论文翻译:2020_GCRN_Learning Complex Spectral Mapping With Gated Convolutional Recurrent Networks for Monaural Speech Enhancement
论文地址:使用门控卷积循环网络学习复数谱映射以增强单耳语音
代码地址:https://github.com/JupiterEthan/GCRN-complex
作者主页:https://jupiterethan.github.io/
引用格式:Tan K, Wang D L. Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 28: 380-390.
摘要
相位对于语音的感知质量很重要。 但是由于其中缺乏频谱时间结构,通过监督学习直接估计相位谱似乎很难。复数谱映射的目的在于从噪声语音中提取出纯净语音的实谱图和虚谱图,同时增强语音的幅度响应和相位响应。在多任务学习的启发下,我们提出了一种用于复数谱映射的门控卷积循环网络(GCRN),它可作为单耳语音增强的因果系统。我们的实验结果表明,提出的GCRN大大优于现有的卷积神经网络(CNN)在复数谱映射方面的客观语音可理解性和质量。此外,与幅度谱映射和复数比率掩码相比,该方法产生了显著更高的STOI和PESQ。我们还发现,复数谱映射与提出的GCRN提供了一个有效的相位估计。
关键词:复数谱映射、门控卷积递归网络、相位估计、单声道语音增强。
1 引言
在日常聆听环境中,语音信号会被背景噪音干扰。这种失真严重地降低了 语音的可懂度和质量,并使许多与语音有关的任务,如自动语音识别,变得更加复杂。许多与语音有关的任务,如自动语音识别 和说话人的识别更加困难。语音增强 的目的是去除或减弱语音信号中的背景噪音 信号。如果语音信号是由低信噪比的单个麦克风采集的,那么它从根本上来说是具有挑战性的。如果语音信号是由单一的麦克风在低信噪比的情况下捕获的 (SNRs)。本研究的重点是单声道(单通道)语音增强。
在过去的几十年里,语音处理界对单声道语音增强进行了广泛的研究。受计算听觉场景分析(CASA)中时频(T-F)mask概念的启发,近年来,语音增强被表述为有监督的学习[36]。对于 监督下的语音增强,适当选择训练目标是很重要的[38]。对于有监督的语音增强,正确选择训练目标是非常重要的。一方面,明确的训练目标可以显著提高语音清晰度和语音质量。另一方面,培训目标应服从监督学习。在T-F领域已经发展了许多训练目标,它们主要分为两类。一组是基于掩码的目标,如理想比例掩码(IRM)[38],它定义干净语音和噪声语音之间的时频关系。另一种是基于映射的目标,如对数功率谱(LPS)[44]和目标幅度谱(TMS)[20],[12],它们代表干净语音的频谱特征。
这些训练目标大多是针对噪声语音的幅度谱进行操作的,它是由短时傅里叶变换(STFT)计算出来的。因此,典型的语音增强系统只增强幅度谱,并简单地使用噪声相位谱来重新合成增强的时域波形。不增强相位谱的原因有两个方面。首先,人们发现在相位谱中不存在明确的结构,这使得直接估计纯净语音的相位谱变得难以实现[43]。 其次,人们认为相位增强对语音增强并不重要[37]。然而,Paliwal等人[23]最近的一项研究表明,准确的相位估计可以大大改善客观和主观的语音质量,特别是当相位谱计算的分析窗口被仔细选择时。随后,各种相位增强算法也被开发出来用于语音分离。Mowlaee等人[21]通过最小化平均平方误差(MSE)来估计混合物中两个来源的相位谱。Krawczyk和Gerkmann[17]对有声音的语音帧进行相位增强,而对无声音的帧不作改动。Kulmer等人[18]通过对瞬时噪声相位谱进行相位分解,然后进行时间平滑来估计纯净语音相位。 通过这些相位增强方法,可以实现客观的语音质量改善。另外,相位信息也可以被纳入T-F掩码中。Wang和Wang[39]训练了一个深度神经网络(DNN),通过反傅里叶变换层,利用噪声相位直接重建时域增强信号。结果表明,语音合成和掩码估计的联合训练提高了感知质量,同时保持了客观的可懂度。 另一种方法是相位敏感掩码(PSM)[5],它结合了纯净语音和噪声语音之间的相位差。实验结果表明,PSM估计比只增强幅度谱产生更高的信噪比(SDR)。
Williamson等人[43]观察到,虽然相位频谱缺乏谱时结构,但纯净语音频谱的实部和虚部都表现出清晰的结构,因此适合于监督学习。因此,他们设计了复杂理想比值掩码(cIRM),它可以从噪声语音中重建纯净语音。在他们的实验中,采用了一个DNN来联合估计实谱和虚谱。与[21]、[17]和[18]中的算法不同,cIRM估计可以增强噪声语音的幅值和相位谱。结果表明,复杂比率掩码(cRM)比IRM估计产生更好的感知质量,同时在客观可懂度上取得轻微或没有改善。随后,Fu等人[6]采用卷积神经网络(CNN)从噪声频谱中估计出纯净实谱和虚谱。然后,估计的实谱和虚谱被用来重建时域的波形。他们的实验结果表明,与DNN相比,CNN使短时客观可懂度(STOI)提高了3.1%[29],使语音质量的感性评价(PESQ)[28]提高了0.12。此外,他们还训练了一个DNN,以从噪声的LPS特征映射到纯净特征。他们的实验结果表明,使用DNN的复数谱映射比使用相同DNN的LPS频谱映射产生了2.4%的STOI改善和0.21的PESQ改善。
