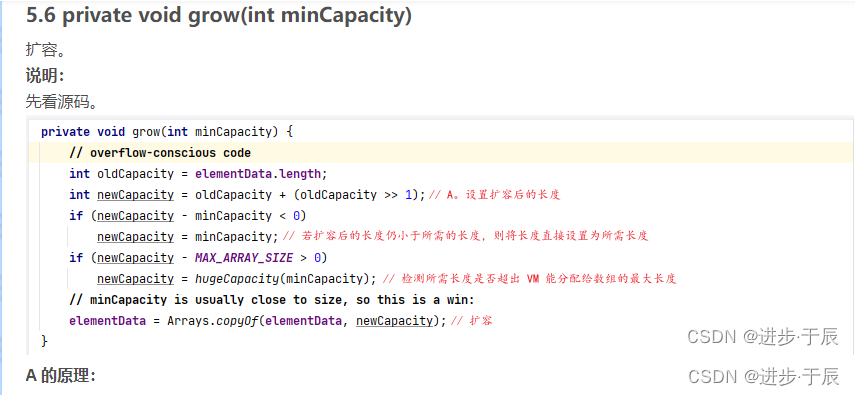
微信公众号版全文:https://mp.weixin.qq.com/s/prSr_zDLMGN7m3jhb6Bbkw
开源语言模型百宝袋 (Ver. 1.3)
Open-Source Language Model Pocket
Github: https://github.com/createmomo/Open-Source-Language-Model-Pocket
目录 (Table of Contents):
- 1 工具箱(Tools)
- Alpaca-LoRA (⭐3.1k)
- * Alpaca-CoT
- BELLE: Bloom-Enhanced Large Language model Engine (⭐1.1k)
- ColossalAI (⭐26.6k)
- * Cerebras
- ChatRWKV (⭐3.4k)
- ChatLLaMA (⭐7.2k)
- Dolly (⭐4.1k)
- FlexGen (⭐7.4k)
- FlagAI and FlagData
- Facebook LLaMA (⭐11.9k)
- * GPT4All
- * HuggingGPT
- llama.cpp (⭐8.6k)
- * Llama-X: Open Academic Research on Improving LLaMA to SOTA LLM
- * Lit-LLaMA ️
- OpenChatKit (⭐5.2k)
- Open-Assistant (⭐18.9k)
- PaLM + RLHF (Pytorch)(⭐5.7k)
- RL4LMs (⭐1.2k)
- Reinforcement Learning with Language Model
- Stanford Alpaca (⭐7.9k)
- Transformer Reinforcement Learning (⭐2.2k)
- Transformer Reinforcement Learning X (⭐2.5k)
- * Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality
- 2 中文开源模型(Chinese Open Source Language Models)
- 3 其他小伙伴的资料
- 总结开源可用的Instruct/Prompt Tuning数据
- 总结当下可用的大模型LLMs
- 针对聊天对话数据摘要生成任务微调 FLAN-T5
- 使用 DeepSpeed 和 Hugging Face ???? Transformer 微调 FLAN-T5 XL/XXL
- ChatGPT等大模型高效调参大法——PEFT库的算法简介
- Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU
- 可以微调类ChatGPT模型啦!开源Alpaca-LoRA+RTX 4090就能搞定
- 0门槛克隆ChatGPT!30分钟训完,60亿参数性能堪比GPT-3.5
- 训练个中文版ChatGPT没那么难:不用A100,开源Alpaca-LoRA+RTX 4090就能搞定
- * GPT fine-tune实战: 训练我自己的 ChatGPT
- * 笔记本就能运行的ChatGPT平替来了,附完整版技术报告
- * 【官方教程】ChatGLM-6B微调,最低只需7GB显存
- * 特制自己的ChatGPT:多接口统一的轻量级LLM-IFT平台
- * ChatDoctor:基于LLaMA在医学领域知识上微调的医学对话模型
- * 也谈ChatGPT的低成本“平替”当下实现路线:语言模型+指令微调数据+微调加速架构下的代表项目和开放数据
- * StackLLaMA: A hands-on guide to train LLaMA with RLHF
1 工具箱(Tools)
Alpaca-LoRA (⭐3.1k)
- https://github.com/tloen/alpaca-lora
Low-Rank LLaMA Instruct-Tuning
This repository contains code for reproducing the Stanford Alpaca results using low-rank adaptation (LoRA). We provide an Instruct model of similar quality to text-davinci-003 that can run on a Raspberry Pi (for research), and the code can be easily extended to the 13b, 30b, and 65b models.
In addition to the training code, which runs within five hours on a single RTX 4090, we publish a script for downloading and inference on the foundation model and LoRA, as well as the resulting LoRA weights themselves. To fine-tune cheaply and efficiently, we use Hugging Face's PEFT as well as Tim Dettmers' bitsandbytes.
Without hyperparameter tuning or validation-based checkpointing, the LoRA model produces outputs comparable to the Stanford Alpaca model. (Please see the outputs included below.) Further tuning might be able to achieve better performance; I invite interested users to give it a try and report their results.
* Alpaca-CoT
- https://github.com/PhoebusSi/Alpaca-CoT
- https://mp.weixin.qq.com/s/Q5Q3RpQ80XmpbfhSxq2R1Q
An Instruction Fine-Tuning Platform with Instruction Data Collection and Unified Large Language Models Interface
Alpaca-CoT项目旨在探究如何更好地通过instruction-tuning的方式来诱导LLM具备类似ChatGPT的交互和instruction-following能力。为此,我们广泛收集了不同类型的instruction(尤其是Chain-of-Thought数据集),并基于LLaMA给出了深入细致的实证研究,以供未来工作参考。据我们所知,我们是首个将CoT拓展进Alpaca的工作,因此简称为"Alpaca-CoT"。
BELLE: Bloom-Enhanced Large Language model Engine (⭐1.1k)
- https://github.com/LianjiaTech/BELLE
- https://zhuanlan.zhihu.com/p/616079388
本项目目标是促进中文对话大模型开源社区的发展,愿景做能帮到每一个人的LLM Engine。现阶段本项目基于一些开源预训练大语言模型(如BLOOM),针对中文做了优化,模型调优仅使用由ChatGPT生产的数据(不包含任何其他数据)。
ColossalAI (⭐26.6k)
- https://github.com/hpcaitech/ColossalAI
Colossal-AI: Making large AI models cheaper, faster and more accessible
Colossal-AI provides a collection of parallel components for you. We aim to support you to write your distributed deep learning models just like how you write your model on your laptop. We provide user-friendly tools to kickstart distributed training and inference in a few lines.
