Shell
所有 Linux 发行版默认的 shell 都是 bash shell,在本文侧重于基础的 GNU bash shell 下面是其他几种流行的 shell
-
ash: 简单的轻量级 shell 完全兼容 bash shell
-
korn: 兼容 Bourne shell 的编程 shell
-
tcsh: 融入部分 C 语言特性
-
dash:
-
Debian Linux 发行版与其许多衍生产品 dash shell,它是 ash shell 的直系后裔,是 Unix 系统中 Bourne shell 的简易复制品
-
在许多基于 Debian 的 Linux 发行版中,dash shell 实际上并不是默认 shell
-
由于 dash 以简洁为目标,因此其使用的环境变量比 bash 明显要少,但 dash 环境中无法使用的 bash 特性
- 算术运算
- test 命令不同
- 不支持 function 语句
-
-
zsh:
-
结合 bash, korn, tcsh 的特性的高级 shell
-
对比 bash 另一个流行的 shell,它汲取了所有现存 shell 的设计理念,增加了许多独有的特性
-
是为程序员而设计的一款高级 shell
-
独有特性
- 改进的 shell 选项处理
- shell 兼容性模式
- 可加载模块
-
到目前为止,zsh shell 是所有 shell 中可定制性最强的
-
可以轻松地执行数学函数
-
进入命令行
在图形化桌面出现之前,系统交互的唯一方式就是通过 shell 提供的 文本命令行界面 command line interface,CLI
-
控制台终端
- 该模式只在显示器上提供一个简单的
shell CLI,称作 Linux 控制台,因为它模拟的早期的硬接线控制台终端 - Linux 系统启动时会自动创建多个 虚拟控制台,虚拟控制台是运行在Linux系统内存中的终端会话,多数 Linux 发行版会启动 5~6 个(甚至更多) 虚拟控制台 代替 哑终端
- 在大多数 Linux 发行版中,可以使用简单的按键组合来访问某个 Linux 虚拟控制台,通常必须按下
Ctrl+Alt组合键再按一个功能键(F1~F7)来进入你要使用的虚拟控制台
注意:在 Linux 虚拟控制台中是无法运行任何图形化程序的,尽管虚拟控制台只是一个文本模式的控制台终端,但你也可以修改文字和背景色
setterm --inversescreen on作用是文字色和背景色交换,使用setterm --inversescreen off可以关闭setterm -background将终端的背景色改为指定颜色setterm -foreground将终端的前景色改为指定颜色,参数: black, red, green, yellow, blue, magenta, cyan, white 共 8 种颜色setterm -reset可以恢复默认设置
- 该模式只在显示器上提供一个简单的
-
图形化终端
-
虚拟控制台终端的另一种替代方案是使用 Linux 图形化桌面环境中的 终端仿真软件包,终端仿真软件包会在桌面图形化窗口中模拟控制台终端
-
一些流行的图形化终端仿真器软件包
- Alacritty
- cool-retro-term
- GNOME Terminal
- Guake
- Konsole
- kitty
- rxvt-unicode
- Sakura
- st
- Terminator
- Terminology
- Termite
- Tilda
- xterm
- Xfce4-terminal
- Yakuake
-
常用的 GNOME Terminal, Konsole, xterm
-
启动 shell
-
GNU bash shell 是一个程序,提供了对 Linux 系统的交互式访问,系统启动的 shell 程序取决于用户账户的配置,在
/etc/passwd文件包含了所有系统用户账户以及每个用户的基本配置信息 -
尽管 bash shell 会在登录时自行启动,但是否会出现 CLI 取决于所使用的登录方式
- 采用的是虚拟控制台终端登录,那么 CLI 提示符会自动出现
- 通过图形化桌面环境登录Linux系统,则需要启动图形化终端仿真器来访问 shell CLI 提示符
- 默认的 bash shell 提示符是美元符号
$,不同的 Linux 发行版会采用不同格式的提示符,shell 提示符并非一成不变 - 当你登录系统并获得 shell CLI 提示符后,shell 会话会从你的主目录开始
-
大多数 Linux 发行版自带在线手册,可用于查找 shell 命令以及其他 GNU 实用工具的相关信息,
man命令可以访问 Linux 系统的手册页。在
man命令之后跟上想要查看的命令名,就可以显示相应的手册页man 命令名-
当你使用 man 命令查看命令手册页的时候,其中的信息是由 分页程序
pager来显示的 -
可以按 q 键 退出手册页
-
手册页将与命令相关的信息分成了多段,每一段的惯用名标准,另外有些命令使用的段名并没有在上面的惯用标准中列出
- Name: 命令名称及简要描述
- Synopsis: 命令语法
- Configuration: 命令配置信息
- Description: 命令的基本描述
- Option: 命令选项描述
- Exit Status: 命令退出状态
- Return Value: 返回值
- Errors: 错误信息
- Environment: 环境变量
- Files: 使用的文件
- Versions: 版本信息
- Conforming To: 遵循的命名标准
- Notes: 其他帮助资料
- Bugs: 提交 Bug 的途径
- Example: 命令用法示例
- Authors: 开发人员信息
- Copyright: 源码版权信息
- See Also: 类似命令
-
man 命令可以使用 关键字 来搜索手册页
man -k keyword -
手册页中还有不同的节,每节都分配了一个数字,从 1~9 章节
# 阅读方法 man num intro # num 是每节的数字- 1: 可执行程序或 shell 命令
- 2: 系统调用
- 3: 库调用
- 4: 特殊文件
- 5: 文件格式约定
- 6: 游戏
- 7: 概念,约定,杂项
- 8: 超级用户和系统管理员相关命令
- 9: 内核线程 routine
Linux 系统手册页可能包含一些非标准的节编号
-
大多数命令接受 -h 或 --help 选项
-
-
了解如何在命令行中输入该命令
COMMAND-NAME [OPTION]... [ARGUMENT]...- COMMAND-NAME 命令名称
- OPTION 修改命令行为的选项
- ARGUMENT 是传递给命令的参数
- [] 代表命令的必要性,有意味可选非必要
- ... 表示可以一次或指定多
常用命令
- cd: 目录切换,允许绝对路径或相对路径
- pwd: 命令可以显示出 shell 会话的当前目录
- ls: 显示当前目录下的文件和目录,允许使用通配符
- touch: 创建好指定的文件并将你的用户名作为该文件的属主
- mkdir: 创建好指定的目录并将你的用户名作为该文件的属主
- ln: 创建链接文件
- cp: 复制文件,复制目录需要 -R 选项,格式 cp src dest,其中 src 允许使用通配符
- mv: 移动目录或文件,可以起到重命名作用,该操作不改变文件的 inode 编号或时间戳
- rm: 删除文件或目录
查看文件内容
- file: 能够探测文件的内部并判断文件类型
- cat: 显示文本文件中所有数据
- more: 分页查看
- less: more 升级版,能够实现在文本文件中前后翻动,还有一些高级搜索功能,还可以在完成整个文件的读取之前显示文件的内容
- tail: 显示文件最后几行的内容,默认 10 行
- head: 显示文件开头几行的内容,默认 10 行
系统管理命令
-
ps: 监测进程,默认只显示运行在当前终端中属于当前用户的那些进程
- PID: 程序的 进程 ID
process ID,PID - TTY: 从属终端
- TIME: 其占用的 CPU 时间
