迁移学习(DaC)《Divide and Contrast: Source-free Domain Adaptation via Adaptive Contrastive Learning》
论文信息
论文标题:Divide and Contrast: Source-free Domain Adaptation via Adaptive Contrastive Learning
论文作者:Ziyi Zhang, Weikai Chen, Hui Cheng, Z. Li, Siyuan Li, Liang Lin, Guanbin Li
论文来源:NeurIPS 2022
论文地址:download
论文代码:download
视屏讲解:click
1 简介
提出问题:从全局角度的域适应带来的噪声大,从局部角度的域适应没有考虑全局信息;
解决问题:
-
- 一种新的 SFUDA 对比范式,通过对目标数据分割,充分利用其全局和局部结构;
- 统一的自适应对比学习框架,实现类源样本的类自适应和目标特定数据的局部一致性;
- 基于内存库的 MMD 损失,以减少批量训练中的批偏差,并改进了具有非负指数形式的 MMD 损失;
2 方法
2.1 整体框架及算法
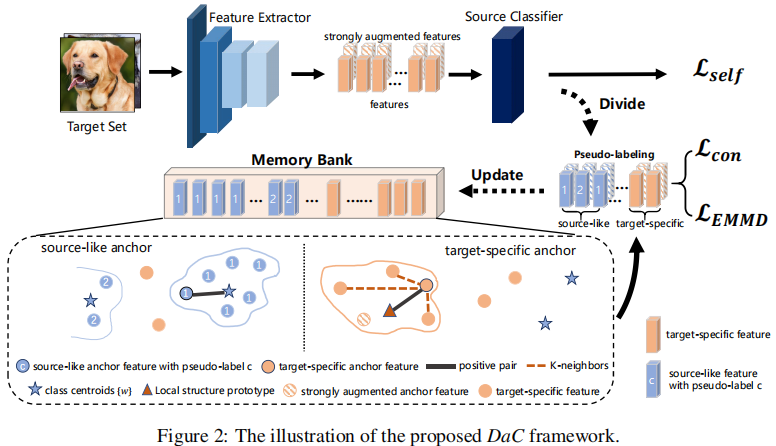
整体框架:
算法:

2.2 数据分割和自训练
2.2.1 伪标签
定义 $p_{i}=\delta\left(g_{s}\left(f_{i}\right)\right)$ 代表源分类器的预测输出,每个类 $k$ 的初始质心通过以下方式获得:$\mathbf{c}_{k}=\frac{\sum_{i}^{n_{t}} f_{i} p_{i}[k]}{\sum_{i}^{n_{t}} p_{i}[k]}$。样本被标记为与其最近的初始质心相同:
$\tilde{\mathcal{Y}}=\left\{\tilde{y}_{i} \mid \tilde{y}_{i}=\underset{k}{\arg \max } \cos \left(\phi\left(x_{i}\right), \mathbf{c}_{k}\right), x_{i} \in \mathcal{D}_{T}\right\} \quad\quad(2)$
修正后的质心:$\mathbf{c}_{k}=\frac{\sum_{i}^{n_{t}} \mathbb{1}\left(\tilde{y}_{i}=k\right) \mathbf{f}_{i}}{\sum_{i}^{n_{t}} \mathbb{1}\left(\tilde{y}_{i}=k\right)}$
随后,伪标签通过修正后的质心,并使用 $\text{Eq.2}$ 设置。
2.2.2 一致性正则化的自我训练
在训练迭代期间,将每个样本 $x_i$ 转移到两个视图中:$\mathcal{A}_{w}\left(x_{i}\right)$、$\mathcal{A}_{s}\left(x_{i}\right)$。 两个视图的网络预测分别表示为 $p_{i}^{w}$ 和 $p_{i}^{s}$。 用 $\hat{y}_{i}=\operatorname{onehot}\left(\tilde{y}_{i}\right)$ 表示伪标签的单热编码。 由于两个增强视图的语义内容相同,鼓励通过以下损失在两种类型输出之间进行一致的预测:
$\mathcal{L}_{\text {self }}=-\mathbb{E}_{x_{i} \in \mathcal{B}_{T}}\left[\sum_{c=1}^{C} \hat{y}_{i}^{c} \log \left(p_{i}^{w}[c]\right)+\hat{y}_{i}^{c} \log \left(p_{i}^{s}[c]\right)\right]+\sum_{c=1}^{C} \operatorname{KL}\left(\bar{p}_{c} \| \frac{1}{C}\right)+\omega H\left(p_{i}^{w}\right),$
其中:
-
- $\bar{p}_{c}=\mathbb{E}_{\mathcal{B}_{T}}\left[p_{i}^{w}[c]\right]$ 通过均匀分布进行正则化以鼓励输出多样性;
- $H\left(p_{i}^{w}\right)= -\mathbb{E}_{\mathcal{B}_{T}}\left[\sum_{c} p_{i}^{w}[c] \log \left(p_{i}^{w}[c]\right)\right] $ 是香农熵[36],用于鼓励自信的输出和加速收敛,$\omega$ 是相应的参数;
2.2.3 数据集划分
将 $\mathcal{D}_{T}$ 中的所有样本划分为 $\text{source-like}$ 和 $\text{target-specific outliers}$。
$\text{source-like}$ 集合:
