CPU进行运算时,需要用到大量的指令与数据。CPU寄存器存储太小,不可能放得下这些指令与数据,因此需要有专门的存储单元来存放,称之为内存,CPU可以直接从内存中获取数据。
一、物理地址与虚拟地址
物理地址:存储器通常是以字节为单位存储信息,每个字节都对应一个唯一的存储器地址,称为物理地址。这个物理地址形式上也是一个数据,经过地址译码器后变成电信号,并由地址总线到对应的存储单元,最后将其存储内容转交给CPU进行运算。
直接使用物理地址进行管理时(实模式),不同程序之间的读写容易互相干扰,程序的读写可能会侵入操作系统本身,难以限制程序内存不断扩张。
如何将程序内存读取与物理地址解耦,计算机常用的办法就是在中间加一抽象层,即引入虚拟地址。
虚拟地址:CPU在保护模式下,程序运行在独立的虚拟地址空间中,段地址和偏移地址共同构成虚拟地址,用于内存访问。
由于各程序的虚拟地址空间是独立的,所以避免了相互干扰。虚拟地址作为空中楼阁,现代操作系统通过MMU(内存管理单元)将其映射到物理地址上。
二、内存管理单元
MMU即内存管理单元,是用硬件电路逻辑实现的一个地址转换器件,它负责接受虚拟地址和地址关系转换表,以及输出物理地址。
整体关系如下所示:
| 进程1:虚拟地址空间n | 物理地址空间1 | |
|---|---|---|
| 进程2:虚拟地址空间n | 物理地址空间2 | |
| 进程3:虚拟地址空间n | MMU映射 | 物理地址空间3 |
| ...... | ...... | |
| 进程n:虚拟地址空间n | 物理地址空间 |
映射过程需要通过虚拟地址转换成物理地址,MMU维护了一张地址关系转换表,即页表。页表并不直接存放虚拟地址与物理地址的直接对应关系,这样会耗费大量内存。
现代操作系统使用分页模型来管理内存,即将虚拟地址空间和物理地址空间都分成大小相同的块,也称为页;MMU以虚拟地址为索引去查页表返回物理页面地址。
页的大小通常设置为4KB,通过分级页表可以大大减少页面地址的存储空间,可以类比于书中的目录,页就是对应的某一页书,通过一级目录、二级目录、三级目录,找到对应的页码,MMU根据虚拟地址来识别各级目录,最后得到的是某个物理页的地址。
不同模式下的分页模型有差异,原因在与物理地址空间大小与虚拟地址长度有差异,体现在页表目录的级数不同,原理类似。
典型的三级页表如下:待上图
三、cache与一致性问题
局部性原理(时间与空间):指CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中。
CPU操作寄存器进行运算的速度远远高于访问内存的速度,因此,内存成为系统性能的瓶颈。
Cache就是用来缓解这个瓶颈的。Cache,高速缓冲存储器,存放一部分内存数据,CPU在访问内存时要先访问Cache,若Cache中有需要的数据就直接从Cache中取出,若没有则需要从内存中读取数据,并同时把这块数据放入Cache中。由于局部性原理,大部分情况下CPU都能从cache中找到数据,减少直接访问内存次数。
------
/ Regs \ - L0寄存器,CPU访问需要1个时钟周期
----------
/ L1 cache \ - 一级缓存,CPU访问需要4个时钟周期
--------------
/ L2 cache \ - 二级缓存,CPU访问需要10个时钟周期
------------------
/ L3 cache \ - 三级缓存,CPU访问需要50个时钟周期
----------------------
/ Main memory \ - 内存,CPU访问需要约200个时钟周期
--------------------------
/ Local disks \ - 本地磁盘,CPU访问需要约1千万个时钟周期
------------------------------
/ Network storage \ - 网络存储
----------------------------------
Cache主要由高速的静态储存器、地址转换模块和Cache行替换模块组成。工作流程如下:
(1)CPU发出的地址由Cache的地址转换模块分成3段:组号,行号,行内偏移。
(2)Cache会根据组号、行号查找高速静态储存器中对应的行。如果找到即命中,用行内偏移读取并返回数据给CPU,否则就分配一个新行并访问内存,把内存中对应的数据加载到Cache行并返回给CPU。写入操作则比较直接,分为回写和直通写,回写是写入对应的Cache行就结束了,直通写则是在写入Cache行的同时写入内存。
(3)如果没有新行了,就要进入行替换逻辑,即找出一个Cache行写回内存,腾出空间,替换行有相关的算法,替换算法是为了让替换的代价最小化。
