一个刚上线的IT系统,往往负载压力不大,所以不会存在什么性能问题。这时,人们大多只关心系统的功能性和用户体验。但是,随着时间推移,用户量和数据量都比刚上线的时候要多很多,高并发和大数据场景下,系统遇到性能瓶颈,持续不能改善最终导致系统崩溃。这对于做C端的开发人员应该更加深有体会。
系统经常响应慢,甚至宕机,这对用户造成很差的用户体验,更有严重的,会导致大批用户流失、业务停摆等,造成不可挽回的损失。因此,持续运营的系统,是非常有必要进行性能优化的工作。对于性能优化,已经有很多可行且成熟的技术方案,下面就聊聊,旨在大概了解,不展开详说。
性能监控
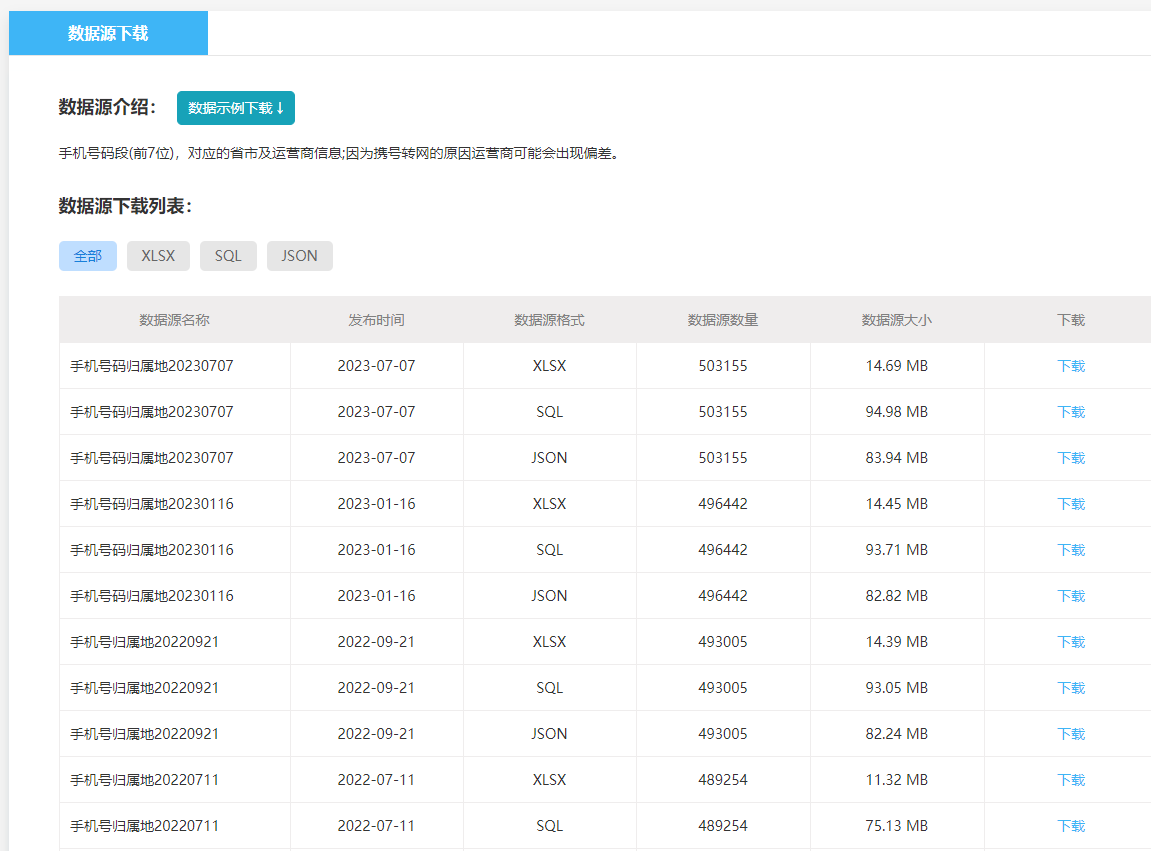
具体问题具体分析,解决性能问题总得要知道系统哪里遇到性能瓶颈。往大的来说,性能问题无非就是服务器的CPU、内存、数据库、IO、网络等出了问题。往小的来说,就是程序的某个方法或者某条SQL语句执行比较慢。系统的技术栈不一样,可用的性能监控工具也不一样。例如Linux系统就有top、sar、nmon等命令行工具可以监控服务器的CPU和内存的使用情况。JDK也提供了不少命令行工具,例如jstat、jmap、jhat、jstack等可以监控JVM(Java虚拟机)的内存情况。JDK可视化分析工具Visual VM,甚至可以进行方法级的程序运行性能分析,找到被调用最多、运行时间最长的方法。SQL Server可以用SQL Server Profiler进行慢查询语句分析,而MySQL就用mysqldumpslow。
除了使用监控工具进行性能监控,我们还可以通过在程序代码上加上一些日志,记录一些代码段的运行时间,从而判断出性能瓶颈的位置。
负载均衡
高并发场景下,比较典型的有电商的秒杀活动,同一时刻内,巨量的HTTP包要发送给服务器端处理。由于服务器资源有限,其同时处理请求的能力自然也有限。当高并发出现时,服务器的处理和响应速度会大幅降低。
为了应对这种场景,可以把用户请求分发到多台应用服务器上,利用更多的服务器资源分担高并发下的负载压力,这就是负载均衡。
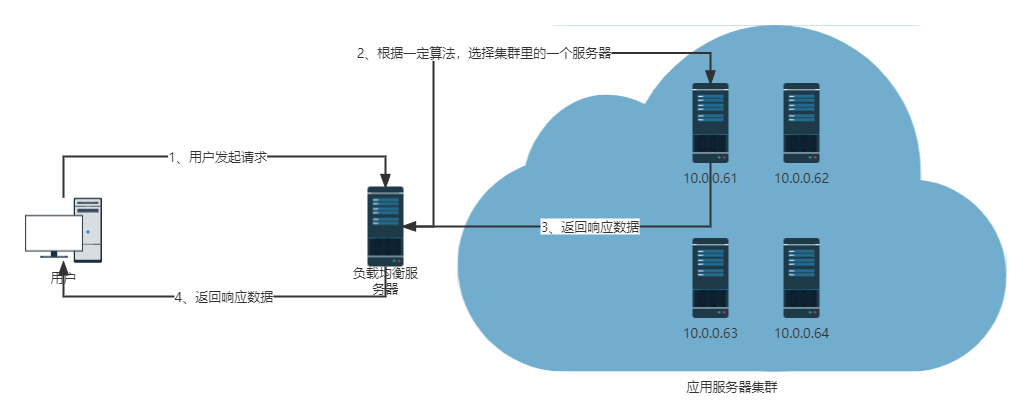
当然,实际的网络结构肯定比上图的要复杂的多。负载均衡一般分三种,分别是应用层负载均衡、 IP 层负载均衡(网络层负载均衡)、链路层负载均衡。应用层负载均衡通常用在规模比较小的集群上,而对于大规模的应用服务器集群,则使用IP层负载均衡或者链路层负载均衡。目前大型互联网应用大多使用链路层负载均衡。