在过去的十年中,监督下的语音增强已经从CNN和循环神经网络(RNN)的使用中获益匪浅。在[42]、[41]、[40]和[5]中,具有长短期记忆(LSTM)的RNN被用来进行语音增强。最近,Chen等人[1]提出了一个具有四个隐藏LSTM层的RNN,以解决不依赖噪声的模型的说话人泛化问题。他们发现,RNN对未经训练的说话人有很好的泛化作用,并且在STOI方面明显优于前馈DNN。此外,CNN也被用于掩码估计和频谱映射[7],[25],[11],[31]。在[25]中,Park等人利用卷积编码器-解码器网络(CED)来进行谱映射。CED实现了与DNN和RNN相当的去噪性能,而其可训练的参数却少得多。Grais等人[11]提出了一个类似的编码器-解码器架构。最近,我们提出了一个基于扩张卷积的门控残差网络,它有大的感受野,因此可以利用长期背景[31]。卷积递归网络(CRNs)得益于CNNs的特征提取能力和RNNs的时空建模能力。 Naithani等人[22]通过连续堆叠卷积层、递归层和全连接层设计了一个CRN。 在[46]中开发了一个类似的CRN架构。最近,我们将CED和LSTMs集成到CRN中,这相当于一个因果系统[32]。此外,Takahashi等人[30]开发了一个CRN,在多个低尺度上结合了卷积层和递归层。
在一项初步研究中,我们最近提出了一种新型的CRN,用于执行单声道语音增强的复数谱映射[33]。这个CRN是基于[32]中的架构。 与[6]中的CNN相比,CRN产生了更高的STOI和PESQ,而且计算效率更高。在这项研究中,我们进一步发展了CRN架构,并研究了用于单声道语音增强的复数谱映射。我们对[33]的扩展包括以下内容。首先,每个卷积层或解卷积层被相应的门控线性单元(GLU)块所取代[4]。第二,我们在最后一个去卷积层的基础上增加了一个线性层来预测实谱和虚谱。
本文的其余部分组织如下。在第二节中,我们介绍了STFT域中的单声道语音增强。在第三节中,我们详细描述了我们提出的方法。在第五节中,我们介绍并讨论了实验结果。第六部分是本文的结论。
2 STFT域单耳语音增强
给定一个单麦克风混合物$y$,单声道语音增强的目的是将目标语音$s$从背景噪声$n$中分离出来。 噪声混合物可以被建模为:
$$公式1:y[k]=s[k]+n[k]$$
其中$k$是时间样本指数。对两边进行STFT,我们得到:
$$公式2:Y_{m,f}=S_{m,f}+N_{m,f}$$
其中$Y$、$S$和$N$分别代表$y$、$s$和$n$的STFT,$m$和$f$分别表示时间段和频bin。在极坐标中,公式(2)变成
$$公式3:\left|Y_{m, f}\right| e^{i \theta_{Y_{m, f}}}=\left|S_{m, f}\right| e^{i \theta_{S_{m, f}}}+\left|N_{m, f}\right| e^{i \theta_{N_{m, f}}}$$
其中$|·|$表示幅值,$\theta $表示相位。虚数单位用$’i’$表示。在典型的基于频谱映射的方法中,纯净语音的目标幅度谱(TMS)(即$|S_{m,f}|$是一个常用的训练目标[20], [12]。在这些方法中,从噪声特征(如噪声幅度$Y_{m,f}$)到目标幅度的映射被学习。然后将估计的幅度$|\hat{S}_{m,f}|$与噪声相位$\theta_{Y_{m,f}}$相结合,重新合成波形。图1(a)描述了一个语音信号的相位谱,其中相位值被包裹在$(-\pi , \pi )$范围内。经过包装后,相位谱看起来相当随机。在图1(b)中,相位谱的解包版本导致了更平滑的相位图,当连续的T-F单元之间的绝对相位跳动大于或等于$\pi $时,相位值通过添加$\pm 2\pi$的倍数进行校正。 因此,通过监督学习直接估计相位谱是难以做到的。
从另一个角度来看,语音信号的STFT可以用直角坐标表示。因此,公式。(2)可以改写为
$$公式4:Y_{m, f}^{(r)}+i Y_{m, f}^{(i)}=\left(S_{m, f}^{(r)}+N_{m, f}^{(r)}\right)+i\left(S_{m, f}^{(i)}+N_{m, f}^{(i)}\right)$$
其中上标$(r)$和$(i)$分别表示实部和虚部。在[43]中,cIRM被定义为
$$公式5:M=\frac{Y^{(r)} S^{(r)}+Y^{(i)} S^{(i)}}{\left(Y^{(r)}\right)^{2}+\left(Y^{(i)}\right)^{2}}+i \frac{Y^{(r)} S^{(i)}-Y^{(i)} S^{(r)}}{\left(Y^{(r)}\right)^{2}+\left(Y^{(i)}\right)^{2}}$$
其中,为简单起见,省略了指数$m$和$f$。增强的频谱可以通过对噪声频谱应用cIRM $\hat{M}$的估计而得到。
$$公式6:S=\hat{M}*Y$$
其中上面的乘法’×’是一个复数算子
此外,我们还扩展了信号近似法(SA)[15]。SA通过最小化纯净语音的频谱幅度和估计语音的频谱幅度之间的差异来进行掩码。 基于cRM的信号逼近(cRM-SA)的损失定义为:
$$公式7:S A=|c R M \times Y-S|^{2}$$
其中$|·|$代表复数模子,即复数的绝对值。
如图1(d)和1(e)所示,实谱和虚谱都表现出清晰的谱时结构,类似于图1(c)的幅度谱,因此适合于监督学习。因此,我们建议像[6]那样,直接从噪声语音的实谱和虚谱(即$Y^{(r)}$和$Y^{(i)}$)到纯净语音的实谱和虚谱(即$S^{(r)}$和$S^{(i)}$)学习谱映射。随后,估计的实谱和虚谱被合并以恢复时域信号。
需要注意的是,Williamson等人[43]声称,通过DNN直接预测STFT的实部和虚部是无效的。然而,我们发现,在STOI和PESQ指标中,复数谱映射始终优于幅度谱映射、复数比率掩码和基于复数比率掩码的信号逼近,只要有一个精心设计的神经网络结构。为方便起见,我们将复数频谱映射中使用的训练目标,即$S^{(r)}$和$S^{(i)}$,称为目标复数频谱(TCS)。
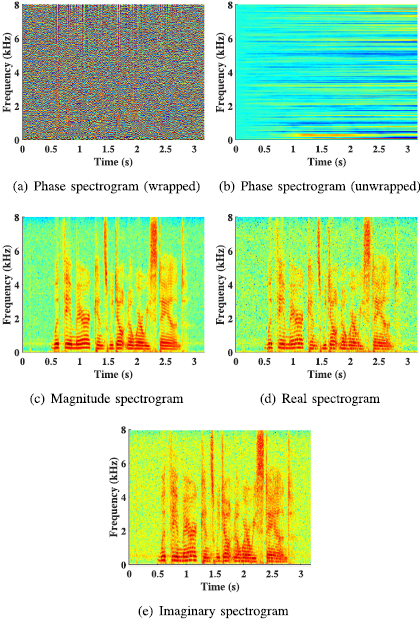
图1:语音信号的相位、幅度、实部和虚部频谱的图示。
幅度以及实部和虚部频谱的绝对值绘制在对数刻度上
3 系统描述
A 卷积循环网络(CRN)