- CMD: 进程名称
Linux 系统中使用的 GNU ps 命令支持以下3种类型的命令行选项:
-
Unix 风格选项,选项前加单连字符
需要查看系统中运行的所有进程,可以使用
-ef选项组合-
-e选项指定显示系统中运行的所有进程 -
-f选项则扩充输出内容以显示一些有用的信息列- UID: 启动该进程的用户
- PID: 进程 ID
- PPID: 父进程的 PID(如果该进程是由另一个进程启动的)
- C: 进程生命期中的 CPU 利用率
- STIME: 进程启动时的系统时间
- TTY: 进程是从哪个终端设备启动的
- TIME: 运行进程的累计 CPU 时间
- CMD: 启动的程序名称
-
-l选项之后多出的信息列-
F: 内核分配给进程的系统标志
-
S: 进程的状态
- O 代表正在运行
- S 代表在休眠
- R 代表可运行,正等待运行
- Z 代表僵化,已终止但找不到其父进程
- T 代表停止
-
PRI: 进程的优先级(数字越大,优先级越低)
-
NI: 谦让度,用于决定优先级
-
ADDR: 进程的内存地址
-
SZ: 进程被换出时所需交换空间的大致大小
-
WCHAN: 进程休眠的内核函数地址
-
-
-
BSD 风格选项,选项前不加连字符
在使用 BSD 风格的选项时,ps命令会自动改变输出以模仿 BSD 格式,上述很多输出列跟使用 Unix 风格选项时是一样的,但还是有一些不同之处
-
VSZ: 进程占用的虚拟内存大小(以 KB 为单位)
-
RSS: 进程在未被交换出时占用的物理内存大小
-
STAT: 代表当前进程状态的多字符状态码
进程状态码:第一个字符采用了与Unix风格的 S 输出列 相同的值表明进程是在休眠、运行还是等待,第二个字符进一步说明了进程的状态
- <: 该进程以高优先级运行
- N: 该进程以低优先级运行
- L: 该进程有锁定在内存中的页面
- s: 该进程是控制进程
- l: 该进程拥有多线程
- +: 该进程在前台运行
-
-
GNU 长选项,选项前加双连字符
GNU 开发人员在经过改进的新ps命令中加入了另外一些选项,其中一些 GNU 长选项复制了现有的 Unix 或 BSD 风格选项的效果,而另外一些则提供了新功能
--forest选项能够使用 ASCII 字符来绘制图表以显示进程的层级信息
- PID: 程序的 进程 ID
-
top: 可以实时显示进程信息
在top命令运行时键入可改变top的行为
- 键入
f允许你选择用于对输出进行排序的字段 - 键入
d允许你修改 轮询间隔polling interval - 键入
q可以退出 top
利用该工具,可以轻易找出占用系统大量资源的罪魁祸首
- 键入
-
kill: 会向命令行中列出的所有 PID 发送 TERM 信号,TERM 信号会告诉进程终止运行
- 只能使用进程的 PID 而不能使用其对应的程序名
- 要发送进程信号,必须是进程的属主或 root 用户
-s选项支持指定其他信号
要检查 kill 命令是否生效,可以再次执行 ps 命令或 top 命令,看看那些进程是否已经停止运行
-
pkill: 可以使用程序名代替 PID 来终止进程,允许使用通配符
注意:以 root 身份使用命令中的通配符很容易意外地将系统的重要进程终止,这可能会导致文件系统损坏
-
mount: 用于挂载存储设备,默认情况下会输出当前系统已挂载的设备列表
命令提供了4部分信息:
- 设备文件名
- 设备在虚拟目录中的挂载点
- 文件系统类型
- 已挂载设备的访问状态
手动挂载设备的基本命令:
mount -t type device directory-
type: 磁盘格式化所使用的文件系统类型
与
Windows PC共用移动存储设备,通常需要使用下列文件系统类型- vfat: Windows FAT32文件系统,支持长文件名
- ntfs: Windows NT及后续操作系统中广泛使用的高级文件系统
- exfat: 专门为可移动存储设备优化的Windows文件系统
- iso9660: 标准CD-ROM和DVD文件系统
大多数 U 盘会使用 vfat 文件系统 格式化,如果需要挂载数据 CD 或 DVD,则必须使用 iso9660 文件系统 类型
-
device: 该存储设备的设备文件位置
-
directory: 挂载点在虚拟目录中的位置
注意:存储设备被挂载到虚拟目录,root 用户就拥有了对该设备的所有访问权限,而其他用户的访问则会被限制
-
umount: 移除可移动设备时,不能直接将设备拔下,应该先卸载
命令的格式:
umount [device | directory]支持通过 设备文件 或者 挂载点 来指定要卸载的设备,如果有任何程序正在使用设备上的文件,则系统将不允许卸载该设备
-
df: 查看所有已挂载磁盘的使用情况
-
du: 可以显示某个特定目录(默认情况下是当前目录)的磁盘使用情况
处理数据命令
-
sort: 对数据进行排序
-t选项指定字段分隔符-k选项指定排序字段-n选项将数字按值排序-M选项将数字按月排序
-
grep: 会在输入或指定文件中逐行搜索匹配指定模式的文本
-
gzip: 用于压缩文件
-
gzcat: 用于查看压缩过的文本文件的内容
-
gunzip: 用于解压文件
Linux 基础管理命令
用户管理
-
useradd: 向 Linux 系统添加新用户
- 默认值使用 /etc/default/useradd 文件设置
- 安全设置在 /etc/login.defs 文件中定义
- 用户账户管理命令需要以 root 用户账户登录或者通过
sudo命令运行
-
userdel: 从系统中删除用户
- 默认情况下,userdel 命令只删除 /etc/passwd 和 /etc/shadow 文件中的用户信息,属于该账户的文件会被保留
-r选项,则userdel会删除用户的 $HOME 目录以及邮件目录,然而系统中仍可能存有已删除用户的其他文件
-
修改用户
-
usermod: 提供了修改 /etc/passwd 文件中大部分字段的相关选项只需指定相应的选项即可,大部分选项与useradd命令的选项一样
- -l: 修改用户账户的登录名
- -p: 修改账户密码
- -U: 解除锁定,恢复用户登录
- -L: 可以锁定账户,使用户无法登录,无须删除账户和用户数据
- -G: 提供向组中添加用户不会影响主要组,更改了已登录系统的用户所属的组,则该用户必须注销后重新登录,这样新的组关系才能生效
- -g: 则指定的组名会替换掉在 /etc/passwd 文件中为该用户分配的主要组
-
passwd: 可以方便地修改用户密码,只有 root 用户才有权限修改别人的密码
-
chpasswd: 能从标准输入自动读取一系列以冒号分隔的登录名和密码对偶
-
chfn: 提供了在 /etc/passwd 文件的备注字段中保存信息的标准方法,会将用于 Unix 的 finger 命令的信息存入备注字段
-
finger: 可以非常方便地查看 Linux 系统的用户信息,安装该命令可能会使你的系统受到攻击漏洞的影响
-
chage: 命令可用于帮助管理用户账户的有效期
-
-
groupadd: 可用于创建新组
-
groupdel: 删除组
-
groupmod: 可以修改已有组
-
文件权限:
-
文件权限符号
- r 代表对象是可读的
- w 代表对象是可写的
- x 代表对象是可执行的如果没有某种权限,则在该权限位会出现连字符
-
组权限分别对应对象安全级别
- 对象的属主
- 对象的属组
- 系统其他用户
-
umask: 用来设置新建文件和目录的默认权限
-
chmod: 可以修改文件和目录的安全设置,参数允许使用八进制模式或符号模式来进行安全设置
-
chown: 前者可以修改文件的属主,可以修改文件的所有符号链接文件的所属关系
命令的格式
chown options owner[.group] file -
chgrp: 后者可以修改文件的默认属组
-
-
访问控制列表 ACL
-
getfacl: 能够查看分配给文件或目录的 ACL
-
setfacl: 能够设置分配给文件或目录的 ACL
-m选项修改分配给文件或目录的权限-x选项删除特定权限
3 种格式定义规则