分布式缓存
缓存目的就是减少应用程序请求数据库,从而降低数据库的压力。缓存一般存储那些很少变化而又经常会访问到的数据,例如每个系统的基础数据。而分布式缓存是应用于分布式架构的,就是单独的缓存服务器,多个应用服务器都可以访问缓存服务器里的数据。分布式缓存可以分为CDN、反向代理、分布式对象缓存。
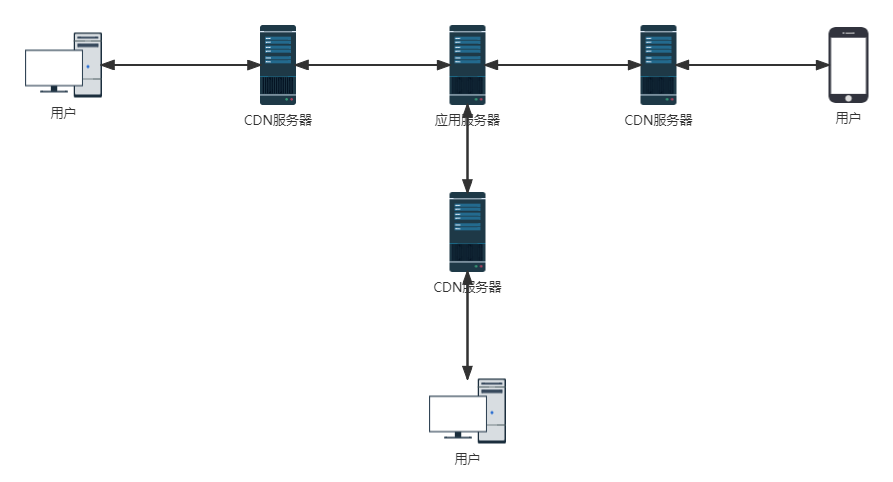
CDN
CDN(Content Delivery Network),内容分发网络,本质就是在网络运营商的机房里部署缓存服务器。这样,用户就可以从离自己近的机房获取到数据,从而提高了响应速度。因为距离用户非常近,又被称作网络连接的第一跳。CDN一般缓存的是静态资源,如图片,文件,CSS,JS脚本,静态网页等,这些文件访问频率很高,将其缓存在CDN可极大改善网页的打开速度。
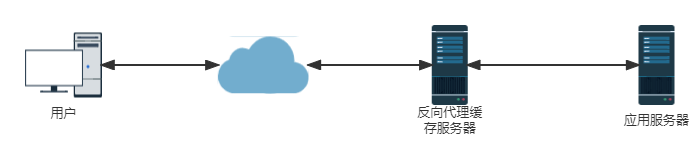
反向代理
我们有时候需要通过代理上网,这个代理是代理我们的客户端上网设备(例如,浏览器)。反向代理则是代理服务器,所有的网络请求都需要通过反向代理才能到达应用程序服务器。如果在反向代理服务器加一个缓存,将数据返回给用户,而不是通过应用服务器,这就是反向代理缓存。反向代理一般也是缓存静态资源。反向代理服务器同时也具有保护应用服务器安全的作用,来自互联网的访问请求必须经过代理服务器,相当于在应用服务器前面建立了一个屏障。
分布式对象缓存
CDN 和反向代理缓存对应用程序服务器是透明的,通常被当做系统前端的一部分。而应用程序服务器如果要使用缓存,就需要分布式对象缓存。分布式对象缓存,比较熟悉的就是Redis、Memcached。这些中间件提供给应用程序SDK,应用程序通过SDK的API操作缓存。
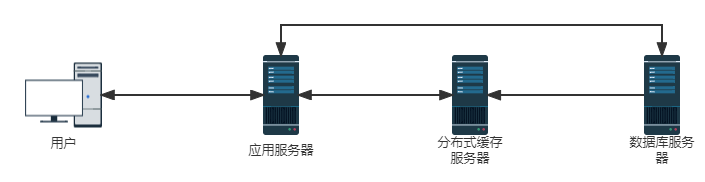
使用缓存架构可以快速响应用户请求,但是缓存只能改善系统的读操作性能,对于写操作,缓存是无能为力的。我们不能把用户提交的数据直接写入缓存中,因为缓存通常被认为是一种不可靠的存储。
消息队列
消息队列就是将用户请求进行异步处理。通俗来说,就是多个用户的请求排着队一个个处理。这样,有效防止了高并发给服务器带来的压力。
