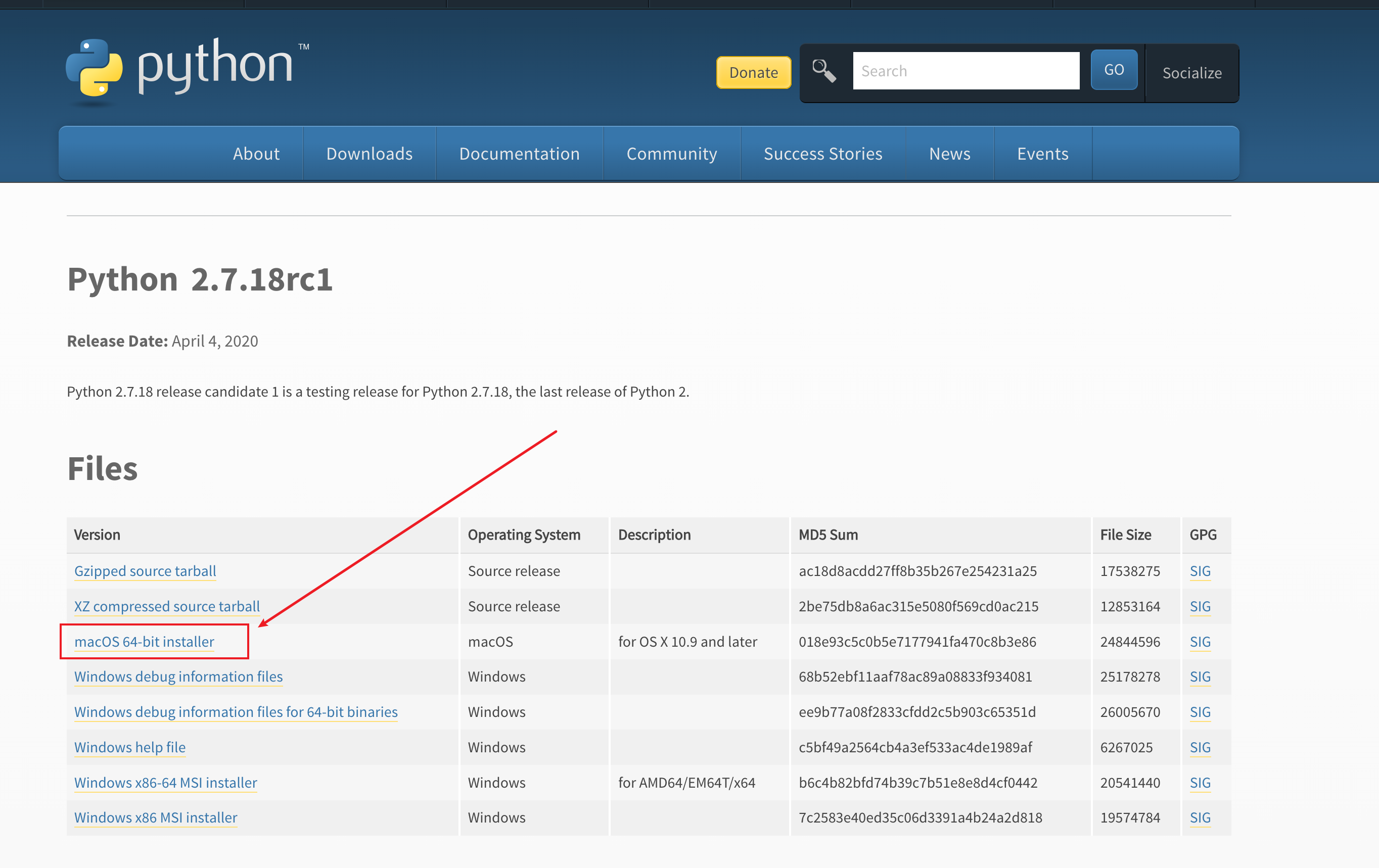
1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。


Spark生态系统主要包含Spark Core、Spark SQL、Spark Streaming、MLib、GraphX以及独立调度器,下面对上述组件进行一一介绍。
(1)Spark Core:Spark核心组件,它实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed Datasets,RDD)的API定义,RDD是只读的分区记录的集合,只能基于在稳定物理存储中的数据集和其他已有的RDD上执行确定性操作来创建。
(2)Spark SQL:用来操作结构化数据的核心组件,通过Spark SQL可以直接查询Hive、 HBase等多种外部数据源中的数据。Spark SQL的重要特点是能够统一处理关系表和RDD在处理结构化数据时,开发人员无须编写 MapReduce程序,直接使用SQL命令就能完成更加复杂的数据查询操作。
(3)Spark Streaming:Spark提供的流式计算框架,支持高吞吐量、可容错处理的实时流式数据处理,其核心原理是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业都可以使用 Spark Core进行快速处理。Spark Streaming支持多种数据源,如 Kafka以及TCP套接字等。
(4)MLlib:Spark提供的关于机器学习功能的算法程序库,包括分类、回归、聚类、协同过滤算法等,还提供了模型评估、数据导入等额外的功能,开发人员只需了解一定的机器学习算法知识就能进行机器学习方面的开发,降低了学习成本。
(5) GraphX: Spark提供的分布式图处理框架,拥有图计算和图挖掘算法的API接口以及丰富的功能和运算符,极大地方便了对分布式图的处理需求,能在海量数据上运行复杂的图算法。
(6)独立调度器、Yarn、 Mesos: Spark框架可以高效地在一个到数千个节点之间伸缩计算,集群管理器则主要负责各个节点的资源管理工作,为了实现这样的要求,同时获得最大的灵活性, Spark支持在各种集群管理器( Cluster Manager)上运行, Hadoop Yarn、Apache Mesos以及 Spark自带的独立调度器都被称为集群管理器。
Spark生态系统各个组件关系密切,并且可以相互调用,这样设计具有以下显著优势。
(1) Spark生态系统包含的所有程序库和高级组件都可以从 Spark核心引擎的改进中获益。
(2)不需要运行多套独立的软件系统,能够大大减少运行整个系统的资源代价。
(3)能够无缝整合各个系统,构建不同处理模型的应用。
综上所述,Spak框架对大数据的支持从内存计算、实时处理到交互式查询,进而发展到图计算和机器学习模块。Spark生态系统广泛的技术面,一方面挑战占据大数据市场份额最大的Hadoop,另一方面又随时准备迎接后起之秀Flink、Kafka等计算框架的挑战,从而使Spark在大数据领域更好地发展。
2.请详细阐述Spark的几个主要概念及相互关系:
RDD:RDD(Resilient Distributed Datasets)弹性分布式数据集,有例如以下几个特点:
1、它在集群节点上是不可变的、已分区的集合对象。
2、通过并行转换的方式来创建。如map, filter, join等。
3、失败自己主动重建。
4、能够控制存储级别(内存、磁盘等)来进行重用。
5、必须是可序列化的。
6、是静态类型的。
RDD本质上是一个计算单元。能够知道它的父计算单元。