u[ser]:uid:perms g[roup]:gid:perms o[ther]::perms- 要为用户分配权限,可以使用 user 格式
- 要为组分配权限,可以使用 group 格式
- 要为其他用户分配权限,可以使用 other 格式
-
管理文件系统
-
fdisk: 可以在任何存储设备上创建和管理分区,但是只能处理最大 2TB 的硬盘
- 如果存储设备是首次分区,则会警告你该设备没有分区表
- 是一个交互式程序,允许你输入命令来逐步完成硬盘分区操作
- 需要指定待分区的存储设备的名称,同时还必须有超级用户权限
- 不允许调整现有分区的大小,你能做的是删除现有分区后重新创建
-
gdisk: 如果存储设备要采用 GUID 分区表
GUID partition table,GPT,就要用到- 会识别存储设备所采用的分区类型
- 在转换存储设备分区类型的时候务必小心,所选择的类型必须与系统固件兼容
- 提供了自己的命令行提示符,允许输入命令进行分区操作
-
GNU parted: 操作命令偏向词
- 允许调整现有的分区大小,所以可以很容易地收缩或扩大磁盘分区
将数据存储到分区之前,必须使用某种文件系统对其进行格式化,并非所有的文件系统工具都已经默认安装过,要想知道某个工具是否可用,可以使用 type 命令
- mkefs: ext
- mke2fs: ext2
- mkfs.ext3: ext3
- mkfs.ext4: ext4
- mkreiserfs: ReiserFS
- jfs_mkfs: JFS
- mkfs.xfs: XFS
- mkfs.zfs: ZFS
- mkfs.btrfs: Btrfs
为分区创建好文件系统之后,下一步是将其挂载到虚拟目录中的某个挂载点,以便在新分区中存储数据
- mount 命令会将新分区的文件系统添加到挂载点
- 挂载文件系统的方法只能实现临时挂载,重启系统后就失效了,要强制 Linux 在启动时自动挂载文件系统可以将其添加到
/etc/fstab文件中
文件系统的检查与修复,每种文件系统各自都有相应的恢复命令
-
fsck: 可以检查和修复大部分Linux文件系统类型
- 日志文件系统的用户确实也要用到 fsck 命令,但对于 COW 文件系统需要高级修复选项
- 只能对未挂载的文件系统执行 fsck 命令,对大多数文件系统只需先卸载文件系统,检查完成之后再重新挂载即可
LVM 管理
-
物理卷 PV
- pvscan: 扫描 PV
- pvcreate: 指定了一个未使用的磁盘分区(或整个驱动器)由 LVM 使用,在这个过程中 LVM 结构、卷标和元数据都会被添加到该分区
- pvdisplay: 显示 PV 信息
- pvremove: 删除 PV
-
卷组 VG
-
vgscan: 扫描 VG
-
vgcreate: 会将 物理卷
PV加入存储池,后者随后用于构建各种逻辑卷- 可以存在多个卷组
- 将一个或多个 PV 加入 卷组
VG时,也会同时添加卷组的元数据 - 被指定为 PV 的分区只能属于单个 VG,但被指定为 PV 的其他分区可以属于其他 VG
-
vgdisplay: 显示 VG 信息
-
vgremove: 删除 VG
-
vgextend: 拓展 VG
-
vgreduce: 缩小 VG
-
-
逻辑卷 LV
-
lvscan: 扫描 LV
-
lvcreate: 逻辑卷
LV由 VG 的 存储空间块PE组成- 可以使用文件系统格式化 LV,然后将其挂载,像普通的磁盘分区那样使用
- 可以有多个 VG,但 LV 只能从一个指定的 VG 中创建
- 多个 LV 可以共享单个 VG
-
lvdisplay: 显示 LV 信息,也可以使用 lvs 命令和 lvscan 命令显示系统的 LV 信息
-
lvremove: 删除 LV
-
lvextend: 拓展 LV
-
lvreduce: 缩小 LV
-
要想了解所有的 LVM 命令,可以在命令行中输入 lvm help
软件包管理系统
-
基于 Debian 的系统,基本使用
-
dpkg: 是基于 Debian 的软件包管理器的核心,用于在Linux系统中安装、更新、删除 DEB 包文件
-
APT 工具集
- apt-cache
- apt-get
- apt: 命令本质上是 apt-cache 命令和 apt-get 命令的前端
apt 仓库: 仓库位置保存在文件 /etc/apt/sources.list 中
-
-
基于 Red Hat 的系统
- rpm: 是基于 Debian 的软件包管理器的核心
- yum: 用于 Red Hat, CentOS, Fedora
- zypper: 用于 openSUSE
- dnf: yum 的升级版,有一些新增的特性
dnf 仓库:
- 配置文件 /etc/dnf/dnf.conf
- /etc/yum.repos.d 目录中的单独文件
使用容器管理软件
-
snap: 管理 snap 格式的应用程序容器
- 在安装 snap 的时候,snapd 程序会将其作为驱动器挂载
-
flatpak: 管理 flatpak 格式应用程序容器
理解 shell
-
shell 类型
- 默认的交互式 shell
default interactive shell也称 登录 shelllogin shell,只要用户登录某个虚拟控制台终端或是在 GUI 中启动终端仿真器,该 shell 就会启动 - 默认的系统 shell
default system shell,/bin/sh用于那些需要在启动时使用的系统shell脚本
- 默认的交互式 shell
-
$0当前 shell 的名称 -
exit 可以退出 shell
子 shell
-
用户登录某个 虚拟控制台终端 或在 GUI 中运行 终端仿真器 时所启动的默认的交互式 shell 之后,当 CLI 提示符处输入 bash 命令(或是其他 shell 程序名)时会创建新的 shell 程序,这是一个 子 shell
-
生成子进程时,只有部分父进程的环境被复制到了子环境中
-
bash 常用选项
-c string: 从 string 中读取命令进行处理-i: 启动一个交互性 shell-l: 做为 login shell-r: 启动一个受限 shell-s: 从标准输入读取命令
-
-
命令分组
- 使用
()圆括号进程列表,生成了一个子 shell 来执行这些命令 - 使用
{}花括号进行命令分组并不会像进程列表那样创建子 shell
- 使用
-
$BASH_SUBSHELL变量判断是否存在子 shell- 返回 0,那么表明没有子 shell
- 返回大于 0 的数字,则表明存在子 shell
-
子 shell 在 shell 脚本中经常用于 多进程处理
-
在 交互式 shell 中,一种高效的子 shell 用法是 后台模式
- 想将命令置入后台模式,可以在命令末尾加上字符
& - 当其被置入后台时,在 shell CLI 提示符返回之前,屏幕上会出现 后台作业号 和 进程 ID
jobs命令能够显示当前运行在后台模式中属于你的所有进程
- 想将命令置入后台模式,可以在命令末尾加上字符
-
coproc: 创建协程同时做两件事:
- 在后台生成一个子 shell
- 在该子 shell 中执行命令
- 除了会创建子 shell,协程基本上就是将命令置入后台
-
外部命令(有时也称为文件系统命令)是存在于bash shell之外的程序
- 它并不属于shell程序的一部分
- 外部命令程序通常位于 /bin, /usr/bin, /sbin, /usr/sbin 目录中
- 每当执行外部命令时,就会创建一个子进程,这种操作称为 衍生
forking
-
内建命令无须使用子进程来执行
- 已经和 shell 编译成一体,作为 shell 的组成部分存在,无须借助外部程序文件来执行
type命令来判断某个命令是否为内建
-
history: 跟踪你最近使用过的命令,是一个实用的内建命令,使用
!!执行上一条命令 -
alias: 别名允许为常用命令及其参数创建另一个名称,从而将输入量减少到最低,另一个实用的shell内建命令
- 选项
-p可以查看当前可用的别名
- 选项
-
unalias: 删除别名
环境变量
