搜索框提示数据)
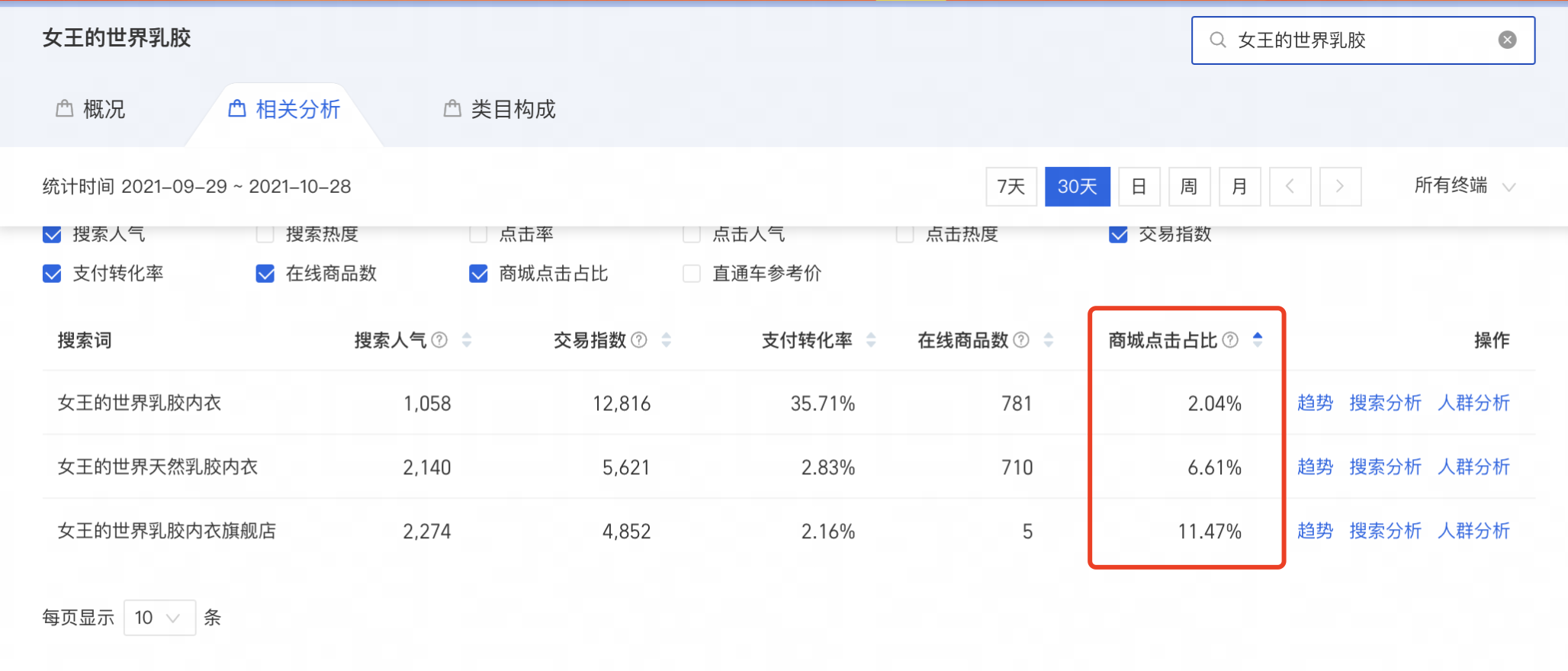
URL分析
分析一下视频数据的url
url = 'https://haokan.baidu.com/videoui/api/videorec?tab=yingshi&act=pcFeed&pd=pc&num=20&shuaxin_id=1608125768624'
其中的tab是我们在首页看到的视频分类标签的拼音缩写,后面的shuaxin_id看起来是一个时间戳,用来充当一个随机数,num表示一次获取几条数据
JSON数据格式分析
上一节中,我们从URL中获取到的数据中,有几个公共的字段
{
"errno": 0,
"error": "成功",
"data": {
"requestParam": [],
"response": {
"videos": [
{
"id": "5935263900090481104",
"title": "霸总怎么都想不到,他随手救下的小孩,居然是他的亲儿子!",
"poster": "https://tukuimg.bdstatic.com/processed/8e8086eb7cf3f54c90da2d590f652484.jpg@s_2,w_454,h_256,q_100",
"poster_small": "https://tukuimg.bdstatic.com/processed/8e8086eb7cf3f54c90da2d590f652484.jpg@s_2,w_454,h_256,q_100",
"poster_big": "https://tukuimg.bdstatic.com/processed/8e8086eb7cf3f54c90da2d590f652484.jpg@s_2,w_681,h_381,q_100",
"poster_pc": "https://tukuimg.bdstatic.com/processed/8e8086eb7cf3f54c90da2d590f652484.jpg@s_2,w_681,h_381,q_100,f_webp",
"source_name": "好剧渲染",
"play_url": "http://vd3.bdstatic.com/mda-kj6edbgpk3cs0qz4/cae_h264_nowatermark/1606875218/mda-kj6edbgpk3cs0qz4.mp4",
"playcnt": 549866,
"mthid": "1634935029156178",
"mthpic": "https://pic.rmb.bdstatic.com/bjh/user/94863b3c176d3223a379e0e206876aa0.jpeg?x-bce-process=image/resize,m_lfit,w_100,h_100",
"threadId": "1059000036007127",
"site_name": null,
"duration": "10:00",
"url": "https://haokan.baidu.com/v?pd=pc&vid=5935263900090481104",
"cmd": "baiduboxapp://v1/easybrowse/open?upgrade=1&type=video&url=https%3A%2F%2Fhaokan.baidu.com%2F%2Fv%3Fcontext%3D%257B%2522nid%2522%253A%25225935263900090481104%2522%257D%26backflow%3D1%26pd%3Dpc&style=%7B%22toolbaricons%22%3A%7B%22toolids%22%3A%5B%221%22%2C%222%22%2C%223%22%5D%7D%2C%22menumode%22%3A2%7D&newbrowser=1&slog=%257B%2522from%2522%253A%2522feed%2522%252C%2522page%2522%253A%2522sv%2522%257D",
"loc_id": "http://www.internal.video.baidu.com/5149be5226f83954df8b41ac83a9b546.html",
"commentInfo": {
"source": "baidumedia",
"key": "1679857347109984154"
},
"comment_id": "1679857347109984154",
"show_tag": 0,
"publish_time": "2020年10月07日",
"new_cate_v2": "影视",
"appid": "",
"path": "",
"channel_name": "",
"channel_total_number": "",
"channel_poster": "",
"like": 7628,
"fmlike": "7628",
"comment": "0",
"fmcomment": "0次播放",
"fmplaycnt": "55万次播放",
"fmplaycnt_2": "55万",
"outstand_tag": ""
},
]
}
}
}
其中的errno表示错误码,0表示没有出错,error表示错误信息,data是一个json对象,里面存储我们请求的数据和参数信息,我们用到的在data对象的response中,所以我们会做一下数据的基础封装。
响应数据的封装
基础响应数据
class BaseData:
"""
响应数据
requestParam list对象
response 响应数据
"""
def __init__(self,data):
self.requestParam = data.get("requestParam")
self.response= data.get("response")
def __repr__(self):
return "<Data>[%s,%s]" %(self.requestParam,self.response)
class BaseResponse:
"""
响应数据的基础类
"""
def __init__(self,errno,error,data):
self.errno = errno
self.error = error
self.data = data
def __repr__(self):
return "<Bese>[%d,%s,%s]" %(self.errno,self.error,self.data)
热词响应数据
class Hotword:
"""
热词
"""