在[32]中,我们开发了一个卷积递归网络,它本质上是一个编码器-解码器架构,在编码器和解码器之间有LSTMs。具体来说,编码器包括五个卷积层,而解码器包括五个去卷积层。在编码器和解码器之间,两个LSTM层对时间依赖性进行建模。编码器-解码器的结构是以对称的方式设计的:内核的数量在编码器中逐渐增加,在解码器中逐渐减少。为了沿频率方向汇总上下文,在所有卷积层和解卷积层中沿频率维度采用2的跨度。换句话说,特征图的频率维度在编码器中逐层减半,在解码器中逐层翻倍,这确保了输出与输入具有相同的形状。此外,跳过连接被用来将每个编码器层的输出与相应的解码器层的输入连接起来。在CRN中,所有的卷积和解旋都是因果关系,因此增强系统不使用未来信息。图2说明了[32]中的CRN架构,用于幅值域的频谱映射。
B 门控线性单元
门控机制控制着整个网络的信息流,这有可能允许对更复杂的相互作用进行建模。它们最早是为RNNs开发的[14]。在最近的一项研究中[34],Van den Oord等人采用了LSTM式的门控机制对图像进行卷积建模,这导致了掩盖式卷积。
$$公式8:\begin{aligned}
\mathbf{y} &=\tanh \left(\mathbf{x} * \mathbf{W}_{1}+\mathbf{b}_{1}\right) \odot \sigma\left(\mathbf{x} * \mathbf{W}_{2}+\mathbf{b}_{2}\right) \\
&=\tanh \left(\mathbf{v}_{1}\right) \odot \sigma\left(\mathbf{v}_{2}\right)
\end{aligned}$$
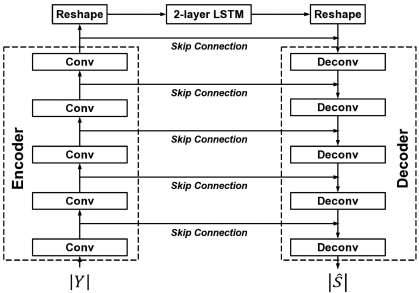
图2 [32] 中用于谱映射的 CRN 的图示
CRN 包含三个模块:编码器模块、LSTM 模块和解码器模块。 Conv表示卷积和Deconv反卷积
其中v1 = x ∗ W1 + b1,v2 = x ∗ W2 + b2。W’s和b’s分别表示内核和偏置,σ表示sigmoid函数。符号∗和分别代表卷积运算和逐元乘法。门控的梯度为
$$公式9:\begin{aligned}
\nabla\left[\tanh \left(\mathbf{v}_{1}\right) \odot \sigma\left(\mathbf{v}_{2}\right)\right]=& \tanh ^{\prime}\left(\mathbf{v}_{1}\right) \nabla \mathbf{v}_{1} \odot \sigma\left(\mathbf{v}_{2}\right) \\
&+\sigma^{\prime}\left(\mathbf{v}_{2}\right) \nabla \mathbf{v}_{2} \odot \tanh \left(\mathbf{v}_{1}\right)
\end{aligned}$$
其中tanh(v1), σ(v2)∈(0, 1),质数符号表示微分。由于降尺度因子tanh(v1)和σ(v2)的作用,随着网络深度的增加,梯度逐渐消失了。为了缓解这个问题,Dauphin等人[4]引入了GLU。
$$公式10:\begin{aligned}
\mathbf{y} &=\left(\mathbf{x} * \mathbf{W}_{1}+\mathbf{b}_{1}\right) \odot \sigma\left(\mathbf{x} * \mathbf{W}_{2}+\mathbf{b}_{2}\right) \\
&=\mathbf{v}_{1} \odot \sigma\left(\mathbf{v}_{2}\right)
\end{aligned}$$
梯度的GLU
$$公式11:\nabla\left[\mathbf{v}_{1} \odot \sigma\left(\mathbf{v}_{2}\right)\right]=\nabla \mathbf{v}_{1} \odot \sigma\left(\mathbf{v}_{2}\right)+\sigma^{\prime}\left(\mathbf{v}_{2}\right) \nabla \mathbf{v}_{2} \odot \mathbf{v}_{1}$$
包括一条没有降级的路径∇v1 σ(v2),它可以被看作是一个乘法的跳过连接,有利于梯度在各层中流动。图 3(a)是一个卷积 GLU 块(表示为 “ConvGLU”)的图示。去卷积GLU块(记为 “DeconvGLU”)是类似的,只是卷积层被去卷积层所取代,如图3(b)所示。
C 通过分组策略降低模型复杂度
模型的效率对于许多现实世界的应用是很重要的。例如,移动电话应用需要低延迟的实时处理。在这些应用中,高的计算效率和小的内存占用是必要的。Gao等人[9]最近提出了一种分组策略来提高递归层的效率,同时保持其性能。这种分组策略如图4所示。在一个循环层中,输入特征和隐藏状态都被分成互不相干的组,组内特征在每个组内分别学习,如图4(b)所示。分组操作大大减少了层间连接的数量,从而降低了模型的复杂性。然而,组间的依赖性不能被捕捉到。换句话说,一个输出只取决于相应特征组中的输入,这可能会大大降低表示能力。为了缓解这个问题,在两个连续的递归层之间采用了一个无参数的表征重排层来重排特征和隐藏状态,这样就可以恢复组间的相关性(图4©)。为了提高模型的效率,我们对模型中的LSTM层采用了这种分组策略。我们发现,这种策略在适当的组数下提高了增强性能。

图3 一个卷积GLU块和一个反卷积GLU块图,其中σ表示sigmoid函数。
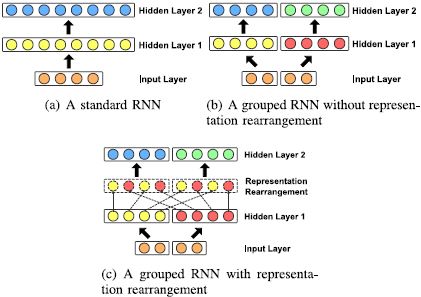
图4 rnn的分组策略示例
D 网络结构