环境变量可以存储 shell 会话和工作环境的相关信息,允许在内存中存储数据以便 shell 中运行的程序或脚本能够轻松访问到这些数据
-
全局变量:全局环境变量对于 shell 会话和所有生成的子 shell 都是可见的
- 可以使用
env命令来查看全局变量,使用printenv命令显示个别环境变量的值
- 可以使用
-
局部变量:只对创建它的 shell 可见
set命令可以显示特定进程的所有环境变量,既包括局部变量、全局变量
-
引用某个环境变量时,必须在该变量名前加上美元符号
$
可以在 bash shell 中直接设置自己的变量
- 可以使用等号为变量赋值实现 局部环境变量,值可以是数值或字符串
- 在变量名、等号和值之间没有空格,这一点非常重要
export命令以及要导出的变量名(不加$符号)来实现 全局环境变量- 修改子 shell 中的全局环境变量并不会影响父 shell 中该变量的值
unset命令能删除已有的环境变量- 在子进程中删除了一个全局环境变量,那么该操作 仅对子进程有效,该全局环境变量在父进程中依然可用
- 任何由父 shell 设置但 未导出的变量都是局部变量,不会被子 shell 继承
环境变量的另一个特性是可以作为数组使用
- 环境变量的另一个特性是可以作为数组使用
- 要为某个环境变量设置多个值,可以把值放在 圆括号 中,值与值之间以 空格分隔
- 要引用单个数组元素,必须使用表示其在数组中位置的 索引,索引要写在 方括号 中,且 $ 符号 之后的所有内容都要放入 花括号 中
unset命令可以删除数组中的某个值,后跟上数组名来删除整个数组- 数组并不太方便移植到其他 shell 环境,有时候数组变量只会把事情搞得更复杂
默认的 shell 环境变量
- CDPATH: 以冒号分隔的目录列表,做为 cd 命令的搜索路径
- HOME: 当前用户主目录
- IFS: shell 用来将文本字符串分割为字符
- MAIL: 当前用户收件箱的文件名
- MAILPATH: 当前用户收件箱的文件名列表
- OPTARG: getop 命令处理的最后一个选项参数
- OPTIND: getop 命令处理的最后一个选项参数的索引
- PATH: shell 查找命令的目录列表,只需引用原来的 PATH 值添加冒号,然后再使用绝对路径输入新目录,对于 PATH 变量的修改只能持续到退出或重启系统
- PS1: shell 命令行主提示符
- PS2: shell 命令行次提示符
- HISTFILESIZE: 历史记录列表上限,位于内存中
- HISTSIZE: 历史记录文件上限,位于硬盘上
当你登录 Linux 系统启动 bash shell 时,默认情况下 bash 会在几个文件中查找命令。这些文件称作 启动文件 或 环境文件
-
登录 shell 通常会从 5 个不同的启动文件中读取命令
-
/etc/profile- 是系统中默认的 bash shell 的主启动文件,系统中的 每个用户 登录时都会执行这个启动文件
- 每种发行版的 /etc/profile 文件都有不同的设置和命令
-
$HOME/.bash_profile- 先检查 $HOME 目录中是不是还有一个名为 .bashrc 的启动文件,有就先执行该文件中的命令
-
$HOME/.bashrc- 检查 /etc 目录下的通用 bashrc 文件
- 为用户提供一个定制自己的命令别名
-
$HOME/.bash_login -
$HOME/.profile
$HOME目录下的启动文件:提供用户专属的启动文件来定义该用户所用到的环境变量,Linux 发行版在环境文件方面存在的差异非常大,有些用户可能只有一个 $HOME/.bash_profile 文件,顺序 $HOME/.bash_profile -> $HOME/.bash_login -> $HOME/.profile 在 $HOME/.bashrc 文件通常通过其他文件运行-
作为交互式 shell 启动的 bash 并不处理 /etc/profile 文件,只检查用户 $HOME 目录中的 .bashrc 文件
-
非交互式 shell,系统执行shell脚本时用的就是这种 shell
- bash shell 提供了
BASH_ENV环境变量:当shell启动一个 非交互式 shell 进程时,会检查这个环境变量以查看要执行的启动文件名,如果有指定的文件则 shell 会执行该文件里的命令,这通常包括 shell 脚本变量设置
- bash shell 提供了
-
-
有些 Linux 发行版使用了 可拆卸式认证模块
pluggable authentication module,PAM,这种情况下 PAM 文件会在 bash shell 启动之前被处理,前者中可能会包含环境变量/etc/environment$HOME/.pam_environment
环境变量持久化
- 对全局环境变量可能更倾向于将新的或修改过的变量设置放在 /etc/profile 文件中,但升级了所用的发行版则该文件也会随之更新,好在
/etc/profile.d目录中创建一个以 .sh 结尾的文件 - 对保存个人用户永久性 bash shell 变量的最佳地点是
$HOME/.bashrc文件,但如果设置了 BASH_ENV 变量除非值为$HOME/.bashrc,否则应该将 非交互式 shell 的用户变量放在别的地方
构建 shell 脚本
基本使用
-
使用多个命令,彼此用 分号 隔开
-
创建 shell 脚本文件
-
创建 shell 脚本文件时,必须在文件的第一行指定要使用的 shell
#!/bin/bash- 第一行有时被称为 shebang
基本是
#!加 shell 绝对路径 -
注释使用
# -
使用分号将两个命令放在一行中,但在shell脚本中,可以将命令放在独立的行中
-
-
使用 shell 脚本:需要 可执行权限 和 下面查找命令规则之一
- 将放置 shell 脚本文件的目录添加到 PATH 环境变量中
- 在命令行中使用绝对路径或相对路径来引用 shell 脚本文件
-
echo: 输出会显示在脚本所运行的控制台显示器,可用单引号或双引号来划定字符串
-
变量使用
- 在脚本中,可以在环境变量名之前加上
$来引用这些环境变量 - 反斜线允许 shell 脚本按照字面意义解释 $
- 通过
${variable}形式引用的变量,花括号 通常用于帮助界定 $ 后的变量名 - 变量赋值在变量、等号和值之间不能出现空格
- 引用变量值时要加 $,对变量赋值时则不用加 $
- 在脚本中,可以在环境变量名之前加上
-
命令替换
-
可以从命令输出中提取信息并将其赋给变量
-
两种方法可以将命令输出赋给变量
- 反引号
$()
-
命令替换允许将 shell 命令的输出赋给变量
-
命令替换会创建出子 shell 来运行指定命令,这是由运行脚本的 shell 所生成的一个独立的 shell,在子 shell 中运行的命令无法使用脚本中的变量
-
-
输出重定向
>- 最基本的重定向会将命令的输出发送至文件
- 如果输出文件已存在,则重定向运算符会用新数据覆盖已有的文件
- 不想覆盖文件原有内容,使用
>>
-
输入重定向
<- 输入重定向会将文件的内容重定向至命令
- 还有另外一种输入重定向的方法称为 内联输入重定向
<<,这种方法无须使用文件进行重定向,只需在命令行中指定用于输入重定向的数据即可 - 除了
<<符号,必须指定一个 文本标记 来划分输入数据的起止
-
管道
|- 将一个命令的输出作为另一个命令的输入
- 管道可以串联的命令数量没有限制
-
执行数学运算
-
expr: 最初,Bourne shell 提供了一个专门用于处理数学表达式的命令
- 可在命令行中执行数学运算,但是特别笨拙
- 能够识别少量算术运算符和字符串运算符
- 标准运算符在 expr 命令中工作得很好,但在脚本或命令行中使用时仍有问题出现
- 那些容易被 shell 错误解释的字符被传入 expr 命令之前,需要使用 转义字符 对其进行转义
- 为了兼容 Bourne shell,bash shell 保留了 expr 命令
-
使用方括号
- 在 bash 中,要将数学运算结果赋给变量,可以使用
$和 方括号 - 在使用方括号执行数学运算时,无须担心 shell 会误解乘号或其他符号