* Cerebras
- https://www.cerebras.net/blog/cerebras-gpt-a-family-of-open-compute-efficient-large-language-models/
- https://huggingface.co/cerebras
开源7个可商用GPT模型,含数据集和可直接下载的预训练模型权重: Cerebras 开源 7 个 GPT 模型,均可商用,参数量分别达到 1.11 亿、2.56 亿、5.9 亿、13 亿、27 亿、67 亿和 130 亿。其中最大的模型参数量达到 130 亿,与 Meta 最近开源的 LLaMA-13B 相当。该项目开源数据集和预训练模型权重,其中预训练模型权重文件大小近50G可直接下载,并且可用于商业和研究用途。与此前的 GPT-3 模型相比,Cerebras 开源的模型具有更高的可用性和透明度,研究人员和开发者可以使用少量数据对其进行微调,构建出高质量的自然语言处理应用。
ChatRWKV (⭐3.4k)
- https://github.com/BlinkDL/ChatRWKV
ChatRWKV is like ChatGPT but powered by my RWKV (100% RNN) language model, which is the only RNN (as of now) that can match transformers in quality and scaling, while being faster and saves VRAM. Training sponsored by Stability EleutherAI ![]()
ChatLLaMA (⭐7.2k)
- https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
ChatLLaMA ???? has been designed to help developers with various use cases, all related to RLHF training and optimized inference.
ChatLLaMA is a library that allows you to create hyper-personalized ChatGPT-like assistants using your own data and the least amount of compute possible. Instead of depending on one large assistant that “rules us all”, we envision a future where each of us can create our own personalized version of ChatGPT-like assistants. Imagine a future where many ChatLLaMAs at the "edge" will support a variety of human's needs. But creating a personalized assistant at the "edge" requires huge optimization efforts on many fronts: dataset creation, efficient training with RLHF, and inference optimization.
Dolly (⭐4.1k)
- https://github.com/databrickslabs/dolly
- https://www.databricks.com/blog/2023/03/24/hello-dolly-democratizing-magic-chatgpt-open-models.html
We show that anyone can take a dated off-the-shelf open source large language model (LLM) and give it magical ChatGPT-like instruction following ability by training it in 30 minutes on one machine, using high-quality training data. Surprisingly, instruction-following does not seem to require the latest or largest models: our model is only 6 billion parameters, compared to 175 billion for GPT-3. We open source the code for our model (Dolly) and show how it can be re-created on Databricks. We believe models like Dolly will help democratize LLMs, transforming them from something very few companies can afford into a commodity every company can own and customize to improve their products.
FlexGen (⭐7.4k)
- https://github.com/FMInference/FlexGen
FlexGen is a high-throughput generation engine for running large language models with limited GPU memory. FlexGen allows high-throughput generation by IO-efficient offloading, compression, and large effective batch sizes.
Limitation. As an offloading-based system running on weak GPUs, FlexGen also has its limitations. FlexGen can be significantly slower than the case when you have enough powerful GPUs to hold the whole model, especially for small-batch cases. FlexGen is mostly optimized for throughput-oriented batch processing settings (e.g., classifying or extracting information from many documents in batches), on single GPUs.
FlagAI and FlagData
- https://github.com/FlagAI-Open/FlagAI
FlagAI (Fast LArge-scale General AI models) is a fast, easy-to-use and extensible toolkit for large-scale model. Our goal is to support training, fine-tuning, and deployment of large-scale models on various downstream tasks with multi-modality.
- https://github.com/FlagOpen/FlagData
FlagData, a data processing toolkit that is easy to use and expand. FlagData integrates the tools and algorithms of multi-step data processing, including cleaning, condensation, annotation and analysis, providing powerful data processing support for model training and deployment in multiple fields, including natural language processing and computer vision.
Facebook LLaMA (⭐11.9k)
- https://github.com/facebookresearch/llama
LLaMA: Open and Efficient Foundation Language Models
We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. We release all our models to the research community.
* GPT4All
- https://github.com/nomic-ai/gpt4all
Demo, data and code to train an assistant-style large language model with ~800k GPT-3.5-Turbo Generations based on LLaMa
* HuggingGPT
- https://mp.weixin.qq.com/s/o51CmLt2JViJ4nsKfBJfwg
- https://arxiv.org/pdf/2303.17580.pdf
HuggingGPT利用ChatGPT作为控制器,连接HuggingFace社区中的各种AI模型,来完成多模态复杂任务。
这意味着,你将拥有一种超魔法,通过HuggingGPT,便可拥有多模态能力,文生图、文生视频、语音全能拿捏了。
llama.cpp (⭐8.6k)
- https://github.com/ggerganov/llama.cpp
Inference of LLaMA model in pure C/C++
The main goal is to run the model using 4-bit quantization on a MacBook
- Plain C/C++ implementation without dependencies
- Apple silicon first-class citizen - optimized via ARM NEON
- AVX2 support for x86 architectures
- Mixed F16 / F32 precision
- 4-bit quantization support
- Runs on the CPU
* Llama-X: Open Academic Research on Improving LLaMA to SOTA LLM
- https://github.com/AetherCortex/Llama-X
This is the repo for the Llama-X, which aims to:
- Progressively improve the performance of LLaMA to SOTA LLM with open-source community.
- Conduct Llama-X as an open academic research which is long-term, systematic and rigorous.
- Save the repetitive work of community and we work together to create more and faster increment.
* Lit-LLaMA ️
- https://github.com/Lightning-AI/lit-llama
Lit-LLaMA is:
- Simple: Single-file implementation without boilerplate.