这项研究扩展了[32]中的CRN架构(见图2),以执行复杂的谱映射。由此产生的CRN还结合了GLU,因此相当于一个门控卷积递归网络(GCRN)。图5描述了我们提出的GCRN架构。请注意,与[6]一样,噪声语音的实谱和虚谱被视为两个不同的输入通道。如图5所示,编码器模块和LSTM模块在估计实部和虚部时是共享的,而两个不同的解码器模块则分别用于估计实部和虚部的频谱。这种结构的设计受到多任务学习的启发[19], [45], 其中多个相关的预测任务被联合学习,并在任务间共享信息。对于复数谱映射,实部分的估计和虚部分的估计可以被视为两个相关的子任务(见[43])。因此,参数共享有望实现子任务之间的正则化效应,这可能导致更好的泛化。此外,参数共享可能会鼓励学习,特别是当两个子任务高度相关的时候。另一方面,子任务之间过度的参数共享可能会阻碍学习,特别是当两个子任务是弱相关的时候。因此,正确选择参数共享可能对性能很重要。在[33]中,我们研究了四种不同的参数共享机制。其中,共享编码器模块和LSTM模块而不共享解码器模块会导致最佳性能。
在这项研究中,我们假设所有的信号都是以16千赫兹采样的。利用一个20ms的汉明窗来产生一组时间帧,相邻时间帧之间有50%的重叠。我们使用161维频谱,这相当于320点STFT(16 kHz × 20 ms)。
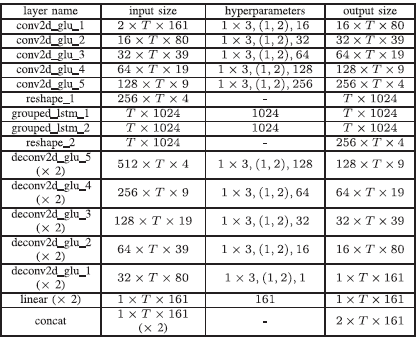
表一提供了我们提出的网络结构的细节。 每层的输入大小和输出大小是以featureMaps × timeSteps × frequencyChannels的格式给出的。此外,层的超参数以(kernelSize, strides, outChannels)的格式指定。请注意,每个解码器层的特征图的数量因跳过连接而增加一倍。我们没有使用[32]中的2×3(时间×频率)的核大小,而是使用了1×3的核大小,我们发现这并不会降低性能。每个卷积或解卷积的GLU块后面都有一个批量归一化[16]操作和一个指数线性单元(ELU)[3]激活函数。在每个解码器的顶部叠加一个线性层,将学到的特征投射到实数或虚数谱图上。
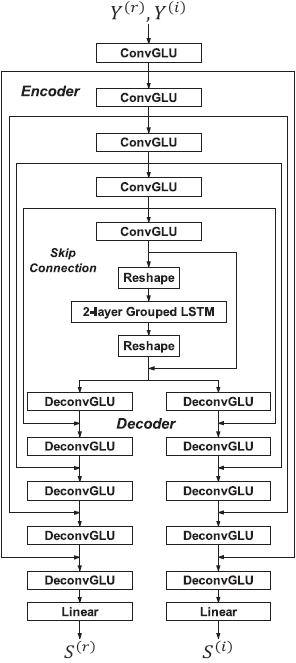
图5 用于复数谱映射的GCRN的网络结构。更多详情见表一
表1 提出了GCRN架构,其中t表示谱图中的时间帧数
4 实验步骤
A 数据准备
在我们的实验中,我们在WSJ0 SI-84训练集[26]上评估所提出的模型,该训练集包括来自83个说话人(42个男性和41个女性)的7138个语料。我们将这些说话人中的6个(3个男性和3个女性)留作测试用,没有经过训练。换句话说,我们用剩下的77个说话者来训练模型。在这77个训练者的语料中,我们从NOISEX-92数据集[35]中随机抽出150个语料,用工厂噪声(称为 “factory1”)创建一个验证集,信噪比为-5dB。对于训练,我们使用来自一个声音效果库(可在https://www.soundideas.com)的10,000个噪音,其总时长约为126小时。 对于测试,我们使用两个高度非平稳的噪音,即咿呀声(“BAB”)和食堂(“CAF”),来自Auditec CD(可在http://www.auditec.com)。
我们的训练集包含32万个混合物,其总时间约为500小时。具体来说,为了创建一个训练混合物,我们将一个随机选择的训练语料与10,000个训练噪声中的一个随机片段进行混合。信噪比从{-5, -4, -3, -2, -1, 0}dB中随机抽取。我们的测试集由150个混合物组成,这些混合物是由6个未训练过的说话人的25×6句话创建的。我们对测试集使用三种信噪比,即-5、0和5dB。
B 基线和培训方法
我们将我们提出的方法与五个基线进行比较。我们首先训练一个CRN,将噪声语音的幅度谱映射到纯净语音的幅度谱[32](表示为 “CRN + TMS”)。估计的幅值与噪声相位相结合,重新合成波形。在第二条基线(表示为 “CRN-RI + TMS”)中,同样的CRN被用来从噪声语音的实部和虚部频谱映射到纯净语音的幅度频谱。第三,如[6]所述,训练一个CNN来执行复数谱映射。它有四个卷积层,有50个核,核大小为1×25,然后是两个全连接层,每层有512个单元。除输出层外,所有层都采用了参数化整流线性单元(PReLUs)[13]。 在输出层,322个(161×2)线性激活单元被用来预测实数和虚数谱。第四,我们训练我们提出的GCRN来预测cIRM。请注意,cIRM的实部和虚部可能在(-∞, +∞)中有很大的范围,这可能使cIRM的估计变得复杂。 因此,我们按照[43]中的建议,用以下双曲正切来压缩cIRM。
$$公式12:O^{(x)}=K \frac{1-e^{-C \cdot M^{(x)}}}{1+e^{-C \cdot M^{(x)}}}$$
其中x表示r或i,分别表示实部和虚部。在推理过程中,未压缩的掩码的估计值可按以下方式恢复。
$$公式13:\hat{M}^{(x)}=-\frac{1}{C} \log \left(\frac{K-\hat{O}^{(x)}}{K+\hat{O}^{(x)}}\right)$$
其中Oˆ(x)表示GCRN的输出。如[43]所述,我们设定K=10,C=0.1。第五,我们用cRM-SA作为训练目标,训练相同的GCRN。
模型的训练使用AMSGrad优化器[27],学习率为0.001。我们使用平均平方误差(MSE)作为目标函数。在语料层面上,迷你批的大小被设定为4。在一个minibatch中,所有的训练样本都用零填充,使其具有与最长样本相同的时间步长。通过交叉验证选择最佳模型。
表2 STOI和PESQ在5db信噪比下不同方法的比较
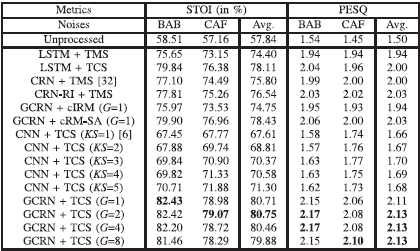
表3 在0 dB信噪比下STOI和PESQ方法的比较
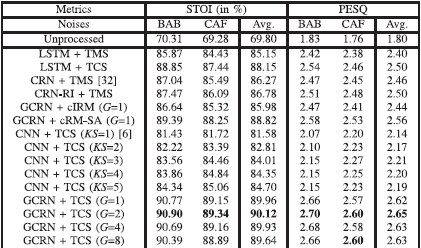
表4 STOI和PESQ在5db信噪比下不同方法的比较

5 实验结果与分析
A 实验结果比较
