介绍
这篇博客是本人学习机器学习过程中的总结笔记,包含很多有用的学习资料,希望可以帮助萌新铺好入门的路。
个人认为,入门机器学习可以分以下几个阶段:
了解机器学习的流程-->先熟悉模型应用场景,大致原理-->学习实操建模,把模型跑起来,并检验模型的效果-->研究数学原理和算法
本文主要涉及梳理流程、实践操作工具、学习资料推荐和学习方法介绍,不涉及对机器学习算法的研究,萌新们可以把这篇文章当成目录来用。欢迎大佬指正!
实践工具推荐:
数据导入和数据处理:pandas - Python Data Analysis Library (pydata.org)
machine learning API:
scikit-learn: machine learning in Python — scikit-learn 0.24.2 documentation
TensorFlow核心 | TensorFlow中文官网 | TensorFlow Core (google.cn)
Quickstart — PyTorch Tutorials 1.9.0+cu102 documentation
想研究数学原理的盆友戳这里:
【机器学习】【白板推导系列】【合集 1~23】_哔哩哔哩_bilibili
配合看李航的《统计学习方法》
实操与算法结合可以看《机器学习实战》
想学习深度学习:
(强推)李宏毅2021春机器学习课程_哔哩哔哩_bilibili
3Blue1Brown的个人空间深度学习频道_哔哩哔哩_bilibili
原理+论文+实战:60篇由浅入深的时间序列预测/分类教程汇总
本文梳理了机器学习的基本流程,并对新手容易踩的坑做出一些提醒。
Preprocess
cleaning
补全空缺的数据:linear interpolation,时间序列回归
删除离群的数据
standardization/noralization

feature extraction
feature construction
category feature: one-hot encoding
dummy variable
feature selection
construct model
classification
解决分类不平衡问题
1.换用不受
2.基于代价函数的分类器决策控制
3.在抽样时平衡,少的一类过抽样或者多的一类欠抽样
regression
1.自回归(Recursive prediction strategy)
用以前的数据预测以后
AR, MA, ARMA, ARIMA and SARIMA
2.直接预测(direct prediction strategy)
用当天的特征(包括时间特征转换为独热编码+其他与该指标相关的特征)预测当天
train model