- Correct: Numerically equivalent to the original model.
- Optimized: Runs on consumer hardware or at scale.
- Open-source: No strings attached.
OpenChatKit (⭐5.2k)
- https://www.together.xyz/blog/openchatkit
- https://huggingface.co/spaces/togethercomputer/OpenChatKit
- https://github.com/togethercomputer/OpenChatKit
OpenChatKit uses a 20 billion parameter chat model trained on 43 million instructions and supports reasoning, multi-turn conversation, knowledge and generative answers.
OpenChatKit provides a powerful, open-source base to create both specialized and general purpose chatbots for various applications. The kit includes an instruction-tuned 20 billion parameter language model, a 6 billion parameter moderation model, and an extensible retrieval system for including up-to-date responses from custom repositories. It was trained on the OIG-43M training dataset, which was a collaboration between Together, LAION, and Ontocord.ai. Much more than a model release, this is the beginning of an open source project. We are releasing a set of tools and processes for ongoing improvement with community contributions.
Open-Assistant (⭐18.9k)
- https://github.com/LAION-AI/Open-Assistant
- https://open-assistant.io/zh
Open Assistant is a project meant to give everyone access to a great chat based large language model.
We believe that by doing this we will create a revolution in innovation in language. In the same way that stable-diffusion helped the world make art and images in new ways we hope Open Assistant can help improve the world by improving language itself.
PaLM + RLHF (Pytorch)(⭐5.7k)
- https://github.com/lucidrains/PaLM-rlhf-pytorch
Implementation of RLHF (Reinforcement Learning with Human Feedback) on top of the PaLM architecture. Maybe I'll add retrieval functionality too, à la RETRO
RL4LMs (⭐1.2k)
- https://github.com/allenai/RL4LMs
- https://rl4lms.apps.allenai.org/
A modular RL library to fine-tune language models to human preferences
We provide easily customizable building blocks for training language models including implementations of on-policy algorithms, reward functions, metrics, datasets and LM based actor-critic policies
Reinforcement Learning with Language Model
- https://github.com/HarderThenHarder/transformers_tasks/tree/main/RLHF
在这个项目中,我们将通过开源项目 trl 搭建一个通过强化学习算法(PPO)来更新语言模型(GPT-2)的几个示例,包括:
- 基于中文情感识别模型的正向评论生成机器人(No Human Reward)
- 基于人工打分的正向评论生成机器人(With Human Reward)
- 基于排序序列(Rank List)训练一个奖励模型(Reward Model)
- 排序序列(Rank List)标注平台
Stanford Alpaca (⭐7.9k)
- https://crfm.stanford.edu/2023/03/13/alpaca.html
- https://alpaca-ai.ngrok.io/
- https://github.com/tatsu-lab/stanford_alpaca
Alpaca: A Strong, Replicable Instruction-Following ModelAl
We introduce Alpaca 7B, a model fine-tuned from the LLaMA 7B model on 52K instruction-following demonstrations. On our preliminary evaluation of single-turn instruction following, Alpaca behaves qualitatively similarly to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<600$).
Transformer Reinforcement Learning (⭐2.2k)
- https://github.com/lvwerra/trl
With trl you can train transformer language models with Proximal Policy Optimization (PPO). The library is built on top of the transformers library by ???? Hugging Face. Therefore, pre-trained language models can be directly loaded via transformers. At this point most of decoder architectures and encoder-decoder architectures are supported.
Transformer Reinforcement Learning X (⭐2.5k)
- https://github.com/CarperAI/trlx
trlX is a distributed training framework designed from the ground up to focus on fine-tuning large language models with reinforcement learning using either a provided reward function or a reward-labeled dataset.
Training support for ???? Hugging Face models is provided by Accelerate-backed trainers, allowing users to fine-tune causal and T5-based language models of up to 20B parameters, such as facebook/opt-6.7b, EleutherAI/gpt-neox-20b, and google/flan-t5-xxl. For models beyond 20B parameters, trlX provides NVIDIA NeMo-backed trainers that leverage efficient parallelism techniques to scale effectively.
* Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality
- https://chat.lmsys.org/
- https://vicuna.lmsys.org/
- https://github.com/lm-sys/FastChat
An open platform for training, serving, and evaluating large language model based chatbots.
2 中文开源模型(Chinese Open Source Language Models)
* 中文Alpaca模型Luotuo
- https://sota.jiqizhixin.com/project/luotuo
- https://github.com/LC1332/Luotuo-Chinese-LLM
Alpaca 是斯坦福团队基于 LLaMA 7B 在 52k 指令上微调得到的模型,能出色适应多种自然语言应用场景。近日来自商汤科技和华中科技大学开源中文语言模型 Luotuo,基于 ChatGPT API 翻译 Alpaca 微调指令数据,并使用 lora 进行微调得到。目前该项目已公开训练的语料和模型权重文件(两个型号),供开发者可使用自己各种大小的语料,训练自己的语言模型,并适用到对应的垂直领域。
* 中文LLaMA&Alpaca大模型
- https://github.com/ymcui/Chinese-LLaMA-Alpaca
以ChatGPT、GPT-4等为代表的大语言模型(Large Language Model, LLM)掀起了新一轮自然语言处理领域的研究浪潮,展现出了类通用人工智能(AGI)的能力,受到业界广泛关注。然而,由于大语言模型的训练和部署都极为昂贵,为构建透明且开放的学术研究造成了一定的阻碍。
为了促进大模型在中文NLP社区的开放研究,本项目开源了中文LLaMA模型和经过指令精调的Alpaca大模型。这些模型在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,在中文LLaMA的基础上,本项目使用了中文指令数据进行指令精调,显著提升了模型对指令的理解和执行能力。
BELLE: Bloom-Enhanced Large Language model Engine
- https://huggingface.co/BelleGroup
- https://github.com/LianjiaTech/BELLE
本项目基于 Stanford Alpaca ,Stanford Alpaca 的目标是构建和开源一个基于LLaMA的模型。 Stanford Alpaca 的种子任务都是英语,收集的数据也都是英文,因此训练出来的模型未对中文优化。
本项目目标是促进中文对话大模型开源社区的发展。本项目针对中文做了优化,模型调优仅使用由ChatGPT生产的数据(不包含任何其他数据)。
Bloom
- https://huggingface.co/blog/bloom
- https://huggingface.co/bigscience/bloom
BLOOM is an autoregressive Large Language Model (LLM), trained to continue text from a prompt on vast amounts of text data using industrial-scale computational resources. As such, it is able to output coherent text in 46 languages and 13 programming languages that is hardly distinguishable from text written by humans. BLOOM can also be instructed to perform text tasks it hasn't been explicitly trained for, by casting them as text generation tasks.