为进一步提升性能,将cache继续划分L1 cache(4-64KB,集成在处理器内部)、L2 cache(128KB-4MB,集成在处理器内部)、L3 cache(10MB-64MB,所有核心共享)。
双CPU的cache模型如下所示:
Cache的一致性问题,cache数据与内存数据不一致,主要包括这三个方面:
1.单个CPU的指令Cache和数据Cache的一致性;
2.多个CPU的L2 Cache的一致性;
3.3级Cache与设备内存,如DMA、网卡帧储存,显存之间的一致性。
解决办法:MESI协议
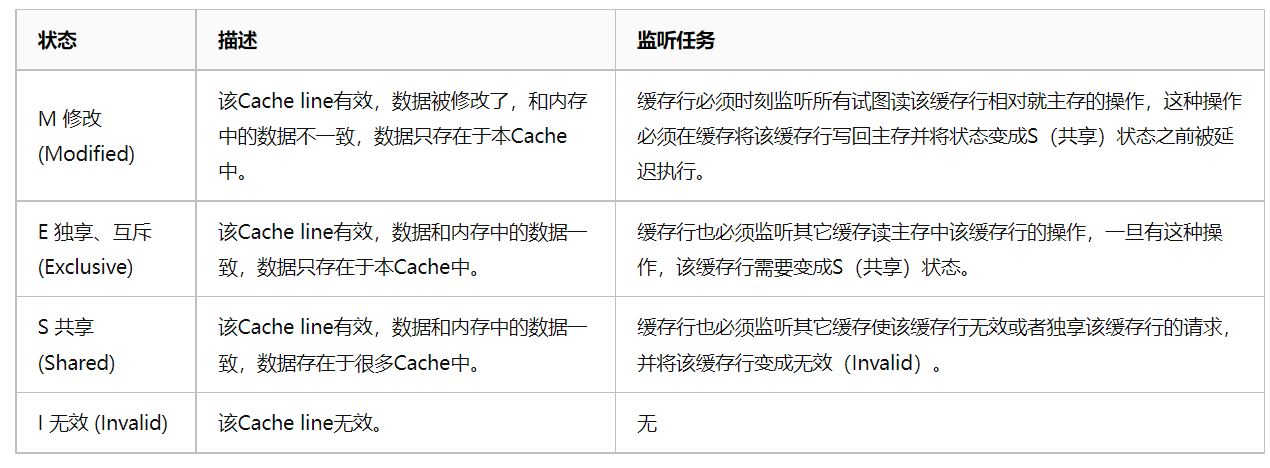
MESI代表cache line的四种状态,可以如下理解:
当第一个核读取A数据,此时状态为E独占,数据是干净的;
另一个核也读取了A数据,此时状态为S共享数据还是干净的;
接着其中一个核修改了数据A,此时会向其他核广播数据已被修改,让其他核的数据状态变为I失效,而本核的数据还没回写内存,状态则变为M已修改;
等待后续刷新缓存后,数据变回E独占,其他核由于数据已失效,读数据A时需要重新从内存读到高速缓存,此时数据又共享了。
以上的各种状态监控与更新操作,由Cache硬件来执行,完成cache line的状态切换,从而安全地控制各Cache间、各Cache与内存之间的数据一致性。
(MESI优化后,会导致性能变慢,使用指令重排和内存屏障的处理,先埋坑)
四、如何提高cache命中率
提高cache命中率,就可优化程序的性能。
使用工具perf record -e cache-misses ./test,可以统计cache命中率
(1)绑核:进程在不同核之间切换时,cache命中率较低,需要重复缓存到不同的cache中;
// linux下的绑核接口
#define _GNU_SOURCE
#include <sched.h>
// function return 0 for success and -1 for failure
int sched_setaffinity(pid_t pid, size_t cpusetsize,
const cpu_set_t *mask);
int sched_getaffinity(pid_t pid, size_t cpusetsize,
cpu_set_t *mask);
(2)pre cpu变量
参考per-CPU变量
per-CPU变量,系统中的每个处理器都分配了该变量的副本,当处理器操作属于它的变量副本时,不需要考虑与其他处理器的竞争的问题,同时该副本还可以充分利用处理器本地的硬件缓冲cache来提供访问速度。
(3)设计数据的存储结构
如:共享变量结构定义为Cache line对齐
Cache取数据是按照cache line为单位(目前大部分系统为64Byte)。若数据跨越两个cache line,就意味着两次load或者两次store。如果数据结构是cache line对齐的,就有可能减少一次读写,以空间换区时间。
如:数据的存储顺序与访问顺序,保持密切关联
数组按照低维度索引遍历可以减少cache miss;
如:只读数据与频繁更新数据,分开存储,使用const关键字
如:减少使用全局变量,增强数据访问的局部性
如:精简循环体内的代码,减少指令cache的更新
(4)提高分支优先级,辅助编译器优化
// likely与unlikely宏:
#define likely(x) __builtin_expect(!!(x), 1) // 表示x为真的可能性较大
#define unlikely(x) __builtin_expect(!!(x), 0) // 表示x为假的可能性较大
// __builtin_expect函数
long __builtin_expect(long exp, long c);
// 实例:表示(a == 1)成立的概率较大,可以提前将指令A缓存
// 写法一
if (__builtin_expect((a == 1), 1) {
// do sth. A
} else {
// do sth. B
}
// 写法二
if (likely(a == 1)) {
// do sth. A
} else {
// do sth. B
}
五、参考与感谢
(1)操作系统实战45讲
(2)CPU缓存一致性协议MESI
(3)MESI 一致性协议引发的一些思考
(4)神仙网站:MESI原理动图
(5)如何提升代码的cache命中率
(6)增加Cache命中率加快程序运行速度






![[Redis]Redis概述](https://img2023.cnblogs.com/blog/1173617/202303/1173617-20230331015630293-511848323.png)