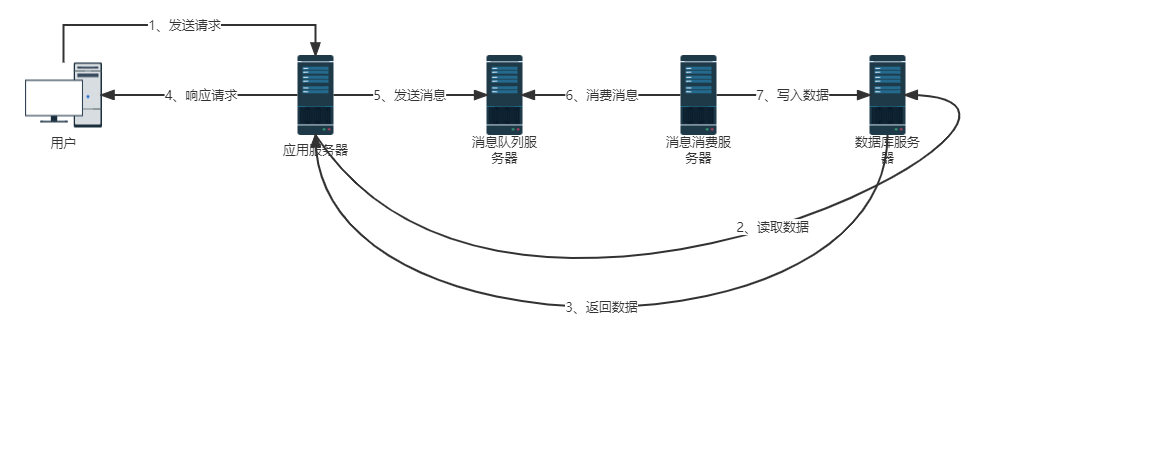
消息队列更多的是用于优化对数据库的写入操作。消息队列写数据库的时候,可以根据数据库的负载能力控制写入的速度,高并发的时候降低写入速度,甚至停止写入,等到用户请求低谷的时候,又放开写入速度的限制。这种方式叫做“削峰填谷”,它可以使系统运行在一个性能最优的负载压力范围内。
数据库优化
前面说的缓存其实就是把数据存到内存,但是,内存的资源毕竟非常有限,不可能把所有数据都存到缓存。因此,该连接数据库还是得连接数据库。数据库毕竟是属于硬盘的东西,它的处理速度肯定没有内存快,同时又对并发压力比较敏感,大量操作请求同时提交到数据库,可能会导致数据库负载压力太大而崩溃。
优化数据库一般有三种手段,分别是SQL优化、分库分表、读写分离。
SQL优化
SQL优化最常见的就是慢查询语句优化。查询优化有一些技巧,例如避免使用select * 、union all关键字代替union关键字、小表驱动大表、值只有数字的字段要设为数字型类型、where语句字段加索引、where语句的索引字段不要用函数等等等。
加索引是比较常见的优化方法,但有时候加了索引也慢,这有可能是索引失效了,可以利用数据库自带的工具查看执行计划,看是否索引失效。
分库分表
分库分表的主要目的就是为了解决由于数据量过大而导致数据库性能降低的问题。将原来独立的数据库拆分为若干数据库,将数据大表拆分成若干数据表,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。分库分表又分为垂直分库、水平分库、垂直分表、水平分表。值得一提的是,分库会带来分布式事务的问题。
-
垂直分库,就是把原来单库的表分到多个数据库。一般会按业务拆分,每个大的业务对应一个数据库,不同的数据库可以部署到不同的服务器。这样,某个业务模块的数据库性能问题就不会直接影响到其他业务模块。例如电商系统的用户模块和订单模块可以拆分为用户库、订单库两个数据库。垂直分库的目的是方便按业务分级管理、维护、监控和扩展等。
-
水平分库,就是把原来单表的行数据分到多个数据库,这些数据库的表数据结构是一样的。例如,把商品id为单数的商品数据分到数据库A,把商品id为偶数的商品数据分到数据库B。水平分库的好处是解决了单库大数据造成的性能问题。
-