RDD 是Spark进行并行运算的基本单位。
RDD提供了四种算子:
1、输入算子:将原生数据转换成RDD,如parallelize、txtFile等
2、转换算子:最基本的算子,是Spark生成DAG图的对象。
转换算子并不马上执行,在触发行动算子后再提交给driver处理,生成DAG图 –> Stage –> Task –> Worker执行。
按转化算子在DAG图中作用。能够分成两种:
窄依赖算子
输入输出一对一的算子,且结果RDD的分区结构不变,主要是map、flatMap;
输入输出一对一的算子,但结果RDD的分区结构发生了变化,如union、coalesce;
从输入中选择部分元素的算子。如filter、distinct、subtract、sample。
宽依赖算子
宽依赖会涉及shuffle类,在DAG图解析时以此为边界产生Stage。
对单个RDD基于key进行重组和reduce,如groupByKey、reduceByKey;
对两个RDD基于key进行join和重组。如join、cogroup。
3、缓存算子:对于要多次使用的RDD,能够缓冲加快执行速度,对关键数据能够採用多备份缓存。
4、行动算子:将运算结果RDD转换成原生数据,如count、reduce、collect、saveAsTextFile等。

RDD支持两种操作:
转换(transformation)从现有的数据集创建一个新的数据集
动作(actions)在数据集上执行计算后,返回一个值给驱动程序
比如。map就是一种转换,它将数据集每个元素都传递给函数,并返回一个新的分布数据集表示结果。而reduce是一种动作。通过一些函数将全部的元素叠加起来,并将终于结果返回给Driver程序。(只是另一个并行的reduceByKey。能返回一个分布式数据集)
Spark中的全部转换都是惰性的,也就是说,他们并不会直接计算结果。相反的。它们仅仅是记住应用到基础数据集(比如一个文件)上的这些转换动作。仅仅有当发生一个要求返回结果给Driver的动作时,这些转换才会真正执行。这个设计让Spark更加有效率的执行。
比如我们能够实现:通过map创建的一个新数据集,并在reduce中使用,终于仅仅返回reduce的结果给driver,而不是整个大的新数据集。
默认情况下,每个转换过的RDD都会在你在它之上执行一个动作时被又一次计算。
只是。你也能够使用persist(或者cache)方法,持久化一个RDD在内存中。
在这样的情况下,Spark将会在集群中。保存相关元素。下次你查询这个RDD时。它将能更高速訪问。
在磁盘上持久化数据集或在集群间复制数据集也是支持的。
Spark中支持的RDD转换和动作

除了这些操作以外,用户还能够请求将RDD缓存起来。而且。用户还能够通过Partitioner类获取RDD的分区顺序,然后将另一个RDD依照相同的方式分区。有些操作会自己主动产生一个哈希或范围分区的RDD,像groupByKey,reduceByKey和sort等。
执行和调度

第一阶段记录变换算子序列、增带构建DAG图。
第二阶段由行动算子触发,DAGScheduler把DAG图转化为作业及其任务集。Spark支持本地单节点执行(开发调试实用)或集群执行。对于集群执行,客户端执行于master带点上,通过Cluster manager把划分好分区的任务集发送到集群的worker/slave节点上执行。
配置

3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。
>>> sc
>>> lines = sc.textFile("file:///home/hadoop/my.txt")
>>> lines
>>> words=lines.flatMap(lambda line:line.split())
>>> words
>>> wordKV=words.map(lambda word:(word,1))
>>> wordKV
>>> wc=wordKV.reduceByKey(lambda a,b:a+b)
>>> wc
>>> cs=lines.flatMap(lambda line:list(line))
>>> cs
>>> cKV=cs.map(lambda c:(c,1))
>>> cKV
>>> cc=cKV.reduceByKey(lambda a,b:a+b)
>>> cc
>>> lines.foreach(print)
>>> words.foreach(print)
>>> wordKV.foreach(print)
>>> cs.foreach(print)
>>> cKV.foreach(print)
>>> wc.foreach(print)
>>> cc.foreach(print)
自己生成sc
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc=SparkContext(conf=conf)