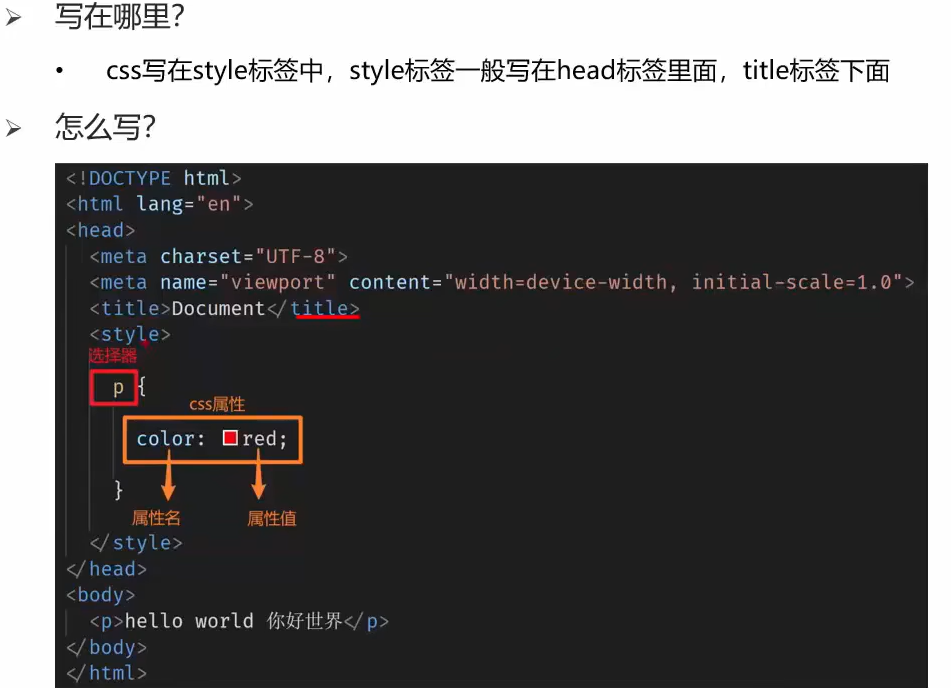
1 import requests 2 from lxml import etree 3 4 header = { 5 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36" 6 } 8 9 def spider(page_num): 10 url = f"https://www.169tp.com/xingganmeinv/list_1_{page_num}.html" 11 12 # 获取到网页初始数据text 13 res = requests.get(url, headers=header) 14 res.encoding = 'gbk' 15 text = res.text 16 tree = etree.HTML(text) 17 18 lis = tree.xpath("/html/body/div[4]/ul/li") 19 20 for i in lis: 21 addr = i.xpath("./a/img/@src")[0] 22 title = i.xpath("./a/p/text()") 23 24 detail = requests.get(addr,headers=header).content 25 26 f = open(f"imgs/{title}.jpg", mode="wb") 27 f.write(detail) 28 f.close() 29 print(f"图片 --------- {title} ------------- 完成!!") 30 31 32 def start(): 33 for i in range(1,101): 34 spider(i) 35 36 37 if __name__ == '__main__': 38 start()