ChatYuan
- https://github.com/clue-ai/ChatYuan
- https://modelscope.cn/models/ClueAI/ChatYuan-large
元语功能型对话大模型, 这个模型可以用于问答、结合上下文做对话、做各种生成任务,包括创意性写作,也能回答一些像法律、新冠等领域问题。它基于PromptCLUE-large结合数亿条功能对话多轮对话数据进一步训练得到。
PromptCLUE-large在1000亿token中文语料上预训练,累计学习1.5万亿中文token,并且在数百种任务上进行Prompt任务式训练。针对理解类任务,如分类、情感分析、抽取等,可以自定义标签体系;针对多种生成任务,可以进行采样自由生成。
* ChatGLM-6B (⭐11.4k)
- https://github.com/THUDM/ChatGLM-6B
- https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。更多信息请参考我们的博客。
Chinese-Transformer-XL
- https://github.com/THUDM/Chinese-Transformer-XL
本项目提供了智源研究院"文汇" 预训练模型Chinese-Transformer-XL的预训练和文本生成代码。
EVA: 大规模中文开放域对话系统
- https://github.com/thu-coai/EVA
EVA 是目前最大的开源中文预训练对话模型,拥有28亿参数,主要擅长开放域闲聊,目前有 1.0 和 2.0 两个版本。其中,1.0版本在 WudaoCorpus-Dialog 上训练而成,2.0 版本在从 WudaoCorpus-Dialog 中清洗出的更高质量的对话数据上训练而成,模型性能也明显好于 EVA1.0。
GPT2 for Multiple Language (⭐1.6k)
-
https://github.com/imcaspar/gpt2-ml
-
简化整理 GPT2 训练代码(based on Grover, supporting TPUs)
-
移植 bert tokenizer,添加多语言支持
-
15亿参数 GPT2 中文预训练模型( 15G 语料,训练 10w 步 )
-
开箱即用的模型生成效果 demo #
-
15亿参数 GPT2 中文预训练模型( 30G 语料,训练 22w 步 )
PromptCLUE
- https://github.com/clue-ai/PromptCLUE
PromptCLUE:大规模多任务Prompt预训练中文开源模型。
中文上的三大统一:统一模型框架,统一任务形式,统一应用方式。
支持几十个不同类型的任务,具有较好的零样本学习能力和少样本学习能力。针对理解类任务,如分类、情感分析、抽取等,可以自定义标签体系;针对生成任务,可以进行采样自由生成。
千亿中文token上大规模预训练,累计学习1.5万亿中文token,亿级中文任务数据上完成训练,训练任务超过150+。比base版平均任务提升7个点+;具有更好的理解、生成和抽取能力,并且支持文本改写、纠错、知识图谱问答。
SkyText-Chinese-GPT3
- https://github.com/SkyWorkAIGC/SkyText-Chinese-GPT3
SkyText是由奇点智源发布的中文GPT3预训练大模型,可以进行聊天、问答、中英互译等不同的任务。 应用这个模型,除了可以实现基本的聊天、对话、你问我答外,还能支持中英文互译、内容续写、对对联、写古诗、生成菜谱、第三人称转述、创建采访问题等多种功能。
3 其他小伙伴的资料
总结开源可用的Instruct/Prompt Tuning数据
- https://zhuanlan.zhihu.com/p/615277009
总结当下可用的大模型LLMs
- https://zhuanlan.zhihu.com/p/611403556
针对聊天对话数据摘要生成任务微调 FLAN-T5
- https://www.philschmid.de/fine-tune-flan-t5
使用 DeepSpeed 和 Hugging Face ???? Transformer 微调 FLAN-T5 XL/XXL
- https://zhuanlan.zhihu.com/p/615528315
ChatGPT等大模型高效调参大法——PEFT库的算法简介
- https://zhuanlan.zhihu.com/p/613863520
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU
- https://huggingface.co/blog/trl-peft
可以微调类ChatGPT模型啦!开源Alpaca-LoRA+RTX 4090就能搞定
- https://mp.weixin.qq.com/s/vzIm-fOxxPEU69ArAowoIg
0门槛克隆ChatGPT!30分钟训完,60亿参数性能堪比GPT-3.5
- https://mp.weixin.qq.com/s/RMrXIHGOy3cPu8ybQNWonA
训练个中文版ChatGPT没那么难:不用A100,开源Alpaca-LoRA+RTX 4090就能搞定
- https://mp.weixin.qq.com/s/k7T-vfoH3xvxl6uqImP7DQ
* GPT fine-tune实战: 训练我自己的 ChatGPT
- https://zhuanlan.zhihu.com/p/616504594
* 笔记本就能运行的ChatGPT平替来了,附完整版技术报告
- https://mp.weixin.qq.com/s/crpG4dtfQFe3Q7hR3oeyxQ
* 【官方教程】ChatGLM-6B微调,最低只需7GB显存
- https://mp.weixin.qq.com/s/miML4PXioK5iM8UI0cTSCQ
* 特制自己的ChatGPT:多接口统一的轻量级LLM-IFT平台
- https://mp.weixin.qq.com/s/Q5Q3RpQ80XmpbfhSxq2R1Q
* ChatDoctor:基于LLaMA在医学领域知识上微调的医学对话模型
- https://mp.weixin.qq.com/s/-IqECOgCs4cS6Ya-EccXOA
- https://github.com/Kent0n-Li/ChatDoctor
* 也谈ChatGPT的低成本“平替”当下实现路线:语言模型+指令微调数据+微调加速架构下的代表项目和开放数据
- https://mp.weixin.qq.com/s/CJ4cCjti5jHOpDZqd42stw
* StackLLaMA: A hands-on guide to train LLaMA with RLHF
- https://huggingface.co/blog/stackllama
“
持续更新中 (Continuously Updated)...