def __init__(self,title,hotNum):
self.title = title
self.hotNum = hotNum
def __repr__(self):
return "<Hotword>[%s,%s]" %(self.title,self.hotNum)
视频响应数据
class CommentInfo:
"""
视频评论信息
"""
def __init__(self, data):
self.source = data["source"]
self.key = data["key"]
def __repr__(self):
return "<CommentInfo>[%s,%s]" % (self.source, self.key)
class VideoBean:
"""
视频数据
"""
def __init__(self, data):
self.id = data["id"]
self.title = data["title"]
self.poster = data["poster"]
self.poster_small = data["poster_small"]
self.poster_big = data["poster_big"]
self.source_name = data["source_name"]
self.poster_pc = data["poster_pc"]
self.play_url = data["play_url"]
self.mthid = data["mthid"]
self.playcnt = data["playcnt"]
self.mthpic = data["mthpic"]
self.threadId = data["threadId"]
self.site_name = data["site_name"]
self.duration = data["duration"]
self.url = data["url"]
self.cmd = data["cmd"]
self.loc_id = data["loc_id"]
self.comment_id = data["comment_id"]
self.show_tag = data["show_tag"]
self.publish_time = data["publish_time"]
self.new_cate_v2 = data["new_cate_v2"]
self.appid = data["appid"]
self.channel_name = data["channel_name"]
self.channel_total_number = data["channel_total_number"]
self.channel_poster = data["channel_poster"]
self.fmlike = data["fmlike"]
self.comment = data["comment"]
self.fmcomment = data["fmcomment"]
self.fmplaycnt = data["fmplaycnt"]
self.fmplaycnt_2 = data["fmplaycnt_2"]
self.outstand_tag = data["outstand_tag"]
self.commentInfo = CommentInfo(data["commentInfo"])
获取数据
import requests
import time
from bean.Bean import BaseResponse
from bean.Bean import Hotword
from bean.Bean import VideoBean
from bean.Bean import BaseData
def do_net(url, headers=None):
"""
获取网络数据,返回base对象
:param url:
:param headers:
:return:
"""
if not headers:
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"}
resp = requests.get(url=url, headers=headers).json()
base = parse_bean(resp)
return base
def parse_bean(data):
base = BaseResponse(-1, "", "")
base.errno = data.get("errno")
base.error = data.get("error")
base.data = BaseData(data.get("data"))
return base
def get_hot_words():
url = 'https://haokan.baidu.com/videoui/api/hotwords?sfrom=pc'
resp_bean = do_net(url=url)
if resp_bean.errno != 0:
print("获取数据失败!数据为:", resp_bean)
return
hot_words = []
data = resp_bean.data.response.get("hotwords")
for item in data:
hot_word = Hotword(item["title"], item["hot_num"])
hot_words.append(hot_word)
print("获取热词成功", hot_words)
def get_video_data():
url = "https://haokan.baidu.com/videoui/api/videorec?tab=yinyue&act=pcFeed&pd=pc&num=5&shuaxin_id=%d".format(
(int)(time.time() * 1000))
base = do_net(url)
if base.errno != 0:
print("获取数据失败!数据为:", base)
return
videos = []
for item in base.data.response.get("videos"):
videos.append(VideoBean(item))
print(len(videos))
print(videos)
if __name__ == '__main__':
get_hot_words()
get_video_data()
总结
由于从首页抓取视频分类失败,后面研究后再补上。
下一节,将我们抓取的数据写入数据库中