python-正则表达式
1. python-正则表达式
正则表达式是对字符串操作的一种逻辑方式,就是用预先定义好的一些特定字符及这些特定字符的组合,组成一个规则字符串,这个规则字符串就是表达对字符串的逻辑,给定一个正则表达式和另一个字符串,通过正则表达式从字符串提取我们想要的部分。
-
re 标准库
Python正则表达式主要由re标准库提供,拥有了基本所有的表达式。
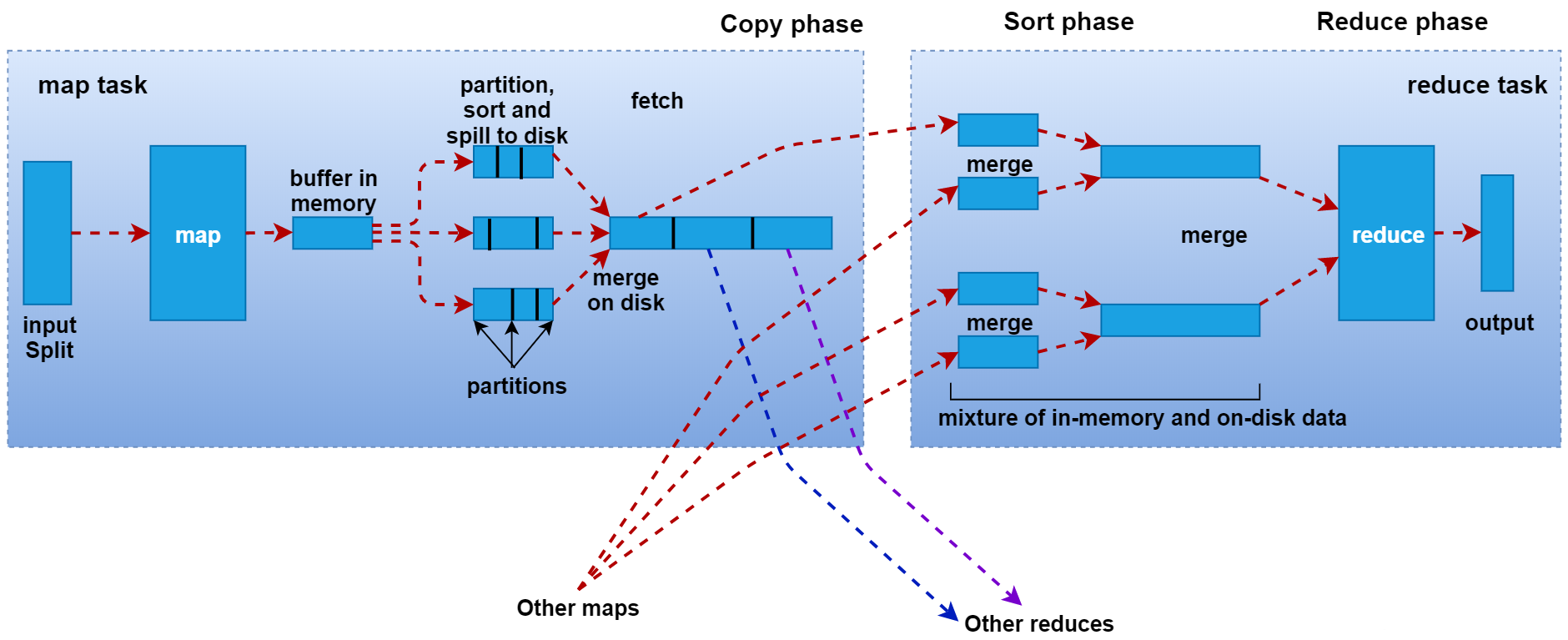
方法 描述 re.compile(pattern, flags=0) 把正则表达式编译成一个对象 re.match(pattern, string, flags=0) 匹配字符串开始,如果不匹配返回None re.search(pattern, string, flags=0) 扫描字符串寻找匹配,如果符合返回一个匹配对象并终止匹配,否则返回None re.split(pattern, string, maxsplit=0, flags=0) 以匹配模式作为分隔符,切分字符串为列表 re.findall(pattern, string, flags=0) 以列表形式返回所有匹配的字符串 re.finditer(pattern, string, flags=0) 以迭代器形式返回所有匹配的字符串 re.sub(pattern, repl, string, count=0, flags=0) 字符串替换,repl替换匹配的字符串,repl可以是一个函数 -
re.compile方法
-
语法格式
re.compile(pattern, flags=0)pattern 指的是正则表达式。flags是标志位的修饰符,用于控制表达式匹配模式
-
示例
import re s = "this is test string" pattern = re.compile('this') result = pattern.match(s) print(result.group()) #匹配成功后,result对象会增加一个group()方法,可以用它来获取匹配结果
-
-
re.match()方法
-
语法格式
re.match(pattern, string, flags=0) -
示例
result = re.match('this', s) print(result.group())
-
-
代表字符
字符 描述 . 任意单个字符(除了\n) [] 匹配中括号中的任意1个字符。并且特殊字符写在[]会被当成普通字符来匹配 [ .-.] 匹配中括号中范围内的任意1个字符,例如[a-z],[0-9] [^] 匹配[^字符]之外的任意一个字符 \d 匹配数字,等效[0-9] \D 匹配非数字字符,等效[^0-9] \s 匹配单个空白字符(空格、Tab键),等效[\t\n\r\f\v] \S 匹配空白字符之外的所有字符,等效[^\t\n\r\f\v] \w 匹配字母、数字、下划线,等效[a-zA-Z0-9_] \W 与\w相反,等效[^a-zA-Z0-9_] -
原始字符串符号“r”
“r”表示原始字符串,有了它,字符串里的特殊意义符号就会自动加转义符。
-
示例
s = "123\\abc" result = re.match(r"123\\abc", s) print(result)
-
-
代表数量
字符 描述 * 匹配前面的子表达式0次或多次(无限次) + 匹配前面的子表达式1次或多次 ? 匹配前面的子表达式0次或1次 {n} 匹配花括号前面字符n个字符 {n,} 匹配花括号前面字符至少n个字符 {n,m} 匹配花括号前面字符至少n个字符,最多m个字符 -
代表边界
字符 描述 ^ 匹配以什么开头 $ 匹配以什么结尾 \b 匹配单词边界 \B 匹配非单词边界 -
代表分组
字符 描述 | 匹配竖杠两边的任意一个正则表达式 (re) 匹配小括号中正则表达式。
使用\n反向引用,n是数字,从1开始编号,表示引用第n个分组匹配的内容。(?P<name>re) 分组别名,name是表示分组名称 (?P=name) 引用分组别名 -
贪婪和非贪婪匹配
-
贪婪模式:尽可能最多匹配
-
非贪婪模式:尽可能最少匹配,一般在量词(*、+)后面加个?问号就是非贪婪模式。
-
示例代码
s = "hello 666666" result = re.match("hello 6+", s) # 贪婪匹配 print(result) result = re.match("hello 6+?", s) # 非贪婪匹配 print(result)
-
-
其他方法