$\tilde{\mathcal{D}}_{S}^{k}=\left\{x_{i} \mid \max _{c}\left(p_{i}^{w}[c]\right) \geq \tau_{c}, \underset{c}{\arg \max }\left(p_{i}^{w}[c]\right)=k, x_{i} \in \mathcal{D}_{T}\right\}$
$\tilde{\mathcal{D}}_{S}=\cup_{k=1}^{C} \tilde{\mathcal{D}}_{S}^{k} $
$\text{target-specific }$ 集合:
$\tilde{\mathcal{D}}_{O}=\mathcal{D}_{T} \backslash \tilde{\mathcal{D}}_{S}$
$\tilde{\mathcal{D}}_{O}^{k}=\left\{x_{i} \mid x_{i} \in \tilde{\mathcal{D}}_{O}, \tilde{y}_{i}=k, \tilde{y}_{i} \in \tilde{\mathcal{Y}}\right\} $
2.3 自适应对比学习
与 [41, 35] 类似,使用 $\text{memory bank}$ 来存储所有目标样本特征 $\mathcal{F}=\left\{z_{i}\right\}_{i=1}^{n_{t}}$。 $\text{memory bank}$ 动态生成 $C$ 类 $\text{source-like}$ 质心,并且 $\text{target-specific}$ 目标特征 $\left\{\boldsymbol{v}_{j}\right\}_{j=1}^{n_{o}}$,其中 $n_{o}$ 是当前 $\text{target-specific}$ 样本的数量。
对于训练期间,锚特征 $f_{i}=\phi\left(\mathcal{A}_{w}\left(x_{i}\right)\right), x_{i} \in \tilde{\mathcal{D}}_{S} \cup \tilde{\mathcal{D}}_{O}$,本文使用内积测量相似度进行原型对比损失:
$\mathcal{L}_{\text {con }}=-\mathbb{E}_{x_{i} \in \mathcal{B}_{T}} \log \frac{\exp \left(f_{i} \cdot \boldsymbol{k}^{+} / \tau\right)}{\exp \left(f_{i} \cdot k^{+} / \tau\right)+\sum_{j=1}^{C+n_{o}-1} \exp \left(f_{i} \cdot k_{j}^{-} / \tau\right)}$
2.4 原型生成
对于 $\text{source-like anchor}$,正原型指定为类质心 $k^{+}=w_{k}$,其余 $C − 1$ 个类质心和 $n_{o}$ 个无特定目标特征用于形成负对。
对于 $\text{target specific anchor}$,引入局部结构生成正原型 $k^{+}=\frac{1}{K+1}\left(f_{i}^{s}+\sum_{k=1}^{K} z_{k}\right)$,其余 $n_{o}-1$ 个 $\text{target-specific}$ 特征 $\left\{\boldsymbol{v}_{j}\right\}_{j \neq i}$ 和 $C$ 类质心来形成负对。
2.5 Memory Bank
$\text{Memory Bank}$ 中的特征是使用同一特征提取器得到的特征 $\phi_{s}: \mathcal{F}=\left\{z_{i} \mid z_{i}=\phi_{s}\left(x_{i}\right), x_{i} \in \mathcal{D}_{T}\right\} $,保存了源域信息。
$\text{Memory Bank}$ 中特征动量更新:$\boldsymbol{z}_{i}=m \boldsymbol{z}_{i}+(1-m) \boldsymbol{f}_{i}$;
$\text{Memory Bank}$ 为对比学习提供 $\text{source-like centroids}$ 和 $\text{target-specific features}$。$\text{target-specific features}$ 可以直接在 $\text{Memory Bank}$ 中访问:$\left\{v_{i} \mid v_{i}=z_{i}, x_{i} \in \tilde{\mathcal{D}}_{O}\right\}$。在初始化 $\text{source-like centroids}$ 之前初始化 $\text{source-like set}$。为在早期训练阶段保证 $\text{source-like set}$ 中有足够样本,本文在每个类中抽取具有前 5% 预测的样本来初始化 $\text{source-like set}$:
