[NOIP2011 普及组] 表达式的值
题目描述
对于1 位二进制变量定义两种运算:
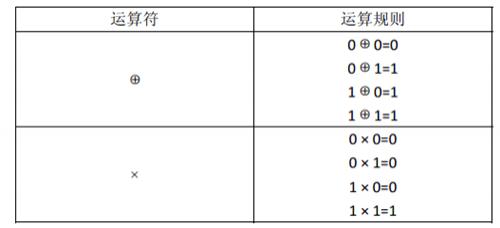
运算的优先级是:
-
先计算括号内的,再计算括号外的。
-
“× ”运算优先于“⊕”运算,即计算表达式时,先计算× 运算,再计算⊕运算。例如:计算表达式A⊕B × C时,先计算 B × C,其结果再与 A 做⊕运算。
现给定一个未完成的表达式,例如_+(_*_),请你在横线处填入数字$0 $或者\(1\) ,请问有多少种填法可以使得表达式的值为$0 $。
输入格式
共 2 行。
第1 行为一个整数 \(L\),表示给定的表达式中除去横线外的运算符和括号的个数。
第2 行为一个字符串包含 \(L\) 个字符,其中只包含’(’、’)’、’+’、’*’这\(4\) 种字符,其中’(’、’)’是左右括号,’+’、’*’分别表示前面定义的运算符“⊕”和“×”。这行字符按顺序给出了给定表达式中除去变量外的运算符和括号。
输出格式
共1 行。包含一个整数,即所有的方案数。注意:这个数可能会很大,请输出方案数对$10007 $取模后的结果。
样例 #1
样例输入 #1
4
+(*)
样例输出 #1
3
提示
【输入输出样例说明】
给定的表达式包括横线字符之后为:_+(_*_)
在横线位置填入(0 、0 、0) 、(0 、1 、0) 、(0 、0 、1) 时,表达式的值均为0 ,所以共有3种填法。
【数据范围】
对于 \(20\%\) 的数据有 \(0 \le L \le 10\)。
对于 \(50\%\) 的数据有 \(0 \le L \le 1,000\)。
对于 \(70\%\) 的数据有 \(0 \le L \le 10,000\) 。
对于 \(100\%\)的数据有 \(0 \le L \le 100,000\)。
对于\(50\%\) 的数据输入表达式中不含括号。
浅浅分析一波
首先一看数据范围\(0 \le L \le 100000\),回溯的梦想破灭了fuck !
怎么做?
-
首先,他给的是一个不完整的序列,第一个思路就是把他补齐,例如样例
-
\(+(*)=?+(?*?)\)
-
然后?
-
如果我们要算,那么首先就是确定运算优先级,怎么确定?
-
当然是转成后缀表达式,例如样例
-
\(?+(?*?)=??*?+\)
-
然后?
-
由于他问的是方案数,还要\(mod\)一个数,很容易想到动态规划
-
想状态?
-
很容易想到对于一个操作符,他的方案数由前两个状态得来
-
什么意思?