垂直分表,就是把原来单表的字段分到多个表。例如,原来商品表有id、商品名称、单价、描述等字段,经过垂直分表后,分成了两个表,id、商品名称、单价字段分到商品表A,id、描述字段分到商品表B。需要垂直分表的原因一般是原表中有大字段(例如商品表的“描述”字段就是大字段,里面可以包含很多字符),大字段IO效率低,需要把大字段单独分到一个表中,这样页面的商品列表因为不需要显示“描述”字段而得到优化。
-
水平分表,就是把原来单表的行数据分到多个表,这些表数据结构是一样的。例如,把商品id为单数的商品数据分到商品表A,把商品id为偶数的商品数据分到商品表B。水平分表的好处是解决了单表大数据造成的性能问题。
读写分离
数据库读写分离就是做数据库集群,一般是一主多从,一个主库(master)负责写入数据,多个从库(slave)负责读取数据。当然也有多master的方案。
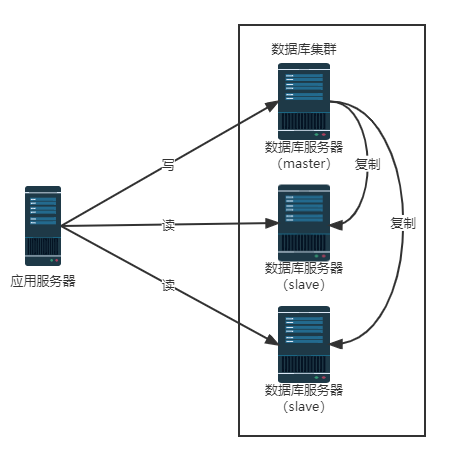
大多数互联网业务,往往读多写少,这时候,数据库的读操作会首先成为数据库的性能瓶颈。这时,如果我们希望能够线性的提升数据库的读性能,消除读写锁冲突从而提升数据库的写性能,那么就可以使用读写分离架构。
代码优化
有些性能问题是可以通过修改代码解决的。例如,避免循环次数过多、避免在循环内读写数据库、避免在循环内调用API、导出的数据量做限制、尽量批量操作数据库、同步操作换异步操作、使用缓存、采用定时任务等等等。
JVM调优
如果是Java程序,可以考虑JVM配置优化。一般可以通过jstat、jmap、jhat、jstack等命令监控到JVM内存的使用情况以及GC的情况。如果发现GC过于频繁(特别是Full GC),就可以通过修改JVM参数,加大JVM堆内存,或者修改堆内存分区比例,达到优化的效果。当然,其他编程语言应该也有类似的优化办法。
服务降级
服务降级就好比大环境不好,钱不好赚,需要把烧钱和不赚钱的业务裁掉,留下核心业务过冬。当系统负载过高或者出现故障时,需要启动限流,写入限制,甚至将一些非核心业务(负载过高)或者故障业务进行移除,以此释放服务器资源以保证核心业务的正常运行。
硬件扩容或升级
有条件(不缺钱)的情况,是可以考虑买买买的(简单粗暴),内存扩容、硬盘空间扩容、加服务器、上固态硬盘等等等。
结语
IT系统性能优化是个大课题,是一个庞大的知识体系,包含但不限于上面提到的知识点,如果要展开详说,估计要讲到天荒地老。有兴趣的,可以一个个的去深入研究。