re.search(pattern, string, flags=0) 扫描字符串寻找匹配,如果符合返回一个匹配对象并终止匹配,否则返回None re.split(pattern, string, maxsplit=0, flags=0) 以匹配模式作为分隔符,切分字符串为列表 re.findall(pattern, string, flags=0) 以列表形式返回所有匹配的字符串 re.finditer(pattern, string, flags=0) 以迭代器形式返回所有匹配的字符串 re.sub(pattern, repl, string, count=0, flags=0) 字符串替换,repl替换匹配的字符串,repl可以是一个函数 -
标志位
字符 描述 re.I/re.IGNORECASE 忽略大小写 re.S/re.DOTAIL 匹配所有字符,包括换行符\n,如果没这个标志将匹配除了换行符
-
2. 案例
2.1 案例、正则表达式基本使用
#!/usr/bin/env python3
# _*_ coding: utf-8 _*_
# Author:shichao
# File: .py
# re.compile方法
import re
s = "this is test string"
pattern = re.compile('this') # 要匹配的内容
result = pattern.match(s) # 要匹配列表数据
print(result)
# re.match 方法
import re
a = "this is test string"
result_a = re.match("this", a) # this 是要匹配的内容,a 是要匹配的列表
print(result_a)
2.2 案例、代表字符
-
案例、代表字符
#!/usr/bin/env python3 # _*_ coding: utf-8 _*_ # Author:shichao # File: .py ''' | 字符 | 描述 | | ------ | ------------------------------------------------------------ | | . | 任意单个字符(除了\n) | | [] | 匹配中括号中的任意1个字符。并且特殊字符写在[]会被当成普通字符来匹配 | | [ .-.] | 匹配中括号中范围内的任意1个字符,例如[a-z],[0-9] | | [^] | 匹配\[^字符\]之外的任意一个字符 | | \d | 匹配数字,等效[0-9] | | \D | 匹配非数字字符,等效\[^0-9] | | \s | 匹配单个空白字符(空格、Tab键),等效[\t\n\r\f\v] | | \S | 匹配空白字符之外的所有字符,等效[^\t\n\r\f\v] | | \w | 匹配字母、数字、下划线,等效[a-zA-Z0-9_] | | \W | 与\w相反,等效[^a-zA-Z0-9_] | ''' import re # "." 匹配单个字符 a = 'hello world' a_1 = re.match(".",a) print(a_1) # [ ] 匹配中括号中任意1个字符 b = 'hello world' b_1 = re.match("[h]", b) print(b_1) # [.-.] 匹配中括号中任意1个字符 [a-z] 或者 [0-9] c = 'hello 98f' c_1 = re.match("hello 9[0-9]f",c) print(c_1) # [^] 排除中括号之外的意思,就是取反 d = 'hello' d_1 = re.match("h[^abcd]llo",d) print(d_1) # \d \小写的d,匹配纯数字,只能匹配一个数字 e = '15983241607' e_1 = re.match("^1\d",e) print(e_1) # \D 匹配除了数字,其他都匹配,包括空格、字符、大小写字母 f = 'fda ls' f_1 = re.match("fda\Dl\D",f) print(f_1) # \s 匹配 空格或tab键 h = 'he llo' h_1 = re.match("he\sllo", h) print(h_1) # \w 匹配字母、数字、下划线[a-zA-Z0-9] j = 'hs09lm1s' j_1 = re.match("hs09lm\ws",j) print(j_1)
2.3 案例、自动增加转义 "r"
-
使用 “r”自动加转义符
#!/usr/bin/env python3 # _*_ coding: utf-8 _*_ # Author:shichao # File: .py import re # 使用r功能自动增加转义 s = '123\\abc' s_1 = re.match(r"123\\abc",s) print(s_1)