”
开源语言模型百宝袋 (Ver. 1.3)
Open-Source Language Model Pocket
Github: https://github.com/createmomo/Open-Source-Language-Model-Pocket
目录 (Table of Contents):
- 1 工具箱(Tools)
- Alpaca-LoRA (⭐3.1k)
- * Alpaca-CoT
- BELLE: Bloom-Enhanced Large Language model Engine (⭐1.1k)
- ColossalAI (⭐26.6k)
- * Cerebras
- ChatRWKV (⭐3.4k)
- ChatLLaMA (⭐7.2k)
- Dolly (⭐4.1k)
- FlexGen (⭐7.4k)
- FlagAI and FlagData
- Facebook LLaMA (⭐11.9k)
- * GPT4All
- * HuggingGPT
- llama.cpp (⭐8.6k)
- * Llama-X: Open Academic Research on Improving LLaMA to SOTA LLM
- * Lit-LLaMA ️
- OpenChatKit (⭐5.2k)
- Open-Assistant (⭐18.9k)
- PaLM + RLHF (Pytorch)(⭐5.7k)
- RL4LMs (⭐1.2k)
- Reinforcement Learning with Language Model
- Stanford Alpaca (⭐7.9k)
- Transformer Reinforcement Learning (⭐2.2k)
- Transformer Reinforcement Learning X (⭐2.5k)
- * Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality
- 2 中文开源模型(Chinese Open Source Language Models)
- 3 其他小伙伴的资料
- 总结开源可用的Instruct/Prompt Tuning数据
- 总结当下可用的大模型LLMs
- 针对聊天对话数据摘要生成任务微调 FLAN-T5
- 使用 DeepSpeed 和 Hugging Face ???? Transformer 微调 FLAN-T5 XL/XXL
- ChatGPT等大模型高效调参大法——PEFT库的算法简介
- Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU
- 可以微调类ChatGPT模型啦!开源Alpaca-LoRA+RTX 4090就能搞定
- 0门槛克隆ChatGPT!30分钟训完,60亿参数性能堪比GPT-3.5
- 训练个中文版ChatGPT没那么难:不用A100,开源Alpaca-LoRA+RTX 4090就能搞定
- * GPT fine-tune实战: 训练我自己的 ChatGPT
- * 笔记本就能运行的ChatGPT平替来了,附完整版技术报告
- * 【官方教程】ChatGLM-6B微调,最低只需7GB显存
- * 特制自己的ChatGPT:多接口统一的轻量级LLM-IFT平台
- * ChatDoctor:基于LLaMA在医学领域知识上微调的医学对话模型
- * 也谈ChatGPT的低成本“平替”当下实现路线:语言模型+指令微调数据+微调加速架构下的代表项目和开放数据
- * StackLLaMA: A hands-on guide to train LLaMA with RLHF
1 工具箱(Tools)
Alpaca-LoRA (⭐3.1k)
- https://github.com/tloen/alpaca-lora
Low-Rank LLaMA Instruct-Tuning
This repository contains code for reproducing the Stanford Alpaca results using low-rank adaptation (LoRA). We provide an Instruct model of similar quality to text-davinci-003 that can run on a Raspberry Pi (for research), and the code can be easily extended to the 13b, 30b, and 65b models.
In addition to the training code, which runs within five hours on a single RTX 4090, we publish a script for downloading and inference on the foundation model and LoRA, as well as the resulting LoRA weights themselves. To fine-tune cheaply and efficiently, we use Hugging Face's PEFT as well as Tim Dettmers' bitsandbytes.
Without hyperparameter tuning or validation-based checkpointing, the LoRA model produces outputs comparable to the Stanford Alpaca model. (Please see the outputs included below.) Further tuning might be able to achieve better performance; I invite interested users to give it a try and report their results.
* Alpaca-CoT
- https://github.com/PhoebusSi/Alpaca-CoT
- https://mp.weixin.qq.com/s/Q5Q3RpQ80XmpbfhSxq2R1Q
An Instruction Fine-Tuning Platform with Instruction Data Collection and Unified Large Language Models Interface
Alpaca-CoT项目旨在探究如何更好地通过instruction-tuning的方式来诱导LLM具备类似ChatGPT的交互和instruction-following能力。为此,我们广泛收集了不同类型的instruction(尤其是Chain-of-Thought数据集),并基于LLaMA给出了深入细致的实证研究,以供未来工作参考。据我们所知,我们是首个将CoT拓展进Alpaca的工作,因此简称为"Alpaca-CoT"。
BELLE: Bloom-Enhanced Large Language model Engine (⭐1.1k)
- https://github.com/LianjiaTech/BELLE
- https://zhuanlan.zhihu.com/p/616079388
本项目目标是促进中文对话大模型开源社区的发展,愿景做能帮到每一个人的LLM Engine。现阶段本项目基于一些开源预训练大语言模型(如BLOOM),针对中文做了优化,模型调优仅使用由ChatGPT生产的数据(不包含任何其他数据)。
ColossalAI (⭐26.6k)
- https://github.com/hpcaitech/ColossalAI
Colossal-AI: Making large AI models cheaper, faster and more accessible
Colossal-AI provides a collection of parallel components for you. We aim to support you to write your distributed deep learning models just like how you write your model on your laptop. We provide user-friendly tools to kickstart distributed training and inference in a few lines.