- bash shell 的数学运算符只支持整数运算,但 zsh 提供了完整的浮点数操作
- 在 bash 中,要将数学运算结果赋给变量,可以使用
-
使用内建的 bash 计算器 bc
- 其中内建变量 scale 控制冗长
- 在脚本中需要结合管道使用,允许你设置变量,如果需要多个变量可以用分号来分隔它们
- 表达式中不仅可以使用数字,还可以用shell脚本中定义好的变量
- 这种方法适用于较短的运算,如果要进行大量运算,最好的办法是使用内联输入重定向
-
-
变量
$?来保存最后一个已执行命令的退出状态码- 对于成功结束的命令,其退出状态码是 0
- 对于因错误而结束的命令,其退出状态码是一个正整数
- 退出状态码被缩减到了 0~255 的区间
结构化命令
-
if-then-elif-then-else
if command1 then commands elif command2 then commands else commands fi-
if 或 elif 根据命令的退出状态码判断 then 中的命令是否执行
- 退出状态码为 0 时执行 then 部分的命令
- 退出状态码为非 0 退出状态码时,执行 else 中代码
-
then 与 if, elif 是配套
-
fi 为闭合开始的 if
-
elif 和 else 为可选
-
-
test: 测试命令,目的是更好的进行条件判断
- 如果 test 命令中列出的条件成立,那么 test 命令就会退出并返回退出状态码 0
- 如果条件不成立,那么 test 命令就会退出并返回非 0 的退出状态码
test condition- condition 要测试的一系列参数和值
- condition 部分没有会以非 0 的退出状态码
bash shell 提供了另一种条件测试方式,可以使用 中括号 替代 test,第一个方括号之后和第二个方括号之前 必须留有空格
test命令和测试条件可以判断 3 类条件:
-
数值比较
使用 -eq, -ge, -gt, -le, -lt, -ne 替代数学中的比较运算符 ==, >=, >, <=, <, != 下面是记忆
- e 与等值相关
- g 与大于相关
- l 与小于相关
- n 有否相关
- q, t 基本比较
-
字符串比较
-
=比较字符串是否相同 -
!=比较字符串是否相同 -
<,>比较两个字符串大小,使用时必须转义- 在比较的时候使用的是每个字符的 Unicode 编码值
- sort 命令处理大写字母的方法刚好与 test 命令相反,比较测试中大写字母被认为是小于小写字母的
-
-n判断字符串长度是否不为 0 -
-z判断字符串长度是否为 0
-
-
文件比较
- -e 是否存在
- -s 是否存在且非空
- -d 是否为目录
- -f 是否为文件
- -r 是否可读
- -w 是否可写
- -x 是否可执行
- -O 是否当前用户是文件属主
- -G 是否当前用户组
- 两个文件比较新旧,测试之前务必确保文件存在
- -nt 是否前者新,new time
- -ot 是否前者旧,old time
-
复合条件测试
- && 与运算
- || 或运算
-
bash shell 在 if 语句中的高级特性
-
在子 shell 中执行命令的单括号
- test 语句中使用进程列表时,可能会出现意料之外的结果
-
用于数学表达式的双括号
- 双括号命令允许在比较过程中使用 高级数学表达式,任意的数学赋值或比较表达式
- test 命令在进行比较的时候只能使用简单的算术操作
- 双括号中表达式的不用转义处理
-
用于高级字符串处理功能的双方括号
- 使用双等号进行模式匹配,右边定义匹配的表达式,支持通配符或正则表达式
- 不是所有的 shell 都支持双方括号
-
-
case: 比较变量寻找特定的值
case variable in pattern1 | pattern2) commands1;; pattern3) commands2;; *) commands3;; esac- 将指定变量与不同模式进行比较
- 竖线运算符在一行中分隔出多个模式
- 星号会捕获所有与已知模式不匹配的值
- esac 进行闭合 case
-
for: 循环处理
for var in list do commands done-
list 是迭代列表,每次迭代中变量 var 会包含列表中的当前值
-
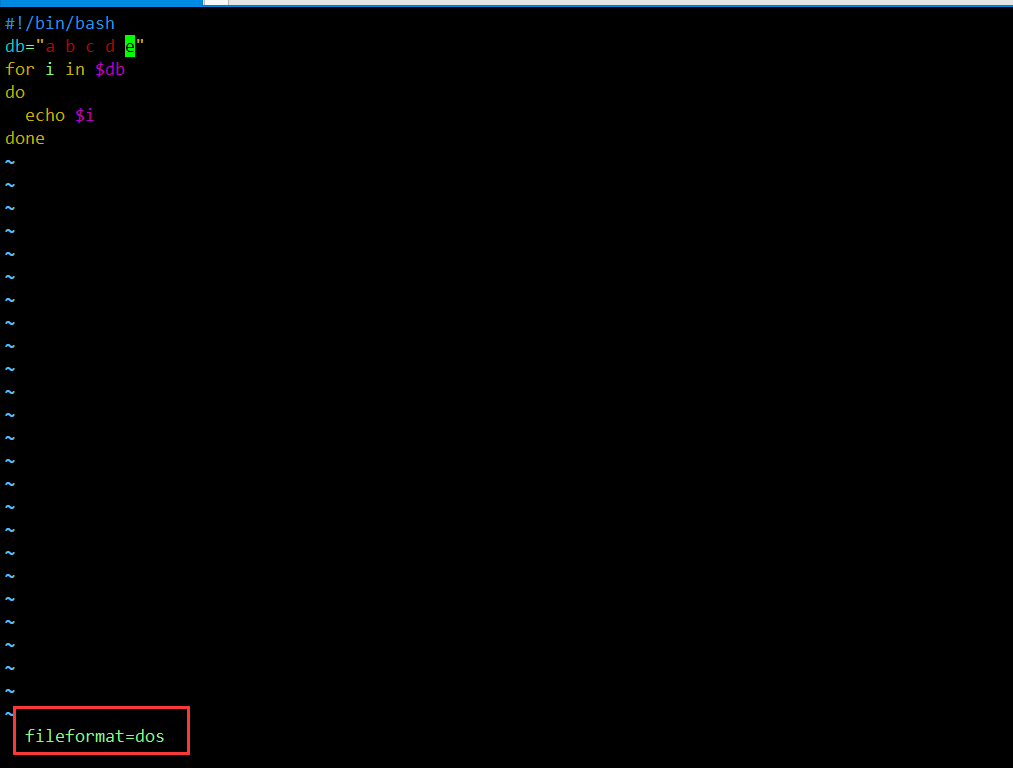
list 中值之间是以 空格 分隔的
-环境变量 内部字段分隔符
IFS可以关闭分隔规则- 需要修改 IFS 的值时,注意将其恢复原状
- 一种安全的做法是在修改IFS之前保存原来的IFS值,之后再恢复它
- 指定多个 IFS 字符,则只需在赋值语句中将这些字符写在一起即可
-
变量包含了用于迭代的值列表可以用于迭代列表,值列表中能追加或者拼接
-
do-done 中为循环体
-
最后一次迭代结束后,变量 var 的值在 shell 脚本的剩余部分依然有效
-
list 中复杂的数据处理
- 使用转义字符
- 使用双引号来划分值
-
从命令中读取值列表
-
使用通配符读取目录
- 此时变量 var 放入双引号内,目录名和文件名中包含 空格 是完全合法的
- 允许列出多个目录通配符
- 即使文件或目录不存在,for 语句也会尝试把列表处理完,最好在处理之前先测试一下文件或目录
-
支持仿 C 语言风格的 for 命令,但注意是使用
(())而不是 C 语言的(),有些地方与bash shell 标准的 for 命令并不一致- 变量赋值可以有空格
- 迭代条件中的变量不以美元符号开头
- 迭代过程的算式不使用expr命令格式
因此,在脚本中使用仿 C 语言的 for 循环时要小心
-
-
while: 某种程度上糅合了 if 语句和 for 循环
该命令返回的退出状态码为0,就循环执行一组命令
while test command do commands done- 判断部分类似 if
- 循环体使用与 for 相同
- 修改测试条件中用到的变量,否则就会陷入死循环
- 允许在 while 语句行定义多个测试命令,但只有最后一个测试命令的退出状态码会被用于决定是否结束循环
- 支持嵌套
-
until: 与 while 命令工作的方式完全相反,注意测试部分是反的即可
-
循环控制
- break: 退出循环,后面可以指定数字,数字是要跳出的循环层级,默认 1
- continue: 提前中止某次循环,也允许通过命令行参数指定要继续执行哪一级循环
-
处理循环的输出
- 对循环的输出使用管道或进行重定向,这可以通过在 done 命令之后添加一个处理命令来实现
处理输入输出
-
传递参数: 向 shell 脚本传递数据的最基本方法是使用命令行参数,命令行参数允许运行脚本时在命令行中添加数据
-
参数之间是以空格分隔的
-
bash shell 会将所有的命令行参数都指派给 位置变量
- 位置变量的名称都是标准数字
- $0 对应脚本名,$1 对应第一个命令行参数,以此类推直到 $9
- 在超过 9 个参数之后,必须在变量名两侧加上花括号,比如 $
- 运行脚本时使用的是绝对路径,那么位置变量 $0 就会包含整个路径
- basename: 只要是用于去除路径和文件后缀部分的文件名或者目录名
-
在使用位置变量之前一定要检查是否为空
-
-
特殊参数变量
$#含有脚本运行时携带的命令行参数的个数- 那么变量
${$#}应该就代表了最后一个位置变量,不能在花括号内使用$,必须将$换成! $*变量会将所有的命令行参数视为一个单词,变量会将这些参数视为一个整体$@变量会将所有的命令行参数视为同一字符串中的多个独立的单词,以便你能遍历并处理全部参数$$当前 PID
-
shift: 移动参数
- 会根据命令行参数的相对位置进行移动
- 默认情况下会将每个位置的变量值都向左移动一个位置
- 变量 $1 的值则会被删除,变量 $0 的值不会改变
- 如果某个参数被移出,那么它的值就被丢弃了无法再恢复
- 也可以一次性移动多个位置,指明要移动的位置数即可
-
处理选项
- 提取单个参数时,使用 case 语句
- 在Linux中这个特殊字符是 双连字符
--,shell 会用双连字符表明选项部分结束 - 选项占用了两个位置,所以还需要使用shift命令多移动一次