2.4 案例、代表数量
-
案例、代表数量使用
#!/usr/bin/env python3 # _*_ coding: utf-8 _*_ # Author:shichao # File: .py ''' | 字符 | 描述 | | ----- | ------------------------------------------ | | * | 匹配前面的子表达式0次或多次(无限次) | | + | 匹配前面的子表达式1次或多次 | | ? | 匹配前面的子表达式0次或1次 | | {n} | 匹配花括号前面字符n个字符 | | {n,} | 匹配花括号前面字符至少n个字符 | | {n,m} | 匹配花括号前面字符至少n个字符,最多m个字符 | 代表数量,必须前面要跟一个代表字符,或其他的进行使用 ''' import re # * 匹配一次或多次,无限次 a = 'hello world' a_1 = re.match("hello w\D*",a) print(a_1) # + 匹配一次或多次 b = 'hello w09lsdf' b_1 = re.match("hello w\d+\D+",b) print(b_1) # ? 匹配0次或1次 c = 'fd134ds' c_1 = re.match('fd1?34ds',c) print(c_1) # {n} 匹配前面字符n个字符 d = 'hello world' d_1 = re.match("he\D{5}",d) print(d_1) # {n,m} 匹配前面字符 最少n个字符,最多m个字符 e = 'hello world' e_1 = re.match("he\D{3,8}",e) print(e_1) # 测试匹配手机号 f = '15908753521' f_1 = re.match("1\d{3,10}",f) print(f_1) # 匹配邮箱 h = 'Dh197@189.com' h_1 = re.match("^[A-Za-z0-9]\w*@[a-z0-9]*\.[a-z]+$",h) print(h_1)
2.5 案例、代表边界
-
案例、代表边界
#!/usr/bin/env python3 # _*_ coding: utf-8 _*_ # Author:shichao # File: .py ''' | 字符 | 描述 | | ---- | -------------- | | ^ | 匹配以什么开头 | | $ | 匹配以什么结尾 | | \b | 匹配单词边界 | | \B | 匹配非单词边界 | ''' import re # ^ 匹配以什么开头 a = 'hello world' a_1 = re.match("^h\w*\s\w*",a) # 以h开头 print(a_1) # $ 匹配以什么结尾 b = "hello world" b_1 = re.match("\w*\s\w*d$",b) # 以d结尾 print(b_1)
2.6 案例、代表分组
-
案例、代表分组
#!/usr/bin/env python3 # _*_ coding: utf-8 _*_ # Author:shichao # File: .py ''' | 字符 | 描述 | | ------------- | ------------------------------------------------------------ | | | | 匹配竖杠两边的任意一个正则表达式 | | (re) | 匹配小括号中正则表达式。<br/>使用\n反向引用,n是数字,从1开始编号,表示引用第n个分组匹配的内容。 | | (?P\<name>re) | 分组别名,name是表示分组名称 | | (?P=name) | 引用分组别名 | ''' import re # | 匹配分组两边的正则 # 匹配邮箱 h = 'Dh197@163.com' h_1 = re.match("^[A-Za-z0-9]\w*@[163|126|qq]+\.[a-z]+$",h) print(h_1)
2.7 案例、贪婪和非贪婪匹配
-
案例、贪婪和非贪婪匹配
#!/usr/bin/env python3 # _*_ coding: utf-8 _*_ # Author:shichao # File: .py import re s = "hello 666666" result = re.match("hello 6+", s) # 贪婪匹配 print(result) result = re.match("hello 6+?", s) # 非贪婪匹配 print(result)