表二、三和四分别显示了不同模型和训练目标之间在STOI和PESQ方面的综合比较,即-dB、0dB和5dB信噪比。 数字代表了每个测试条件下测试样本的平均数。每个测试条件下的最佳分数用黑体字突出。KS表示时间方向上的核大小,G表示分组LSTM层的组数。 注意,G=1意味着不进行分组。我们首先比较了我们提出的以TCS为训练目标的不同组数的GCRN结构,如表II、III和IV的最后四行所示。可以看出,G=1、G=2、G=4和G=8在两个指标方面都产生了类似的结果,这表明分组策略的有效性。
此外,我们提出的GCRN模型大大超过了[6]中的CNN(KS = 1)。例如,在信噪比为-5dB的情况下,G=2的GCRN比CNN提高了13.14%的STOI,PESQ提高了0.47。在核大小为1×25的情况下,CNN只捕获了沿频率方向的上下文,没有学习时间上的依赖性。相比之下,我们提出的GCRN同时考虑了语音的频率和时间背景。我们通过在时间方向上使用不同的核大小来研究[6]中的CNN的时间背景的影响。具体来说,除了[6]中的原始版本(即1×25)之外,我们使用了四种不同的核大小,即2×25、3×25、4×25和5×25。请注意,这些核只对当前和过去的时间框架进行操作,这相当于因果卷积。通过四个卷积层,这些CNN分别对应于5、9、13和17帧的不同时间背景窗口大小。如表二、三和四所示,较大的上下文窗口尺寸产生较高的STOI,但在PESQ方面略有改善或没有改善。
以cRM-SA作为训练目标,我们提出的GCRN产生的STOI和PESQ明显优于使用cIRM的相同GCRN。从cRM-SA到TCS进一步改善了这两个指标。以-5dB信噪比的情况为例。与估计的cIRM相比,采用cRM-SA的拟议GCRN(G=1)产生了3.68%的STOI改进和0.09的PESQ改进。估算的TCS还实现了2.28%的STOI改善和0.08的PESQ改善。
我们现在比较幅度域和复数域的谱映射。如表二、三和四所示,"CRN + TMS "和 "CRN-RI + TMS "利用相同的模型和训练目标,但输入特征不同。使用噪声语音的实谱和虚谱作为特征,产生的STOI和PESQ比使用噪声幅度谱略好。我们提出的方法(表示为 “GCRN + TCS”),利用TCS作为训练目标,比 "CRN-RI + TMS "大大提高了STOI和PESQ。例如,"GCRN + TCS (G = 2) "在信噪比为-5 dB时,比 "CRN-RI + TMS "提高了4.21%的STOI,PESQ提高了0.1。
为了进一步证明复数谱映射的有效性,我们另外用TMS和TCS分别训练两个LSTM模型。两个LSTM模型都有四个堆叠的LSTM隐藏层,每层有1024个单元,一个全连接层被用来估计TMS和TCS,分别有一个softplus激活函数[10]和一个线性激活函数。如表二、三和四所示,复数谱映射产生的STOI和PESQ一直比幅度频谱映射高。
此外,图6显示了比未经处理的混合物的信噪比改进(ΔSNR)。可以看出,我们提出的方法比基线产生了更大的信噪比改善,在-5dB时,信噪比改善超过了12dB。图7(a)显示了不同模型中可训练参数的数量,图7(b)显示了为处理一个时间框架而进行的浮点融合乘法的数量。通过分组策略,我们提出的模型在计算成本和内存消耗方面都比[32]中的CRN效率更高。[6]中的CNN的可训练参数要少得多,但计算成本比[32]中的CRN要高。在G4中,我们提出的GCRN具有与CNN相当的参数数量,但在计算上要高效得多。此外,图8显示了GCRN以cIRM、cRM-SA和TCS为训练目标的纯净语音、噪声语音和增强语音的谱图实例。我们可以看到,在用估计的cIRM或cRM-SA增强的语音的频谱中,一些语音成分被丢失。相比之下,通过估计的TCS增强的语音表现出与纯净语音更相似的谱时调制模式,并且比通过估计的cIRM或cRM-SA增强的语音失真更少。
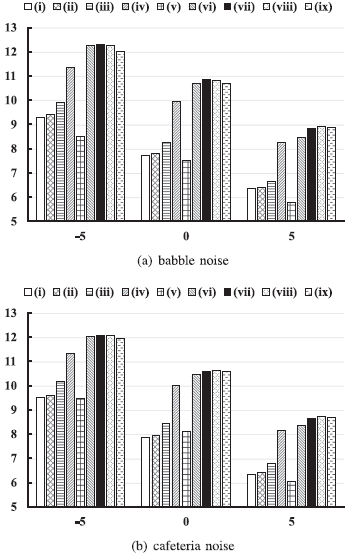
图6 5、0 和 5 dB 的未处理混合的 ΔSNR(以 dB 为单位)。
方法是 (i) CRN+TMS [32], (ii) CRN-RI+TMS, (iii) GCRN+cIRM (G = 1), (iv) GCRN + cRM-SA (G = 1), (v ) CNN + TCS [6], (vi) GCRN + TCS (G = 1), (vii) GCRN + TCS (G = 2), (viii) GCRN + TCS (G = 4) 和 (ix) GCRN + TCS (G = 8)。
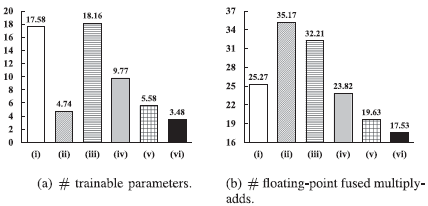
图7 不同模型中每个时间范围 (b) 的可训练参数 (a) 和浮点融合乘加的数量。 两部分的单位都是百万。
模型是 (i) CRN [32], (ii) CNN [6], (iii) GCRN (G = 1), (iv) GCRN (G = 2), (v) GCRN (G = 4) 和 ( vi) GCRN (G = 8),分别。
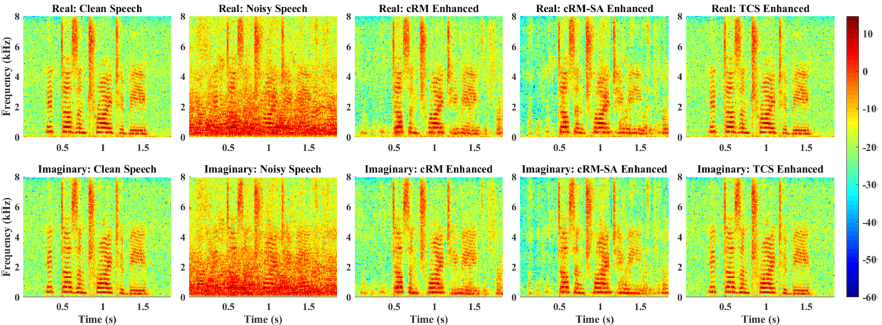
图8 清晰语音、嘈杂语音、cRM 增强语音、估计 cRM-SA 增强语音和估计 TCS 增强语音的实部(顶部)和虚部(底部)频谱的图示。 实部和虚部频谱的绝对值绘制在对数刻度上。
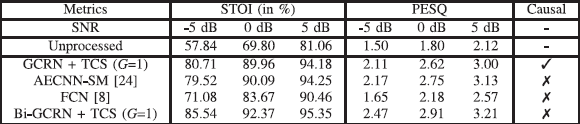
表5 建议的方法和时域方法的比较。 这里√表示因果模型,×表示非因果模型
我们还将我们提出的方法与最近的两种时域语音增强方法进行比较。AECNN-SM(具有STFT幅度损失的自动编码器CNN)[24]和FCN(全卷积网络)[8]。此外,我们还训练了一个非因果版本的GCRN(表示为 “Bi-GCRN”),其中中间的LSTM层被相应的双向LSTM层所取代。比较结果见表五,其中的数字代表了两个测试噪声的平均值。我们可以看到,GCRN在-5dB时比AECNN-SM提高了1.19%的STOI,而GCRN和AECNN-SM在0dB和5dB时产生类似的STOI。在PESQ方面,AECNN-SM的表现一直优于GCRN。 应该注意的是,AECNN-SM方法使用的时间框架大小(即2048)比我们的方法(即320)大得多,这可能对AECNN-SM有益。还可以看到,我们的方法在STOI和PESQ方面都大大超过了FCN。此外,Bi-GCRN产生的STOI和PESQ明显高于GCRN。这并不令人惊讶,因为未来的帧显然包含了对语音增强有用的信息。