getopt: 能够识别命令行参数,简化解析过程,将命令行中选项和参数处理后只生成一个输出
getopt optstring parameters-
optstring:
- 定义了有效的命令行选项字母以及是否需要参数值
- 需要参数值的选项字母后面加一个 冒号
- 未包含你指定的选项,则在默认情况下,getopt 命令会产生一条错误消息,使用 -q 可以忽略
-
parameters: 参数列表
set: 有一个选项是 双连字符
--,可以将 位置变量 的值替换成 set 命令所指定的值set -- $(getopt optstring "$@")- optstring: 是你设计的命令行选项
- getopt 命令并不擅长处理 带空格和引号的参数值,它会将空格当作参数分隔符
getopts: 是 bash shell 的内建命令,比 getopt 多了一些扩展功能,能够和已有的 shell 位置变量配合默契
getopts [:]optstring variable-
getopts 每次只处理一个检测到的命令行参数
-
在处理完所有的参数后,getopts 会退出并返回一个大于 0 的退出状态码,适合用在解析命令行参数的循环中
:为可选,类似 getopt 命令 -p 参数,有则不显示错误消息- optstring 值与 getopt 命令中使用的值类似
- variable 每次处理时存储它们的变量名
-
getopts 涉及两个环境变量
OPTARG环境变量保存带参选项的参数值OPTIND环境变量保存着参数列表中正在处理的参数位置
-
getopts 命令会移除起始的 连字符,所以在 case 语句中不用连字符
-
可以在参数值中加入空格判断引号界限,能将选项字母和参数值写在一起,在两者之间不加空格
-
还可以将在命令行中找到的所有 未定义的选项 统一输出成 问号
-
知道何时停止处理选项,并将参数留给你处理,处理每个选项时,getopts 会将 OPTIND 环境变量值增 1,可以使用 shift 命令和 OPTIND 值来移动参数
-
获取用户输入
-
read: 从标准输入或另一个文件描述符中接受输入
-
获取输入后,read 命令会将数据存入变量
-
如果指定多个变量,则输入的每个数据值都会分配给变量列表中的下一个变量
-
如果变量数量不够,那么剩下的数据就全部分配给最后一个变量
-
不指定任何变量,这会将接收到的 所有数据 都放进特殊环境变量
REPLY -
-p选项,允许直接指定提示符 -
-t选项,指定一个计时器判断是否输入超时,单位秒 -
-n选项,统计输入的字符数,当字符数达到预设值时,就自动退出 -
-s选项,避免在输入的数据出现在屏幕上
读取文件
- 从指定文件中读取一行文本,当文件中没有内容可读时,会退出并返回非 0 退出状态码
-
-
-
标准文件描述符:Linux 系统会将每个对象当作文件来处理,这包括输入和输出
-
文件描述符是一个非负整数,唯一会标识的是会话中打开的文件
- 0: STDIN 文件描述符代表 shell 的标准输入
- 1: STDOUT 文件描述符代表 shell 的标准输出
- 2: STDERR 文件描述符处理错误消息
-
每个进程一次最多可以打开 9 个文件描述符
-
在默认情况下,STDERR 和 STDOUT 指向同一个地方
-
STDERR 并不会随着 STDOUT 的重定向发生改变
-
可以将 文件描述符 索引值放在重定向符号之前,只重定向对应信息,两者必须紧挨着
1>输出重定向标准输出2>输出重定向错误消息
-
bash shell 提供特殊的重定向符
&>将 STDERR 和 STDOUT 的输出重定向
-
-
在脚本中重定向输出
-
临时重定向 &
- 在重定向到文件描述符时,必须在文件描述符索引值之前加一个
& - 非常适合在脚本中生成错误消息
- 在重定向到文件描述符时,必须在文件描述符索引值之前加一个
-
永久重定向 exec
- 在脚本执行期间重定向某个特定文件描述符
- exec 会启动一个新 shell
- 适合脚本中有大量数据需要重定向
- 允许将 STDIN 重定向为文件
-
-
替代性文件描述符
- 替代性文件描述符从 3~8 共6个,均可用作输入或输出重定向,任意一个都可以分配给文件并用在脚本中
- 使用 exec 将替代性文件描述符指向文件,此重定向就会一直有效,直至重新分配
- 恢复已重定向的文件描述符,你可以将另一个文件描述符分配给标准文件描述符
- 可以打开单个文件描述符兼做输入和输出,这样就能用同一个文件描述符对文件进行读和写两种操作,任何读或写都会从文件指针上次的位置开始
-
关闭文件描述符
- 如果创建了新的输入文件描述符或输出文件描述符,那么 shell 会在脚本退出时自动将其关闭
- 手动关闭文件描述符,只需将其重定向到特殊符号
&- - 一旦关闭了文件描述符,就不能在脚本中向其写入任何数据,否则 shell 会发出错误消息
-
lsof: 会列出整个 Linux 系统打开的所有文件描述符
- -p 允许指定 PID
- -d 允许指定要显示的文件描述符编号
- -a 可用于对另外两个选项的结果执行 AND 运算
-
抑制命令输出
- 重定向到一个名为 null 文件的特殊文件
- 输出到 null 文件的任何数据都不会被保存,全部会被丢弃
- null文件的标准位置是
/dev/null - 输入重定向中将 /dev/null,实现快速清除现有文件中的数据
-
使用临时文件
-
Linux 系统有一个专供临时文件使用的 特殊目录
/tmp -
大多数 Linux 发行版配置系统在启动时会自动删除 /tmp 目录的所有文件
-
系统中的任何用户都有权限读写 /tmp 目录中的文件
-
mktemp: 专门用于创建临时文件
- 所创建的临时文件不使用默认的 umask 值
- 作为临时文件属主,你拥有该文件的读写权限,但其他用户无法访问
- 使用方法只需指定一个文件名模板即可,同时在文件名末尾要加上 6 个 X
- 命令会任意地将 6 个 X 替换为同等数量的字符,以保证文件名在目录中是唯一的
- 命令的输出正是它所创建的文件名,方便在脚本中使用
-t选项会强制在系统的临时目录中创建文件,返回所创建的临时文件的完整路径名-d选项会创建一个临时目录
-
-
记录消息
-
tee
-
就像是连接管道的 T 型接头,它能将来自 STDIN 的数据同时送往两处
- STDOUT
- 命令行所指定的文件名
-
默认情况下,会在每次使用时覆盖指定文件的原先内容
-
-a选项: 将数据追加到指定文件中
-
-
脚本控制
-
处理信号
-
Linux 系统和应用程序可以产生超过 30 个信号,信号与值在不同版本可能会存在差异,可以通过
kill的-l选项查看 -
bash shell 会忽略收到的任何 SIGQUIT 信号和 SIGTERM 信号,保障交互式 shell 不会被意外终止
- SIGQUIT 信号 3: 停止进程
- SIGTERM 信号 15: 尽可能的终止进程,不一定成功比较温和
-
bash shell 会处理收到的所有 SIGHUP 信号和 SIGINT 信号
- SIGHUP 信号 1: 挂起进程
- SIGINT 信号 2: 中断进程,Linux 内核将不再为 shell 分配 CPU 处理时间
-
产生信号: bash shell 允许使用键盘上的组合键来生成两种基本的 Linux 信号
-
Ctrl+C 组合键会生成 SIGINT 信号
-
Ctrl+Z 组合键会生成 SIGTSTP 信号
- SIGTSTP 信号 20: 停止 shell 中运行的任何进程,还能从上次停止的位置继续运行,可以使用 kill 发送信息 SIGKILL 信号或 SIGCONT 信号进行控制
- SIGKILL 信号 9: 强制终止进程
- SIGCONT 信号 18: 在 SIGSTOP, SIGTSTP 后恢复
- 用 ps 命令可以查看已停止的进程,在 S 列停止状态显示为 T
-
-
捕获信号
trap命令可以指定 shell 脚本需要侦测并拦截的 Linux 信号trap commands signals-
commands 部分列出想要与信号绑定的行为,如果是
--会恢复信号的默认行为 -