* Cerebras
- https://www.cerebras.net/blog/cerebras-gpt-a-family-of-open-compute-efficient-large-language-models/
- https://huggingface.co/cerebras
开源7个可商用GPT模型,含数据集和可直接下载的预训练模型权重: Cerebras 开源 7 个 GPT 模型,均可商用,参数量分别达到 1.11 亿、2.56 亿、5.9 亿、13 亿、27 亿、67 亿和 130 亿。其中最大的模型参数量达到 130 亿,与 Meta 最近开源的 LLaMA-13B 相当。该项目开源数据集和预训练模型权重,其中预训练模型权重文件大小近50G可直接下载,并且可用于商业和研究用途。与此前的 GPT-3 模型相比,Cerebras 开源的模型具有更高的可用性和透明度,研究人员和开发者可以使用少量数据对其进行微调,构建出高质量的自然语言处理应用。
ChatRWKV (⭐3.4k)
- https://github.com/BlinkDL/ChatRWKV
ChatRWKV is like ChatGPT but powered by my RWKV (100% RNN) language model, which is the only RNN (as of now) that can match transformers in quality and scaling, while being faster and saves VRAM. Training sponsored by Stability EleutherAI ![]()
ChatLLaMA (⭐7.2k)
- https://github.com/nebuly-ai/nebullvm/tree/main/apps/accelerate/chatllama
ChatLLaMA ???? has been designed to help developers with various use cases, all related to RLHF training and optimized inference.
ChatLLaMA is a library that allows you to create hyper-personalized ChatGPT-like assistants using your own data and the least amount of compute possible. Instead of depending on one large assistant that “rules us all”, we envision a future where each of us can create our own personalized version of ChatGPT-like assistants. Imagine a future where many ChatLLaMAs at the "edge" will support a variety of human's needs. But creating a personalized assistant at the "edge" requires huge optimization efforts on many fronts: dataset creation, efficient training with RLHF, and inference optimization.
Dolly (⭐4.1k)
- https://github.com/databrickslabs/dolly
- https://www.databricks.com/blog/2023/03/24/hello-dolly-democratizing-magic-chatgpt-open-models.html
We show that anyone can take a dated off-the-shelf open source large language model (LLM) and give it magical ChatGPT-like instruction following ability by training it in 30 minutes on one machine, using high-quality training data. Surprisingly, instruction-following does not seem to require the latest or largest models: our model is only 6 billion parameters, compared to 175 billion for GPT-3. We open source the code for our model (Dolly) and show how it can be re-created on Databricks. We believe models like Dolly will help democratize LLMs, transforming them from something very few companies can afford into a commodity every company can own and customize to improve their products.
FlexGen (⭐7.4k)
- https://github.com/FMInference/FlexGen
FlexGen is a high-throughput generation engine for running large language models with limited GPU memory. FlexGen allows high-throughput generation by IO-efficient offloading, compression, and large effective batch sizes.
Limitation. As an offloading-based system running on weak GPUs, FlexGen also has its limitations. FlexGen can be significantly slower than the case when you have enough powerful GPUs to hold the whole model, especially for small-batch cases. FlexGen is mostly optimized for throughput-oriented batch processing settings (e.g., classifying or extracting information from many documents in batches), on single GPUs.
FlagAI and FlagData
- https://github.com/FlagAI-Open/FlagAI
FlagAI (Fast LArge-scale General AI models) is a fast, easy-to-use and extensible toolkit for large-scale model. Our goal is to support training, fine-tuning, and deployment of large-scale models on various downstream tasks with multi-modality.
- https://github.com/FlagOpen/FlagData
FlagData, a data processing toolkit that is easy to use and expand. FlagData integrates the tools and algorithms of multi-step data processing, including cleaning, condensation, annotation and analysis, providing powerful data processing support for model training and deployment in multiple fields, including natural language processing and computer vision.
Facebook LLaMA (⭐11.9k)
- https://github.com/facebookresearch/llama
LLaMA: Open and Efficient Foundation Language Models
We introduce LLaMA, a collection of foundation language models ranging from 7B to 65B parameters. We train our models on trillions of tokens, and show that it is possible to train state-of-the-art models using publicly available datasets exclusively, without resorting to proprietary and inaccessible datasets. In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B. We release all our models to the research community.
* GPT4All
- https://github.com/nomic-ai/gpt4all
Demo, data and code to train an assistant-style large language model with ~800k GPT-3.5-Turbo Generations based on LLaMa
* HuggingGPT
- https://mp.weixin.qq.com/s/o51CmLt2JViJ4nsKfBJfwg
- https://arxiv.org/pdf/2303.17580.pdf
HuggingGPT利用ChatGPT作为控制器,连接HuggingFace社区中的各种AI模型,来完成多模态复杂任务。
这意味着,你将拥有一种超魔法,通过HuggingGPT,便可拥有多模态能力,文生图、文生视频、语音全能拿捏了。
llama.cpp (⭐8.6k)
- https://github.com/ggerganov/llama.cpp
Inference of LLaMA model in pure C/C++
The main goal is to run the model using 4-bit quantization on a MacBook
- Plain C/C++ implementation without dependencies
- Apple silicon first-class citizen - optimized via ARM NEON
- AVX2 support for x86 architectures
- Mixed F16 / F32 precision
- 4-bit quantization support
- Runs on the CPU
* Llama-X: Open Academic Research on Improving LLaMA to SOTA LLM
- https://github.com/AetherCortex/Llama-X
This is the repo for the Llama-X, which aims to:
- Progressively improve the performance of LLaMA to SOTA LLM with open-source community.
- Conduct Llama-X as an open academic research which is long-term, systematic and rigorous.
- Save the repetitive work of community and we work together to create more and faster increment.
* Lit-LLaMA ️
- https://github.com/Lightning-AI/lit-llama
Lit-LLaMA is:
- Simple: Single-file implementation without boilerplate.
- Correct: Numerically equivalent to the original model.
- Optimized: Runs on consumer hardware or at scale.
- Open-source: No strings attached.
OpenChatKit (⭐5.2k)
- https://www.together.xyz/blog/openchatkit
- https://huggingface.co/spaces/togethercomputer/OpenChatKit
- https://github.com/togethercomputer/OpenChatKit
OpenChatKit uses a 20 billion parameter chat model trained on 43 million instructions and supports reasoning, multi-turn conversation, knowledge and generative answers.