B 相位估计的评估
如果噪声具有不同的相位,语音信号的相
图9 图示不同条件下的相位误差
表6 不同信噪比下相位距离对杂波噪声的影响

表7 相位距离对不同信噪比下自助食堂噪声的影响

复数谱映射提供了一个相位估计,即用两个未知数解出以下两个方程。
$$公式14:\hat{S}^{(r)}=|\hat{S}| \cos \left(\hat{\theta}_{S}\right)$$
$$公式15:\hat{S}^{(i)}=|\hat{S}| \sin \left(\hat{\theta}_{S}\right)$$
其中Sˆ(r)和Sˆ(i)是网络输出。为了评估估计的相位,我们采用两种相位测量方法。第一个是目标谱图S和估计的谱图Sˆ之间的相位距离(PD),定义在[2]中。
$$公式16:P D(S, \hat{S})=\sum_{m, f} \frac{\left|S_{m, f}\right|}{\sum_{m,^{\prime} f^{\prime}}\left|S_{m,^{\prime} f^{\prime}}\right|} \angle\left(S_{m, f}, \hat{S}_{m, f}\right)$$
其中∠(Sm,f, Sˆm,f) ∈ [0◦, 180◦] 表示Sm,f和Sˆm,f之间的角度。相位距离可以看作是相应的T-F单元之间角度的加权平均值,其中每个T-F单元由目标谱图的幅度加权,以强调该单元的相对重要性。第二个措施是通过比较使用三种相位重新合成的时域信号来量化估计相位的影响:噪声相位、估计相位和清洁相位。这些相位与三种不同的幅度相结合:噪声幅度、由[32]中的CRN估计器增强的幅度和清洁幅度。
我们评估了两种估计相位,它们是由我们提出的方法(即 “GCRN + TCS (G = 1)”)所增强的频谱计算出来的。 “GCRN + TCS (G = 1)”)和 “GCRN + cIRM (G = 1)”。表六和表七分别列出了在咿咿呀呀的噪声和食堂噪声上,纯净频谱和噪声频谱之间的相位距离(PD(S,Y))以及纯净频谱和增强的频谱之间的相位距离(PD(S,Sˆ))。数字代表每个测试条件下测试样本的平均值和标准偏差。我们可以看到,复数谱映射在每个条件下都能改善相位。例如,在-5dB的食堂噪声上,相位距离平均提高了8.246◦。此外,就相位距离而言,"GCRN + TCS (G = 1) "产生的相位始终比 "GCRN + cIRM (G = 1) "好。
表八、九和十分别列出了从噪声相位、估计相位和清洁相位重新合成的信号的比较。如表八所示,仅通过增强相位而保持噪声幅度不改变,客观可懂度和感知质量都得到了改善。例如,通过 "GCRN + TCS (G = 1) "估计的相位,在-5 dB信噪比下,比噪声相位提高了1.38%的STOI和0.12的PESQ。清洁阶段在-5分贝的情况下,STOI增加了2.05%,PESQ增加了0.1。从表九中,我们可以看到,增强相位可以进一步提高 STOI 和 PESQ,而不是仅仅增强幅度,特别是在低信噪比条件下(如 -5 dB),相位严重下降。 如表十所示,在幅度纯净情况下,估计的相位比噪声相位的STOI和PESQ都有所提高。 此外,用 "GCRN + TCS (G = 1) "估计的相位始终比用 "GCRN + cIRM (G = 1) "估计的相位高。
上述评价还表明,使用噪声相位是不进行相位增强的传统方法的一个重要限制。我们的复数谱映射提供了一个有效的相位估计,避免了对噪声相位的使用。
6 结论
在这项研究中,我们提出了一个使用卷积递归网络进行复数谱映射的新框架,该框架从嘈杂语音的实部和虚部频谱学习到纯净语音的频谱。它能同时增强噪声语音的幅值和相位响应。 受多任务学习的启发,所提出的方法扩展了一个新开发的CRN,并产生了一个因果关系,以及与噪音和扬声器无关的单声道语音增强算法。我们的实验结果表明,用我们提出的模型进行复数谱映射,比幅度频谱映射以及复杂比率掩码和基于复杂比率掩码的信号近似,明显改善了STOI和PESQ。此外,我们提出的模型在复数谱映射方面大大超过了现有的CNN。 此外,我们在递归层中加入了分组策略,在保持性能的同时大幅提高了模型效率。
我们提出的方法还提供了一个相位估计,证明它比噪声相位更接近清洁相位。从另一个角度来看,我们发现,当与噪声幅度或增强幅度相结合时,估计相位产生的STOI和PESQ明显高于噪声相位。
应该指出的是,纯净语音可以从目标复数谱图中完美地恢复出来。我们相信,基于GCRN的复数谱映射的方法代表了在不利的声学环境和实际应用中产生高质量增强语音的重要一步。在未来的研究中,我们计划将我们的方法扩展到多通道语音增强,其中准确的相位估计可能更加重要。
表8 在stoi和pesq中,噪声相位、估计相位和纯净相位与噪声幅度的比较

表9 比较stoi和pesq中结合增强幅度的噪声相位、估计相位和清洁相位

表10 stoi和pesq中噪声相位、估计相位和纯净相位与纯净幅度的比较

致谢
作者想要感谢A. Pandey提供他的AECNN-SM实现来进行比较。
参考文献
[1] J. Chen and D. L. Wang, Long short-term memory for speaker generalization in supervised speech separation, J. Acoust. Soc. Am., vol. 141, no. 6, pp. 4705 4714, 2017.