-
例如样例\(??*?+\),看到第一个乘号,他的方案数就是前两个\(?\)得来的(问号为1)
-
于是,就变成了\(??+\),第一个\(?\)是\(??*\)变成的
-
于是,加法就由前两个\(?\)得来的,于是可得下面代码
#include<bits/stdc++.h>
using namespace std;
const int MAXN=1e5+7,mod=1e4+7;
int f[MAXN][2],n,m,len;
char s[MAXN],ss[MAXN];
//f[i][0]为这个位置为0的方案书
//f[i][1]为这个位置为1的方案
//第一步,确定运算顺序
//第二步,dp
//if(s[i-1]=='+') dp[i][0]=dp[i-1][0]
//dp[i][1]=dp[i-1][0]+dp[i-1][1]*2
//if(s[i-1]=='*') dp[i][0]=dp[i-1][0]*2+dp[i-1][1]
//dp[i][1]=dp[i-1][1]
void get_str(int l,int r){
for(int i=l;i<=r;i++) if(ss[i]=='*') s[++len]=ss[i],ss[i]=' ';
for(int i=l;i<=r;i++) if(ss[i]=='+') s[++len]=ss[i],ss[i]=' ';
}
void init(){
stack<int> t;
ss[0]='(',ss[m+1]=')';
for(int i=0;i<=m+1;i++){
if(ss[i]==')'){
get_str(t.top()+1,i-1);
t.pop();
}
else if(ss[i]=='(') t.push(i);
}
}
int main(){
scanf("%d%s",&n,ss+1);
m=strlen(ss+1);
init();
f[1][1]=1,f[1][0]=1;
for(int i=2;i<=len+1;i++) {
if(s[i-1]=='*') f[i][0]=(f[i-1][0]*2+f[i-1][1])%mod,f[i][1]=f[i-1][1]%mod;
if(s[i-1]=='+') f[i][0]=f[i-1][0]%mod,f[i][1]=(f[i-1][0]+f[i-1][1]*2)%mod;
}
cout<<f[len+1][0];
return 0;
}
-
\(20\)分,为什么?
-
我们来看一个样例\((+)*(+)\),后缀表达式为\(??+??+*\)
-
我们来看最后一个乘号,根据是上面代码,\(*\)由\(?,+\)转移过来,真的是这样吗?
-
很容易想到,肯定不是这样的,就说明这个\(dp\)有问题
-
咋办?
-
很容易想到用一个栈,把求出的状态推进去,于是就有了满分代码
\(Code\)
#include<bits/stdc++.h>
using namespace std;
struct node{int l,y;};
const int MAXN=1e6+7,mod=1e4+7;
char a[MAXN],S[MAXN],s[MAXN];
int n,m,len;
stack<node> ans;
void print(){
for(int i=1;i<=len;i++) cout<<s[i];
cout<<endl;
}
int get_y(char s){
if(s=='(') return 0;
if(s=='+') return 1;
if(s=='*') return 2;
}
void change(){
stack<char> t;
for(int i=1;i<=m;i++){
if(S[i]=='_'){
s[++len]=S[i];
}else if(t.empty()){
t.push(S[i]);
}else if(S[i]=='('){
t.push(S[i]);
}else if(S[i]==')'){
while(!t.empty()&&t.top()!='(') s[++len]=t.top(),t.pop();
t.pop();
}else if(get_y(t.top())>=get_y(S[i])){
while(!t.empty()&&get_y(t.top())>=get_y(S[i])){s[++len]=t.top();t.pop();}
t.push(S[i]);
}else{
t.push(S[i]);
}
}
while(!t.empty())s[++len]=t.top(),t.pop();
}
int main(){
scanf("%d%s",&n,a+1);
n=strlen(a+1);
for(int i=1;i<=n;i++){
if(a[i-1]==')') S[++m]=a[i];
else if(a[i]!='('&&a[i]!=')')S[++m]='_',S[++m]=a[i];
else if(a[i]=='(') S[++m]=a[i];
else S[++m]='_',S[++m]=a[i];
}
if(a[n]!=')') S[++m]='_';
change();
// print();
for(int i=1;i<=len;i++){
if(s[i]=='_'){
ans.push(node{1,1});
}else{
node qian=ans.top();ans.pop();
node hou=ans.top();ans.pop();
int ysum=0,lsum=0;
if(s[i]=='+'){
ysum=(qian.l*hou.y%mod+qian.y*hou.l%mod+qian.y*hou.y%mod)%mod;
lsum=(qian.l*hou.l)%mod;
}else{
lsum=(qian.l*hou.y%mod+qian.y*hou.l%mod+qian.l*hou.l%mod)%mod;
ysum=(qian.y*hou.y)%mod;
}
ans.push(node{lsum,ysum});
}
}
cout<<ans.top().l;
return 0;
}
/*
0
(+)*(+)
——+——+*
*/