$\tilde{\mathcal{D}}_{S}^{c}=\underset{|\mathcal{X}|=N, \hat{\mathcal{X}} \subseteq \mathcal{D}_{t}}{\arg \max } \sum_{x_{i} \in \mathcal{X}} p_{i}^{w}[c]$
$\text{source-like set}$ 的第 $c$ 个 $\text{class centroids}$ 为:
$\boldsymbol{w}_{c}=\frac{1}{\left|\tilde{\mathcal{D}}_{S}^{c}\right|} \sum_{x_{i} \in \mathcal{D}_{S}^{c}} \boldsymbol{z}_{i}$
2.6 分布对齐
基于 $\text{mini-batch}$ 的线性 MMD:
$d_{M M D}(\mathcal{S}, \mathcal{T})=\frac{1}{m} \sum_{i=1}^{m} s_{i}\left(\frac{1}{m} \sum_{i^{\prime}=1}^{m} s_{i^{\prime}}-\frac{1}{n} \sum_{j^{\prime}=1}^{n} t_{j^{\prime}}\right)+\frac{1}{n} \sum_{i=1}^{n} t_{i}\left(\frac{1}{n} \sum_{j^{\prime}=1}^{n} t_{j^{\prime}}-\frac{1}{m} \sum_{i^{\prime}=1}^{m} s_{i^{\prime}}\right)$
朴素版本的 MMD 不适用于本文的设置,因为小批量样本对整个分布具有估计偏差,尤其是当 $m$ 或 $n$ 较小时。
为此,本文使用 $\text{Memory Bank}$ 中的特征来估计整个分布并减少批次偏差。具体来说,对于 $\mathcal{S}=\tilde{\mathcal{D}}_{S}^{c}$, $\mathcal{T}=\tilde{\mathcal{D}}_{O}^{c}$,我们将 $\frac{1}{m} \sum_{i^{\prime}=1}^{m} s_{i^{\prime}}$ 替换为 $\mathbb{E}_{\tilde{\mathcal{D}}_{S}^{c}}[z]=w_{c}$,$\frac{1}{n} \sum_{j^{\prime}=1}^{n} t_{j^{\prime}} $ 替换为 $\mathbb{E}_{\tilde{\mathcal{D}}_{O}^{c}}[z] $,并重写 $\text{Eq.8}$ 作为我们基于线性记忆体的 MMD:
$\mathcal{L}_{L M M D}=\mathbb{E}_{x_{i} \in \mathcal{B}_{T}} f_{i}\left(q_{i}^{-}-q_{i}^{+}\right) \quad\quad\quad(9)$
其中 $q_{i}^{-}$ 是同一域中记忆库中的相关原型。 例如,如果 $f_{i}$ 来自 $\text{source-like set}$,则 $\boldsymbol{q}_{i}^{-}=\boldsymbol{w}_{c}$, $\boldsymbol{q}_{i}^{+}=\mathbb{E}_{\tilde{\mathcal{D}}_{O}^{c}}[\boldsymbol{z}]$。 为了避免 $\text{Eq.9}$ 中的负项。将其改进为非负形式。 通过简单地裁剪 $\max \left\{0, f q^{-}-f q^{+}\right\}$,有:
$\max \left\{0, f q^{-}-f q^{+}\right\}=\max \left\{f q^{+}, f q^{-}\right\}-f q^{+} \leq \log \left(\exp \left(f q^{+}\right)+\exp \left(f q^{-}\right)\right)-f q^{+}$
上式最后一项可以写成指数 MMD 损失:
$\mathcal{L}_{E M M D}=-\mathbb{E}_{x_{i} \in \mathcal{B}_{T}} \log \frac{\exp \left(f_{i} \boldsymbol{q}_{i}^{+} / \tau\right)}{\exp \left(f_{i} \boldsymbol{q}_{i}^{+} / \tau\right)+\exp \left(f_{i} \boldsymbol{q}_{i}^{-} / \tau\right)}$
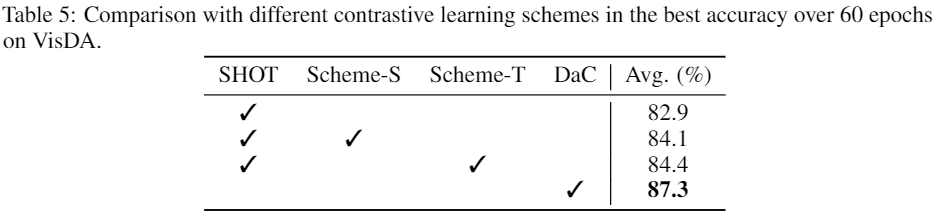
3 实验