[2] H.-S. Choi, J.-H. Kim, J. Huh, A. Kim, J.-W. Ha, and K. Lee, Phase-aware speech enhancement with deep complex u-net, 2019, arXiv:1903.03107.
[3] D.-A. Clevert, T. Unterthiner, and S. Hochreiter, Fast and accurate deep network learning by exponential linear units (ELUS), in Proc. Int. Conf. Learn. Represent., 2016.
[4] Y. N. Dauphin, A. Fan, M. Auli, and D. Grangier, Language modeling with gated convolutional networks, in Proc. 34th Int. Conf.Mach. Learn., 2017, vol. 70, pp. 933 941.
[5] H. Erdogan, J. R. Hershey, S.Watanabe, and J. Le Roux, Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks, in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2015, pp. 708 712.
[6] S.-W. Fu, T.-Y. Hu, Y. Tsao, and X. Lu, Complex spectrogram enhancement by convolutional neural network with multi-metrics learning, in Proc. IEEE 27th Int. Workshop Mach. Learn. Signal Process., 2017.
[7] S.-W. Fu, Y. Tsao, and X. Lu, SNR-aware convolutional neural network modeling for speech enhancement, in Proc. 17th Annu. Conf. Int. Speech Commun. Assoc., 2016, pp. 3768 3772.
[8] S.-W. Fu, T.-W. Wang, Y. Tsao, X. Lu, and H. Kawai, End-to-end waveform utterance enhancement for direct evaluation metrics optimization by fully convolutional neural networks, IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 26, no. 9, pp. 1570 1584, Sep. 2018.
[9] F. Gao, L. Wu, L. Zhao, T. Qin, X. Cheng, and T.-Y. Liu, Efficient sequence learning with group recurrent networks, in Proc. Conf. North Am. Chapter Assoc. Comput. Linguist.: Human Lang. Technol., Volume 1 (Long Papers), 2018, vol. 1, pp. 799 808.
[10] X. Glorot, A. Bordes, and Y. Bengio, Deep sparse rectifier neural networks, in Proc. 14th Int. Conf. Artif. Intell. Statist., 2011, pp. 315 323.
[11] E. M. Grais andM. D. Plumbley, Single channel audio source separation using convolutional denoising autoencoders, in Proc. IEEE Global Conf. Signal Inf. Process., 2017, pp. 1265 1269.
[12] K. Han, Y.Wang, and D. L.Wang, Learning spectral mapping for speech dereverberation, in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2014, pp. 4628 4632.
[13] K. He, X. Zhang, S. Ren, and J. Sun, Delving deep into rectifiers: Surpassing human-level performance on imagenet classification, in Proc. IEEE Int. Conf. Comput. Vis., 2015, pp. 1026 1034.
[14] S. Hochreiter and J. Schmidhuber, Long short-term memory, Neural Comput., vol. 9, no. 8, pp. 1735 1780, 1997.
[15] P.-S. Huang, M. Kim, M. Hasegawa-Johnson, and P. Smaragdis, Deep learning formonaural speech separation, in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2014, pp. 1562 1566.