OpenChatKit provides a powerful, open-source base to create both specialized and general purpose chatbots for various applications. The kit includes an instruction-tuned 20 billion parameter language model, a 6 billion parameter moderation model, and an extensible retrieval system for including up-to-date responses from custom repositories. It was trained on the OIG-43M training dataset, which was a collaboration between Together, LAION, and Ontocord.ai. Much more than a model release, this is the beginning of an open source project. We are releasing a set of tools and processes for ongoing improvement with community contributions.
Open-Assistant (⭐18.9k)
- https://github.com/LAION-AI/Open-Assistant
- https://open-assistant.io/zh
Open Assistant is a project meant to give everyone access to a great chat based large language model.
We believe that by doing this we will create a revolution in innovation in language. In the same way that stable-diffusion helped the world make art and images in new ways we hope Open Assistant can help improve the world by improving language itself.
PaLM + RLHF (Pytorch)(⭐5.7k)
- https://github.com/lucidrains/PaLM-rlhf-pytorch
Implementation of RLHF (Reinforcement Learning with Human Feedback) on top of the PaLM architecture. Maybe I'll add retrieval functionality too, à la RETRO
RL4LMs (⭐1.2k)
- https://github.com/allenai/RL4LMs
- https://rl4lms.apps.allenai.org/
A modular RL library to fine-tune language models to human preferences
We provide easily customizable building blocks for training language models including implementations of on-policy algorithms, reward functions, metrics, datasets and LM based actor-critic policies
Reinforcement Learning with Language Model
- https://github.com/HarderThenHarder/transformers_tasks/tree/main/RLHF
在这个项目中,我们将通过开源项目 trl 搭建一个通过强化学习算法(PPO)来更新语言模型(GPT-2)的几个示例,包括:
- 基于中文情感识别模型的正向评论生成机器人(No Human Reward)
- 基于人工打分的正向评论生成机器人(With Human Reward)
- 基于排序序列(Rank List)训练一个奖励模型(Reward Model)
- 排序序列(Rank List)标注平台
Stanford Alpaca (⭐7.9k)
- https://crfm.stanford.edu/2023/03/13/alpaca.html
- https://alpaca-ai.ngrok.io/
- https://github.com/tatsu-lab/stanford_alpaca
Alpaca: A Strong, Replicable Instruction-Following ModelAl
We introduce Alpaca 7B, a model fine-tuned from the LLaMA 7B model on 52K instruction-following demonstrations. On our preliminary evaluation of single-turn instruction following, Alpaca behaves qualitatively similarly to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<600$).
Transformer Reinforcement Learning (⭐2.2k)
- https://github.com/lvwerra/trl
With trl you can train transformer language models with Proximal Policy Optimization (PPO). The library is built on top of the transformers library by ???? Hugging Face. Therefore, pre-trained language models can be directly loaded via transformers. At this point most of decoder architectures and encoder-decoder architectures are supported.
Transformer Reinforcement Learning X (⭐2.5k)
- https://github.com/CarperAI/trlx
trlX is a distributed training framework designed from the ground up to focus on fine-tuning large language models with reinforcement learning using either a provided reward function or a reward-labeled dataset.
Training support for ???? Hugging Face models is provided by Accelerate-backed trainers, allowing users to fine-tune causal and T5-based language models of up to 20B parameters, such as facebook/opt-6.7b, EleutherAI/gpt-neox-20b, and google/flan-t5-xxl. For models beyond 20B parameters, trlX provides NVIDIA NeMo-backed trainers that leverage efficient parallelism techniques to scale effectively.
* Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality
- https://chat.lmsys.org/
- https://vicuna.lmsys.org/
- https://github.com/lm-sys/FastChat
An open platform for training, serving, and evaluating large language model based chatbots.
2 中文开源模型(Chinese Open Source Language Models)
* 中文Alpaca模型Luotuo
- https://sota.jiqizhixin.com/project/luotuo
- https://github.com/LC1332/Luotuo-Chinese-LLM
Alpaca 是斯坦福团队基于 LLaMA 7B 在 52k 指令上微调得到的模型,能出色适应多种自然语言应用场景。近日来自商汤科技和华中科技大学开源中文语言模型 Luotuo,基于 ChatGPT API 翻译 Alpaca 微调指令数据,并使用 lora 进行微调得到。目前该项目已公开训练的语料和模型权重文件(两个型号),供开发者可使用自己各种大小的语料,训练自己的语言模型,并适用到对应的垂直领域。
* 中文LLaMA&Alpaca大模型
- https://github.com/ymcui/Chinese-LLaMA-Alpaca
以ChatGPT、GPT-4等为代表的大语言模型(Large Language Model, LLM)掀起了新一轮自然语言处理领域的研究浪潮,展现出了类通用人工智能(AGI)的能力,受到业界广泛关注。然而,由于大语言模型的训练和部署都极为昂贵,为构建透明且开放的学术研究造成了一定的阻碍。
为了促进大模型在中文NLP社区的开放研究,本项目开源了中文LLaMA模型和经过指令精调的Alpaca大模型。这些模型在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,在中文LLaMA的基础上,本项目使用了中文指令数据进行指令精调,显著提升了模型对指令的理解和执行能力。
BELLE: Bloom-Enhanced Large Language model Engine
- https://huggingface.co/BelleGroup
- https://github.com/LianjiaTech/BELLE
本项目基于 Stanford Alpaca ,Stanford Alpaca 的目标是构建和开源一个基于LLaMA的模型。 Stanford Alpaca 的种子任务都是英语,收集的数据也都是英文,因此训练出来的模型未对中文优化。
本项目目标是促进中文对话大模型开源社区的发展。本项目针对中文做了优化,模型调优仅使用由ChatGPT生产的数据(不包含任何其他数据)。
Bloom
- https://huggingface.co/blog/bloom
- https://huggingface.co/bigscience/bloom
BLOOM is an autoregressive Large Language Model (LLM), trained to continue text from a prompt on vast amounts of text data using industrial-scale computational resources. As such, it is able to output coherent text in 46 languages and 13 programming languages that is hardly distinguishable from text written by humans. BLOOM can also be instructed to perform text tasks it hasn't been explicitly trained for, by casting them as text generation tasks.