训练模型的过程其实就是机器自己学习的过程,这里借3blue1brown的话描述一下什么是machine learning的learning:通过输入样例找到正确的参数(such as weights,bias)的过程就是learning,所以这一步一般只需要调用接口,然后输入已经预处理好的样例,剩下的就是计算机用算法帮你找模型的过程了。
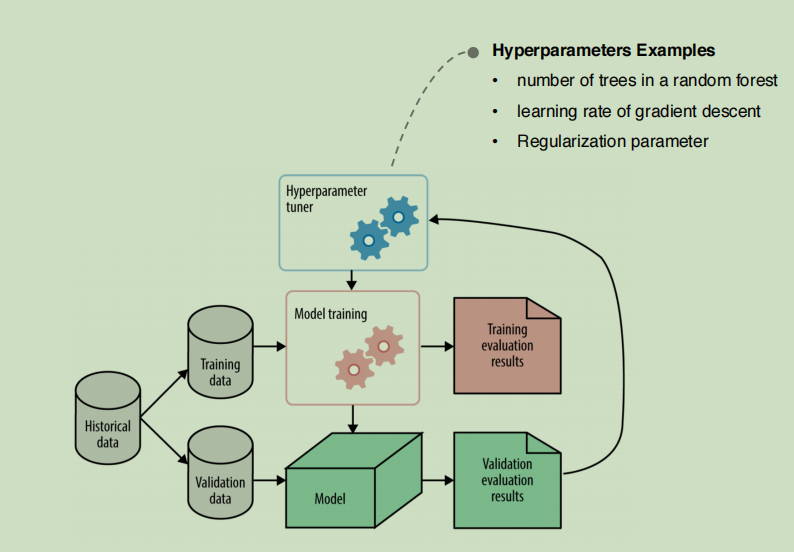
Tuning the Hyperparameter
Hyper-parameters are parameters that are not directly learnt within estimators. In scikit-learn they are passed as arguments to the constructor of the estimator classes. Typical examples include C, kernel and gamma for Support Vector Classifier, alpha for Lasso, etc.(引自sklearn技术文档)
我们要调整的是在训练模型之前就要设定好的超参数,其他参数是在模型的训练过程中生成的,比如回归分析的回归系数。
3.2. Tuning the hyper-parameters of an estimator — scikit-learn 0.24.2 documentation
调参依赖对算法的理解,模型的参数文档会给出一些选择参数的提示,需要穷举尝试不同参数的时候可以使用sklearn的调参工具进行Grid Search和Random Search。
k折交叉验证
k折交叉验证(英语:k-fold cross-validation),将训练集分割成k个子样本,一个单独的子样本被保留作为验证模型的数据,其他k − 1个样本用来训练。交叉验证重复k次,每个子样本验证一次,平均k次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10次交叉验证是最常用的。

regularization
正则化(Regularization)是机器学习中一种常用的技术,其主要目的是控制模型复杂度,减小过拟合。最基本的正则化方法是在原目标(代价)函数 中添加惩罚项,对复杂度高的模型进行“惩罚”。其数学表达形式为:
其中 为代价函数,
即为惩罚项
正则化系数α是在模型复杂度与模型准确性之间的平衡,数学本质是基于约束条件的最优化。
L1,L2正则化:
正则化的效果:
