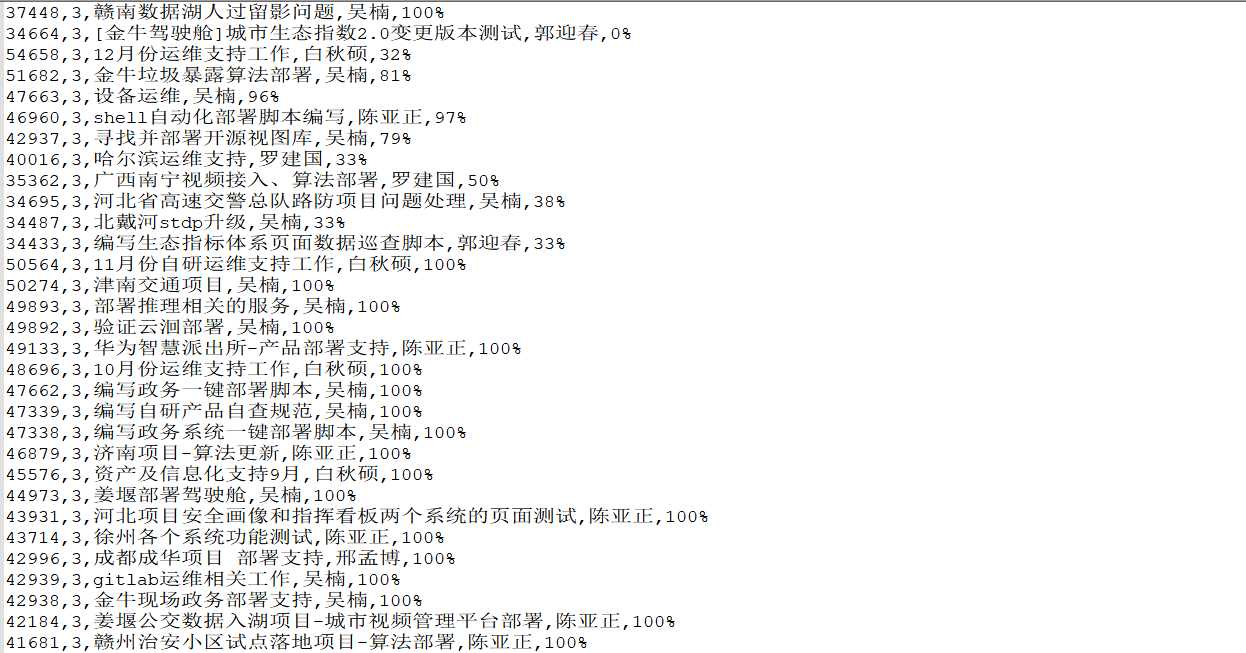
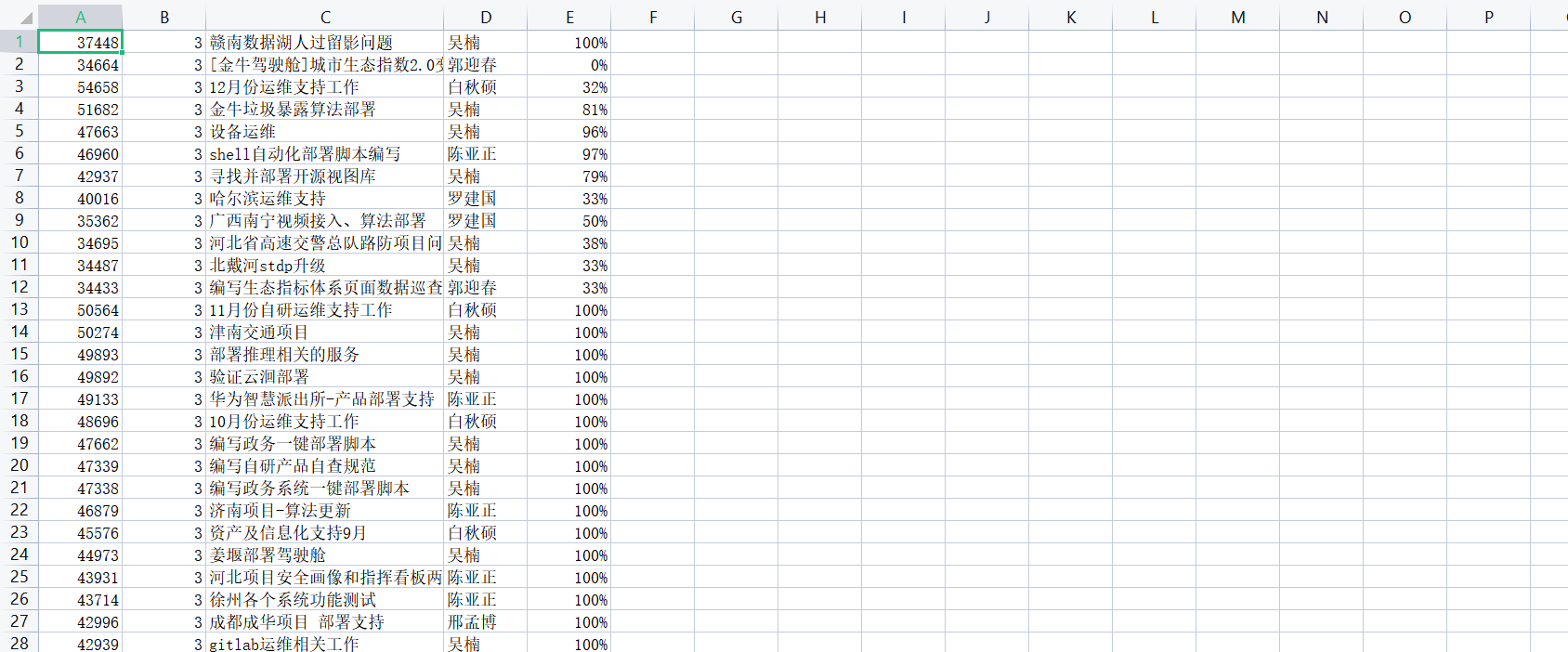
1、数据源
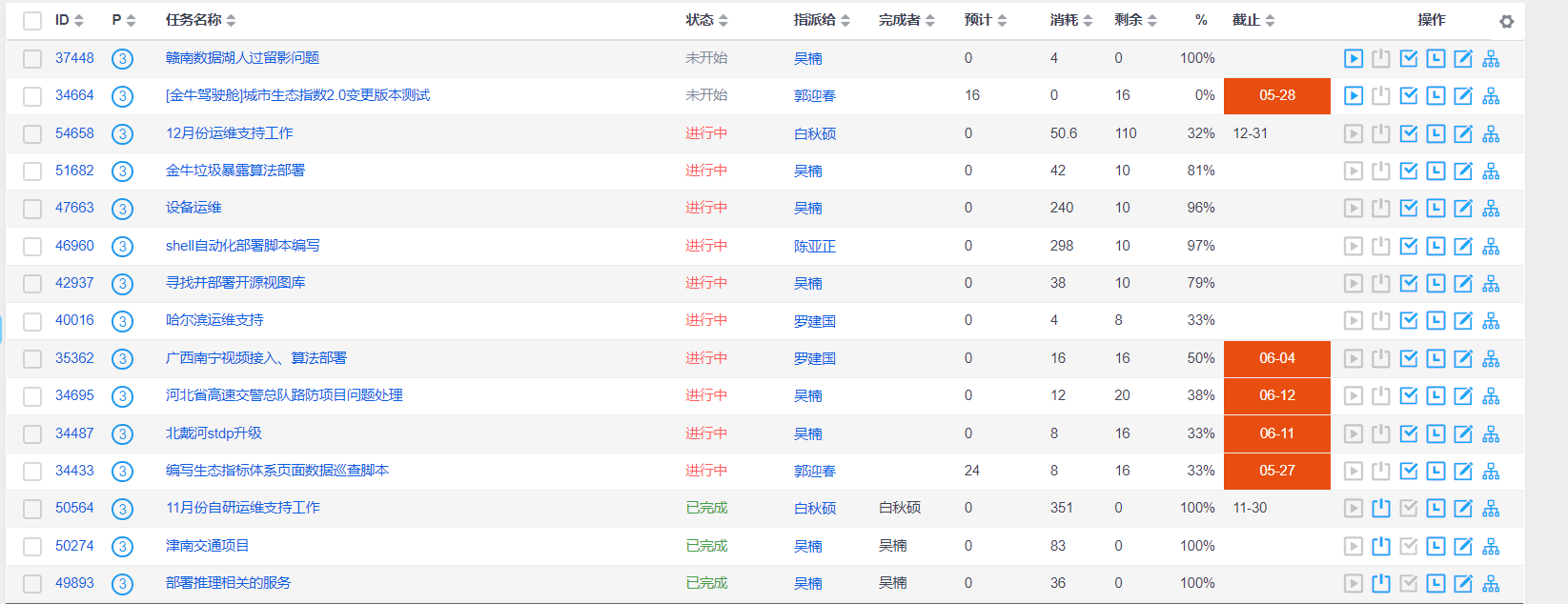
2、Python代码
import requests
from lxml import etree
import csv
url = 'http://211.103.175.222:5080/zentaopms/www/index.php?m=project&f=task&projectID=830'
headers = {
'Cookie': 'lang=zh-cn; device=desktop; theme=default; feedbackView=0; lastProject=830; preProjectID=830; lastTaskModule