ChatYuan
- https://github.com/clue-ai/ChatYuan
- https://modelscope.cn/models/ClueAI/ChatYuan-large
元语功能型对话大模型, 这个模型可以用于问答、结合上下文做对话、做各种生成任务,包括创意性写作,也能回答一些像法律、新冠等领域问题。它基于PromptCLUE-large结合数亿条功能对话多轮对话数据进一步训练得到。
PromptCLUE-large在1000亿token中文语料上预训练,累计学习1.5万亿中文token,并且在数百种任务上进行Prompt任务式训练。针对理解类任务,如分类、情感分析、抽取等,可以自定义标签体系;针对多种生成任务,可以进行采样自由生成。
* ChatGLM-6B (⭐11.4k)
- https://github.com/THUDM/ChatGLM-6B
- https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。更多信息请参考我们的博客。
Chinese-Transformer-XL
- https://github.com/THUDM/Chinese-Transformer-XL
本项目提供了智源研究院"文汇" 预训练模型Chinese-Transformer-XL的预训练和文本生成代码。
EVA: 大规模中文开放域对话系统
- https://github.com/thu-coai/EVA
EVA 是目前最大的开源中文预训练对话模型,拥有28亿参数,主要擅长开放域闲聊,目前有 1.0 和 2.0 两个版本。其中,1.0版本在 WudaoCorpus-Dialog 上训练而成,2.0 版本在从 WudaoCorpus-Dialog 中清洗出的更高质量的对话数据上训练而成,模型性能也明显好于 EVA1.0。
GPT2 for Multiple Language (⭐1.6k)
-
https://github.com/imcaspar/gpt2-ml
-
简化整理 GPT2 训练代码(based on Grover, supporting TPUs)
-
移植 bert tokenizer,添加多语言支持
-
15亿参数 GPT2 中文预训练模型( 15G 语料,训练 10w 步 )
-
开箱即用的模型生成效果 demo #
-
15亿参数 GPT2 中文预训练模型( 30G 语料,训练 22w 步 )
PromptCLUE
- https://github.com/clue-ai/PromptCLUE
PromptCLUE:大规模多任务Prompt预训练中文开源模型。
中文上的三大统一:统一模型框架,统一任务形式,统一应用方式。
支持几十个不同类型的任务,具有较好的零样本学习能力和少样本学习能力。针对理解类任务,如分类、情感分析、抽取等,可以自定义标签体系;针对生成任务,可以进行采样自由生成。
千亿中文token上大规模预训练,累计学习1.5万亿中文token,亿级中文任务数据上完成训练,训练任务超过150+。比base版平均任务提升7个点+;具有更好的理解、生成和抽取能力,并且支持文本改写、纠错、知识图谱问答。
SkyText-Chinese-GPT3
- https://github.com/SkyWorkAIGC/SkyText-Chinese-GPT3
SkyText是由奇点智源发布的中文GPT3预训练大模型,可以进行聊天、问答、中英互译等不同的任务。 应用这个模型,除了可以实现基本的聊天、对话、你问我答外,还能支持中英文互译、内容续写、对对联、写古诗、生成菜谱、第三人称转述、创建采访问题等多种功能。
3 其他小伙伴的资料
总结开源可用的Instruct/Prompt Tuning数据
- https://zhuanlan.zhihu.com/p/615277009
总结当下可用的大模型LLMs
- https://zhuanlan.zhihu.com/p/611403556
针对聊天对话数据摘要生成任务微调 FLAN-T5
- https://www.philschmid.de/fine-tune-flan-t5
使用 DeepSpeed 和 Hugging Face ???? Transformer 微调 FLAN-T5 XL/XXL
- https://zhuanlan.zhihu.com/p/615528315
ChatGPT等大模型高效调参大法——PEFT库的算法简介
- https://zhuanlan.zhihu.com/p/613863520
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU
- https://huggingface.co/blog/trl-peft
可以微调类ChatGPT模型啦!开源Alpaca-LoRA+RTX 4090就能搞定
- https://mp.weixin.qq.com/s/vzIm-fOxxPEU69ArAowoIg
0门槛克隆ChatGPT!30分钟训完,60亿参数性能堪比GPT-3.5
- https://mp.weixin.qq.com/s/RMrXIHGOy3cPu8ybQNWonA
训练个中文版ChatGPT没那么难:不用A100,开源Alpaca-LoRA+RTX 4090就能搞定
- https://mp.weixin.qq.com/s/k7T-vfoH3xvxl6uqImP7DQ
* GPT fine-tune实战: 训练我自己的 ChatGPT
- https://zhuanlan.zhihu.com/p/616504594
* 笔记本就能运行的ChatGPT平替来了,附完整版技术报告
- https://mp.weixin.qq.com/s/crpG4dtfQFe3Q7hR3oeyxQ
* 【官方教程】ChatGLM-6B微调,最低只需7GB显存
- https://mp.weixin.qq.com/s/miML4PXioK5iM8UI0cTSCQ
* 特制自己的ChatGPT:多接口统一的轻量级LLM-IFT平台
- https://mp.weixin.qq.com/s/Q5Q3RpQ80XmpbfhSxq2R1Q
* ChatDoctor:基于LLaMA在医学领域知识上微调的医学对话模型
- https://mp.weixin.qq.com/s/-IqECOgCs4cS6Ya-EccXOA
- https://github.com/Kent0n-Li/ChatDoctor
* 也谈ChatGPT的低成本“平替”当下实现路线:语言模型+指令微调数据+微调加速架构下的代表项目和开放数据
- https://mp.weixin.qq.com/s/CJ4cCjti5jHOpDZqd42stw
* StackLLaMA: A hands-on guide to train LLaMA with RLHF
- https://huggingface.co/blog/stackllama
“
持续更新中 (Continuously Updated)...
”