[16] S. Ioffe and C. Szegedy, Batch normalization: Accelerating deep network training by reducing internal covariate shift, in Proc. Int. Conf. Mach. Learn., 2015, pp. 448 456.
[17] M. Krawczyk and T. Gerkmann, STFT phase reconstruction in voiced speech for an improved single-channel speech enhancement, IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 22, no. 12, pp. 1931 1940, Dec. 2014.
[18] J. Kulmer and P. Mowlaee, Phase estimation in single channel speech enhancement using phase decomposition, IEEE Signal Process. Lett., vol. 22, no. 5, pp. 598 602, May 2015.
[19] A.Kumar and H. Daumé III, Learning task grouping and overlap in multitask learning, in Proc. 29th Int.Conf.Mach. Learn., 2012, pp. 1383 1390.
[20] X. Lu, Y. Tsao, S. Matsuda, and C. Hori, Speech enhancement based on deep denoising autoencoder, in Proc. Interspeech, 2013, pp. 436 440.
[21] P. Mowlaee, R. Saeidi, and R. Martin, Phase estimation for signal reconstruction in single-channel source separation, in Proc. 13th Annu. Conf. Int. Speech Commun. Assoc., 2012, pp. 1548 1551.
[22] G. Naithani, T. Barker, G. Parascandolo, L. Bramsl, N. H. Pontoppidan, and T.Virtanen, Lowlatency sound source separation using convolutional recurrent neural networks, in Proc. IEEEWorkshop Appl. Signal Process. Audio Acoust., 2017, pp. 71 75.
[23] K. Paliwal, K. Wójcicki, and B. Shannon, The importance of phase in speech enhancement, Speech Commun., vol. 53, no. 4, pp. 465 494, 2011.
[24] A. Pandey and D. L. Wang, A new framework for supervised speech enhancement in the time domain, in Proc. Interspeech, 2018, pp. 1136 1140.
[25] S. R. Park and J.W. Lee, A fully convolutional neural network for speech enhancement, in Proc. 18th Annu. Conf. Int. Speech Commun. Assoc., 2017, pp. 1993 1997.
[26] D. B. Paul and J. M. Baker, The design for the wall street journal-based CSRcorpus, in Proc.Workshop SpeechNatural Lang., 1992, pp. 357 362.
[27] S. J. Reddi, S. Kale, and S. Kumar, On the convergence of adam and beyond, in Proc. Int. Conf. Learn. Represent., 2018.
[28] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, Perceptual evaluation of speech quality (PESQ) A new method for speech quality assessment of telephone networks and codecs, in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2001, vol. 2, pp. 749 752.
[29] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, An algorithm for intelligibility prediction of time frequency weighted noisy speech, IEEE Trans. Audio, Speech, Lang. Process., vol. 19, no. 7, pp. 2125 2136, Sep. 2011.
[30] N. Takahashi, N. Goswami, and Y.Mitsufuji, Mmdenselstm: An efficient combination of convolutional and recurrent neural networks for audio source separation, in Proc. 16th Int. Workshop Acoust. Signal Enhancement, 2018, pp. 106 110.
[31] K. Tan, J. Chen, and D. L. Wang, Gated residual networks with dilated convolutions for monaural speech enhancement, IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 27, no. 1, pp. 189 198, Jan. 2019.
[32] K. Tan and D. L. Wang, A convolutional recurrent neural network for real-time speech enhancement, in Proc. 19th Annu. Conf. Int. Speech Commun. Assoc., 2018, pp. 3229 3233.
[33] K. Tan and D. L.Wang, Complex spectral mapping with a convolutional recurrent network for monaural speech enhancement, in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2019, pp. 6865 6869.
[34] A. Van Den Oord, N. Kalchbrenner, L. Espeholt, O. Vinyals, A. Graves, et al., Conditional image generation with pixelcnn decoders, in Proc. Adv. Neural Inf. Process. Syst., 2016, pp. 4790 4798.
[35] A. Varga and H. J. Steeneken, Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems, Speech Commun., vol. 12, no. 3, pp. 247 251, 1993.
[36] D. L.Wang andG. J.Brown, Eds, Computational Auditory Scene Analysis: Principles, Algorithms, and Applications. Hoboken, NJ, USA: Wiley, 2006.
[37] D. L. Wang and J. Lim, The unimportance of phase in speech enhancement, IEEE Trans. Acoust., Speech, Signal Process., vol. ASSP-30, no. 4, pp. 679 681, Aug. 1982.
[38] Y. Wang, A. Narayanan, and D. L. Wang, On training targets for supervised speech separation, IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 22, no. 12, pp. 1849 1858, Dec. 2014.
[39] Y.Wang and D. L.Wang, A deep neural network for time-domain signal reconstruction, in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2015, pp. 4390 4394.
[40] F. Weninger et al., Speech enhancement with LSTM recurrent neural networks and its application to noise-robust ASR, in Proc. Int. Conf. Latent Variable Anal. Signal Sepa., 2015, pp. 91 99.
[41] F.Weninger, F. Eyben, and B. Schuller, Single-channel speech separation with memory-enhanced recurrent neural networks, in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2014, pp. 3709 3713.
[42] F.Weninger, J. R. Hershey, J. Le Roux, and B. Schuller, Discriminatively trained recurrent neural networks for single-channel speech separation, in Proc. 2nd IEEE Global Conf. Signal Inf. Process. Symp. Mach. Learn. Appl. Speech Process., 2014, pp. 577 581.
[43] D. S. Williamson, Y. Wang, and D. L. Wang, Complex ratio masking for monaural speech separation, IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 24, no. 3, pp. 483 492, 2016.
[44] Y. Xu, J. Du, L.-R. Dai, and C.-H. Lee, An experimental study on speech enhancement based on deep neural networks, IEEE Signal Process. Lett., vol. 21, no. 1, pp. 65 68, Jan. 2014.
[45] Y. Zhang and Q. Yang, An overview of multi-task learning, Nat. Sci. Rev., vol. 5, no. 1, pp. 30 43, 2018. [46] H. Zhao, S. Zarar, I. Tashev, and C.-H. Lee, Convolutional-recurrent neural networks for speech enhancement, in Proc. IEEEInt. Conf.Acoust., Speech Signal Process., 2018, pp. 2401 2405.
