signals 部分列出想要捕获的信号,多个信号之间以空格分隔,可以使用信号的值或信号名
-
为了保证脚本中的关键操作不被打断,请使用带有空操作命令的 trap 以及要捕获的信号列表
-
要捕获 shell 脚本的退出,只需在 trap 命令后加上 EXIT 信号,提前退出脚本依然能捕获
-
-
-
后台模式运行
- 在后台模式中,进程运行时不和终端会话的 STDIN, STDOUT, STDERR 关联
- 脚本在后台运行,不占用终端会话
- 后台模式运行shell脚本只需在脚本名后面加上
& - 当后台进程运行时仍然会使用 终端显示器 来显示 STDOUT 和 STDERR 消息,最好是进行重定向避免这种杂乱的输出
-
在非控制台下运行脚本
-
即便退出了终端会话,也在终端会话让脚本一直以后台模式运行到结束
-
nohup: 能阻断发给特定进程的 SIGHUP 信号,当退出终端会话时可以避免进程退出
- 命令会解除终端与进程之间的关联,因此进程不再同 STDOUT 和 STDERR 绑定在一起
- 命令会自动将 STDOUT 和 STDERR 产生的消息重定向到一个名为
nohup.out的文件中 - nohup.out 文件一般在 当前工作目录 中创建,否则会在 $HOME 目录 中创建
- 运行了另一个命令,那么该命令的输出会被追加到已有的 nohup.out 文件中
-
-
作业控制: 包括启动、停止、终止、恢复
-
jobs: 作业控制命令
-
命令输出中的加号和减号
- 带有加号的作业为默认作业,如果作业控制命令没有指定作业号,则引用的就是该作业
- 带有减号的作业会在默认作业结束之后成为下一个默认作业
- 带加号的作业只能有一个,带减号的作业也只能有一个
-
-l选项: 查看作业的 PID
-
-
删除已停止的作业,那么使用 kill 命令向其 PID 发送 SIGKILL 信号即可
-
bg: 以后台模式重启作业,存在多个作业需要在后加上作业号
-
fg: 以前台模式重启作业
-
-
调整谦让度
-
调度优先级是指内核为进程分配的 CPU 时间
-
shell 启动的所有进程的调度优先级默认都是相同的
-
调度优先级是一个整数值,取值范围从-20(最高优先级)到+19(最低优先级)
-
在默认情况下,bash shell 以优先级 0 来启动所有进程
-
nice: 允许在启动命令时设置其调度优先级
- 命令会阻止普通用户提高命令的优先级,只有 root 用户或者特权用户才能提高作业的优先级
-
renice: 指定已运行进程的 PID 来改变其优先级
- 只能对属主为自己的进程使用 renice 且只能降低调度优先级
- root 用户和特权用户可以使用任意进程的优先级做任意调整
-
定时运行作业
-
at: 允许指定Linux系统何时运行脚本
-
at 的守护进程 atd 在后台运行,在作业队列中检查待运行的作业
-
atd 守护进程会检查系统的一个特殊目录,通常位于 /var/spool/at 或 /var/spool/cron/atjobs
-
默认情况下,atd 守护进程每隔 60 秒检查一次这个目录
-
在默认情况下,命令会将 STDIN 的输入放入队列
-
-f选项: 指定用于从中读取命令 -
命令能识别多种时间格式,具体参见 /usr/share/doc/at/timespec 文件
-
使用命令时,该作业会被提交至 作业队列,针对不同优先级有 52 种作业队列
- 作业队列的字母排序越高,此队列中的作业运行优先级就越低
- 默认情况下,提交的作业会被放入 a 队列
-
-q选项: 指定其他的队列 -
任何送往 STDOUT 或 STDERR 的输出都会通过 邮件系统 传给该用户,最好在脚本中进行重定向
-
-M选项: 以禁止作业产生的输出信息
-
-
atq: 可以查看系统中有哪些作业在等待
-
atrm: 删除等待中的作业,指定要删除的作业号即可
-
cron: 程序调度需要定期执行的作业,相比 at 具有周期性
- 在后台运行,并会检查一个特殊的表(时间表),从中获知已安排执行的作业
- 时间表格式:
minutepasthour hourofday dayofmonth month dayofweek command - 时间表允许使用特定值、取值范围或者通配符来指定各个字段
- 命令列表必须指定要运行的命令或脚本的完整路径
- 会以提交作业的用户身份运行该脚本,因此你必须有访问该脚本以及输出文件的合理权限
- 每个用户都可以使用自己的 cron 时间表运行已安排好的任务
- 在默认情况下,用户的 cron 时间表文件并不存在
-
anacron: 弥补 Linux 系统处于关闭状态时,cron 程序不会再去运行那些错过的作业
- anacron 判断出某个作业错过了设置的运行时间,它会尽快运行该作业
- 只处理位于 cron 目录的程序
- 它通过时间戳来判断作业是否在正确的计划间隔内运行了,每个 cron 目录都有一个时间戳文件,该文件位于 /var/spool/anacron
- 命令使用自己的时间表(通常位于 /etc/anacrontab)来检查作业目录
anacron 时间表的基本格式:
period delay identifier command- period: 定义了作业的运行频率,单位 day
- delay: 指定了在系统启动后 anacron 程序需要等待多少分钟再开始运行错过的脚本
- 不会运行位于 /etc/cron.hourly 目录的脚本,因为命令不处理执行时间需求少于一天的脚本
- identifier: 是一个独特的非空字符串,作用是标识出现在日志消息和错误 email 中的作业
- command: 包含了 run-parts 程序和一个 cron 脚本目录名
-
启动 shell 时运行脚本
-
应该将需要在登录时运行的脚本放在 $HOME/.bash_profile
-
如果需要某个脚本在两个时刻都运行可以将其放入
.bashrc- 一次是当用户登录 bash shell 时
- 另一次是当用户启动 bash shell 时
-
-
source: 这是另一种运行 bash 脚本的方法,称为 源引
shell 函数
-
bash shell 提供的用户自定义函数功能
-
创建函数
-
使用关键字 function
function name{ commands }- 函数名称唯一,脚本中的函数名不能重复
- 如果定义了同名函数,那么新定义就会覆盖函数原先的定义
-
bash shell 脚本中定义函数的方式创建函数
name(){ commands }- 函数名后的空括号表明正在定义的是一个函数,这种语法的命名规则和第一种语法一样
-
-
调用函数
-
只需像其他 shell 命令一样写出函数名
-
函数可以视为一个小型脚本,运行结束时会返回一个退出状态码
-
函数的退出状态码是函数中最后一个命令返回的退出状态码
-
$?可以确定函数的退出状态码,提取函数返回值之前执行了其他命令,那么函数的返回值会丢失 -
return: 以特定的退出状态码退出函数
- 函数执行一结束就立刻读取返回值
- 退出状态码必须介于 0~255
-
-
可以将命令的输出保存到 shell 变量中一样,也可以将函数的 STDOUT 输出保存到 shell 变量中
-
函数可以使用 标准的位置变量 来表示在命令行中传给函数的任何参数
-
$0变量保存函数名 -
函数参数依次保存在
$1,$2等变量中 -
$#可以确定传给函数的参数数量 -
要在函数中使用脚本的命令行参数,必须在调用函数时手动将其传入
-
向函数传递数组
- 试图将数组变量作为函数参数进行传递,则函数只会提取数组变量的第一个元素
- 须先将数组变量拆解成多个数组元素,然后将这些数组元素作为函数参数传递,返回数组变量也采用类似的方法
-
-
-
变量的作用域
-
全局变量
- 在 shell 脚本内任何地方都有效的变量
- 默认情况下,在脚本中定义的任何变量都是全局变量
- 在函数外定义的变量可在函数内正常访问
-
局部变量
- 无须在函数中使用全局变量,任何在函数内部使用的变量都可以被声明为局部变量
- 变量声明之前加上
local关键字即可,保证了变量仅在该函数中有效,可以轻松地将函数变量和脚本变量分离开
-
-
函数递归
- 函数可以调用自己来得到结果