=0; projectTaskOrder=status%2Cid_desc; pagerProjectTask=2000; keepLogin=on; za=zhangyh01; zp=2a7befd1193619083ca09e00e186dc709a5722c2; windowWidth=1707; windowHeight=679; zentaosid=revjktmd869d6q7ilfhrjp1bpn'
}
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
tree = etree.HTML(res.text)
trs = tree.xpath('//*[@id="taskList"]/tbody/tr')
f = open('result.csv',mode='w',newline='') # newline='':防止保存的csv文件有空行
csv_writer = csv.writer(f)
for tr in trs:
id = tr.xpath('./td[1]/a/text()')[0]
jb = tr.xpath('./td[2]/span/text()')[0]
title = tr.xpath('./td[3]/a/text()')[0]
name = tr.xpath('./td[5]/a/span/text()')[0]
wcl = tr.xpath('./td[10]/text()')[0]
csv_writer.writerow([id,jb,title,name,wcl])
print('完成一行------------' + id,jb,title,name,wcl)
f.close()
print('全部完成')
3、执行过程
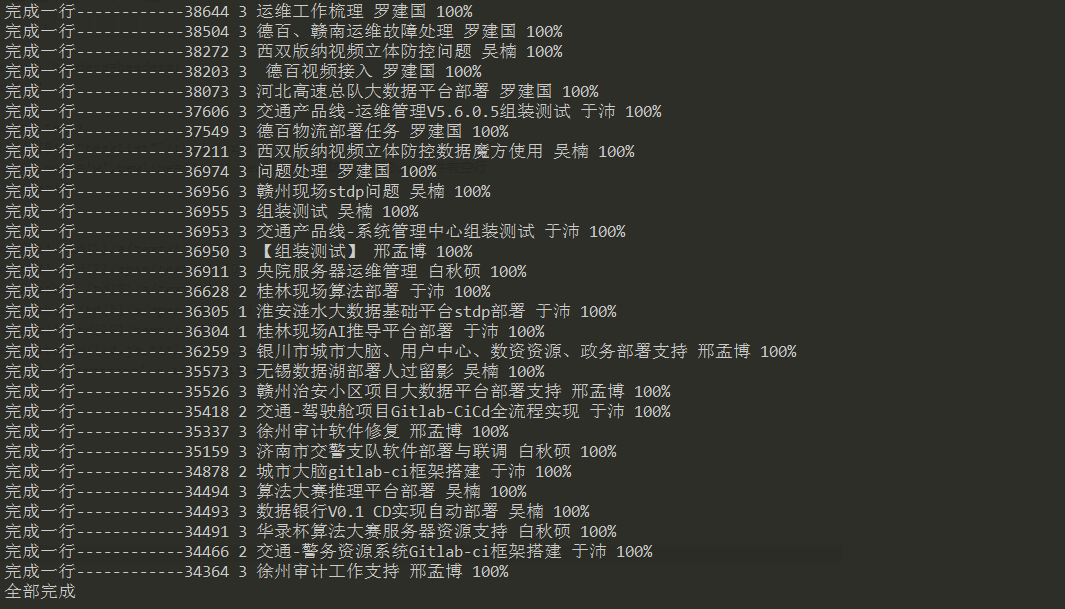
4、保存的结果