L1正则化就是在loss function后边所加正则项为L1范数,加上L1范数容易得到稀疏解(0比较多)。L2正则化就是loss function后边所加正则项为L2范数的平方,加上L2正则相比于L1正则来说,得到的解比较平滑(不是稀疏),但是同样能够保证解中接近于0(但不是等于0,所以相对平滑)的维度比较多,降低模型的复杂度。
model assessment
bias and variance
简单来说,bias是实际模型与理想模型(假设这是一个每个样本点都预测正确的模型)之间的差距,用来描述模型的拟合能力,bias越小,拟合能力越强。可以通过建立更复杂的模型,引入更多特征来解决由bias引起的问题。
variance是模型在不同数据集上的拟合效果的差别,variance较大,说明模型存在过拟合的问题。
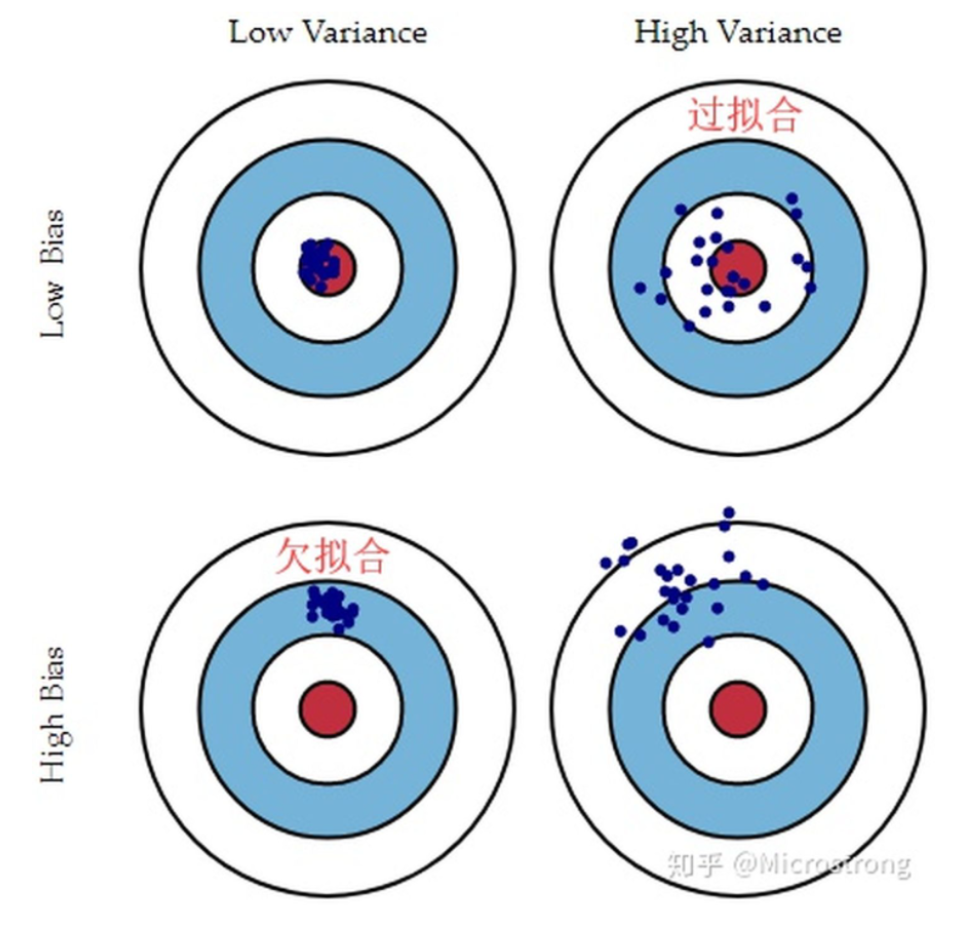
建议参看李毅宏教授的机器学习课程:
evaluate index
classification
AUC:
threshold
propability
越接近1越好
我们希望FP和FN为0
accuracy,precision,recall,sensitivity,specificity,AUC,F1 score
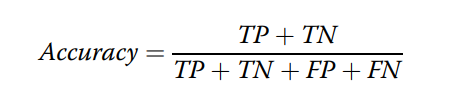
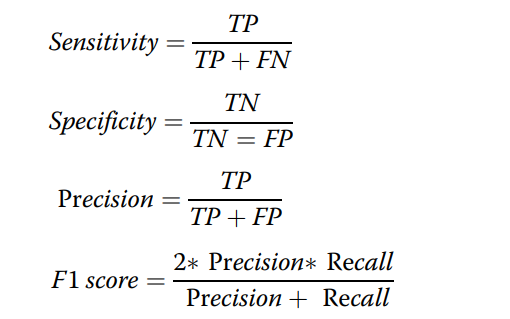
(revise:specificity分母的=改为+)
越接近0越好
误差类
log-loss
regression
误差(error)类,越小越好
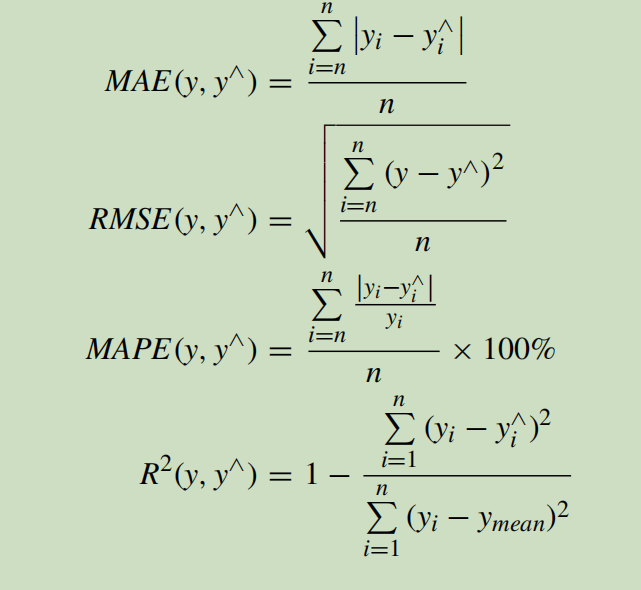
相关系数类,越接近1越好

feature importance
model comparison
一般而言,统计测试(statistical test)是比较模型差异的绝好工具。有两类,一类用于比较简单的机器学习模型,例如配对卡方检验(McNemar’s test)可以比较两个分类器;另一类适用于大多数情况,例如评估某种数据类型是用神经网络还是决策树进行处理的时候,交叉验证、重复采样等等是比较适合的方法。
不同模型的AUC比较:deLong test
新手避坑
1.不对数据做预处理和特征分析就直接用来训练模型。
2.做回归分析之前要先做相关性检验和平稳性检验,数据分析存在相关性,逻辑上可能存在因果关系才能做回归分析。
3.不理解调参的意义,在训练模型时用到了testSet中的数据。
调参后用trainSet训练模型,用validSet检验调参的结果,再调参再训练。整个调参过程中不用到testSet,testSet是完成建模之后用来评价模型的。
https://mp.weixin.qq.com/s/_iRZA4nZNCgWQKxl8TD-TQ
参考文章