- 通过递归对复杂的方程进行逐级规约,直到基准值
-
创建库
- bash shell 允许创建函数库文件,然后在多个脚本中引用此库文件
- source: 会在当前shell的上下文中执行命令,而不是创建新的shell并在其中执行命令,这样脚本就可以使用库中的函数
- source命令有个别名,称作 点号操作符
. - 在 .bashrc 文件中定义函数,可长期在命令行复用函数,只需将函数放在文件末尾即可,也可以源引库文件
- GNU shtool shell 脚本函数库,提供了一些简单的 shell 脚本函数,可用于实现日常的 shell 功能
shell 脚本高级技巧
sed & gawk
-
sed 编辑器
-
被称作 流编辑器,根据事先设计好的一组规则编辑数据流
-
可以执行下列操作
- 从输入中读取 一行 数据
- 根据所提供的编辑器命令 匹配数据
- 按照命令 修改 数据流中的数据
- 将新的数据输出到 STDOUT,编辑器并不会修改文本文件的数据
-
在流编辑器匹配并针对一行数据执行所有命令之后,会重复这个过程直到处理完数据流后结束运行
-
命令的格式
sed options script file-
options
-
-e选项额外 sed 命令,执行多个命令- 两个命令都应用于文件的每一行数据,命令之间必须以 分号 分隔
- 命令末尾和分号之间不能出现 空格
-
-f选项在单独的文件中指定 sed 命令,目的是大量要执行时使用- 指定文件中一条命令应于文件每一行
.sed作为 sed 脚本文件的扩展名,便于识别
-
-n选项会抑制 sed 编辑器的输出
-
-
script: 指定了应用于流数据中的单个命令
-
-
默认情况下,会将指定的命令应用于 STDIN 输入流中,可以直接将数据通过管道传入
-
sed 命令
-
替换命令 s:
[address]s/替换目标/替换内容/flags替换标识
- 数字: 指明新文本将替换行中的 第几处匹配
- g: 指明新文本将替换行中 所有的匹配
- p: 指明打印出替换后的行
- w file: 将替换的结果写入文件
- sed 编辑器允许选择其他字符作为替换命令的替代分隔符,
/不是绝对的
行寻址 address
-
数字模式
n: 表示特定行,$ 标识符表示最后一行n,m: 表示 n 行到 m 行的范围
-
正则表达式模式
/pattern/command: pattern 匹配表达式
-
可以对特定地址的多个命令分组
address { sed commands }
-
删除命令 d: 后面通常不接任何
[address]d -
插入命令 i: 会在指定行前增加一行,每行新文本末尾使用反斜线
\[address]i\ strings\ ...\ strings -
附加命令 a: 会在指定行后增加一行,每行新文本末尾使用反斜线
\[address]a\ strings\ ...\ strings -
取代命令 c: 修改行,将范围内取代内容,它跟插入和附加命令的工作机制一样
[address]c\ strings\ ...\ strings -
转换命令 y: 唯一可以处理单个字符,inchars 和 outchars 进行一对一的映射
[address]y/inchars/outchars -
写入命令 w: 向文件写入行
[address]w filename -
读取命令 w: 将一条独立文件中的数据插入数据流
[address]r filename -
命令 F: 告知 sed 打印出当前正在处理的文件名
[address]F
所以命令相同部分
[address]command -
-
打印
p命令: 打印文本行=命令: 打印行号l命令: 可以打印数据流中的文本和不可打印字符,行尾的美元符号表示换行符,
-
-
gawk 编辑器
-
相比 sed 增加了一种编程语言,而不仅仅是编辑器命令
- 定义变量 来保存数据
- 使用算术和字符串 运算符 来处理数据
- 使用 结构化编程概念 为数据处理添加处理逻辑
- 提取文件中的数据将其 重新排列组合,最后生成 格式化 报告
-
命令的格式
gawk options program file-
options
- -F 指定行中分隔符
- -f 从脚本文件中读取 gawk 命令,gawk 脚本建议以
.gawk为后缀 - -v 定义变量
- -L 指定兼容模式或警告级别
-
program: gawk 脚本
-
file: 处理数据,没有会从 STDIN 接收数据
-
-
gawk 脚本用一对花括号来定义
- print: 会将文本打印到 STDOUT
- STDIN 接入数据,会会反复直到 EOF 字符为止,EOF 字符表示文件末尾
- Ctrl+D 组合键可以生成 EOF 字符
-
特性之一是会自动为每一行的各个数据元素分配一个变量
- $0 代表整个文本行
- $1 代表文本行中的第一个数据字段,其中 $2, $3, ..., $n 以此内推
- 文本行中的 数据字段 是通过 字段分隔符 来划分的
- 默认情况下,字段分隔符是任意的 空白字符
-
BEGIN: 会强制 gawk 在读取数据前执行 BEGIN 关键字之后指定的脚本
-
END: 允许指定一段脚本在 gawk 处理完数据后执行这段脚本
-
特殊变量 FS: 这是定义字段分隔符的另一种方法
-
-
sed, gawk 职能
- sed 更适合编辑匹配到的文本
- gawk 更适合格式化文本,对文本进行较复杂格式处理
正则表达式
-
正则表达式是由正则表达式引擎实现的,最流行的是以下两种
- POSIX基础正则表达式 BRE 引擎,大多数 Linux 工具至少符合 POSIX BRE 引擎规范
- POSIX扩展正则表达式 ERE 引擎,提供了高级模式符号和特殊符号
-
特殊字符
-
BRE 基础 basic
-
\转义字符 -
锚点字符
^行首$行尾
-
.可以匹配除换行符之外的任意单个字符 -
[]字符组,如果字符组中的某个字符出现在了数据流中,那就能匹配该模式 -
[^]排除型字符组,匹配字符组中没有的字符- 区间,比如
0-9a-zA-Z等范围化
- 区间,比如
-
特殊的字符组
[[:BRE:]]其中的 BRE 允许下列词- alnum: 任意字母或数字字符
- alpha: 任意字母字符
- digit: 0~9 的数字
- lower: 小写字母
- upper: 大写字母
- print: 可打印字符
- punct: 标点符号
- space: 任意空白符
- blank: 空格或制表符
-
*表明该字符必须在匹配模式的文本中出现 0~n 次
-
-
ERE 拓展 extended
-
?表明前面的字符可以出现 0~1 次 -
+表明前面的字符可以出现 1~n 次 -
{}允许为正则表达式指定具体的可重复次数{n}恰好出现 n 次{n,m}恰好出现 n~m 次
-
|以或运算进行匹配 -
()表达式分组,每一组会被视为一个整体
-
-
了解图形化 shell 编程
-
创建文本菜单
-
传统思路
- clear: 清除使用终端会话的终端设置信息
- echo 命令使用
-e选项,可以打印非可打印字符 - read 获取用户输入
-
select: 能够帮助我们自动完成这些工作
select variable in list do commands done- list: 是由空格分隔的菜单项列表,该列表构成了整个菜单
- 命令会将每个列表项显示成一个带编号的菜单项
- PS3 环境变量 定义的特殊提示符,指示用户做出选择
- 字符串才是要在 case 语句中进行比较的内容,而不是跟菜单选项相关联的数字
-
-
创建文本窗口部件
-
dialog 软件包: 能够用 ANSI 转义控制字符,在文本环境中创建标准的窗口对话框
-
使用命令行选项来决定生成哪种窗口部件
-
要在命令行中指定某个特定部件,需要使用双连字符格式
-
每个dialog部件都提供了两种输出形式
- 使用 STDERR,部件返回了数据会将数据发送给 STDERR
- 使用退出状态码
- $? 变量可以确定用户选择了 dialog 部件中的哪个按钮
-
-
-
图形化窗口部件
- kdialog 软件包为 KDE 桌面提供了图形化窗口部件
- zenity 软件包为 GNOME 桌面提供了图形化窗口部件