Python语法
0.Pycharm文件模板
# _*_ coding : UTF-8 _*_
# @Time : ${DATE} ${TIME}
# @Author : LinFeng
# @File : ${NAME}
# @Project : ${PROJECT_NAME}
1.注释
单行 #
多行 ''' '''
2.变量
2.1 变量类型
-
number
- int(
long) - float(
double) - complex
- int(
-
boolean
- True
- False
-
string(
char) -
list(列表)数组?
[]
-
tuple(元组)
()
- dict(字典) 结构体?
{key:value}
2.2 查看变量类型
type()
2.3 命名规范
大小驼峰+下划线命名法
2.4 类型转换
- int()
- float()
- bool()
- str()
3.运算符
3.1 运算符类型
加减乘除 +-*/
整数除 //
取余 %
指数 **
多变量赋值 d,e,f = 1,2,3
逻辑运算符 and与(&&)or或(||)
4.输入输出
4.1 输出
%s 字符串%d 整数
格式化输出
print('我的名字是%s,我的年龄是%d' % (name,age))
4.2 输入
vaule = input('请输入xxx:')
5.流程控制
5.1 if
不要漏:
if value > 18:
print('xxxx')
elif value >30:
print("aaaaa")
else:
print('ddd')
5.2 for
for i in range(5) # 0-4
for i in range(5,10) # 左闭右开,5-9
for i in range(5,10,3) # (起始,结束,步长)
6.字符串操作
- 获取长度:len
- 查找:find
- 判断:startswith,endswith
- 出现次数:count
- 替换内容:replace
- 切割字符串:split
- 修改大小写:upper,lower
- 去空格:strip
- 拼接:join
7.列表操作
7.1 添加
- append(object) 追加
- insert(index, object) 插入(注意index值为插入值的下标)
- extend (Iterable迭代)似乎没什么用?
7.2 修改
通过下标[]=
7.3 查找
- in
if food in foodList:
print("ssss")
else :
print("3333")
- not in
if food not in foodList:
print("ssss")
else :
print("3333")
7.4 删除
- del 根据下标来删除
del a_list[3]
- pop() 删除最后一个元素
a_list.pop()
- remove() 根据值删除
a_list.remove("ffff")
8.元组操作
- 元组元素不可以被修改!!!!
- 只有一个元素的元组需要在唯一的元素后面写,
9.切片
-
语法
注意!!!仍然是左闭右开区间
- [起始:结束]
- [起始:结束:步长]
- [起始:]
- [:结束]
10.字典操作
10.1 定义&访问
person = {'name':'李治','score':100000000000000}
# 访问
print(person['name'])
print(person['score'])
#######################
# print(person.score) 寄,达咩
#######################
## but
print(person.get('score')) #ojbk
#######################
# 关于报错
print(person['sex']) # keyerror
print(person.get('sex')) # None
10.2 修改
person['name'] = '法外狂徒'
10.3 添加
同修改,如果存在就修改,不存在就添加
person['name'] = '法外狂徒'
person['sex'] = 'We do not kown'
10.4 删除
- del
del person['name'] # 删除key
del person # 删除字典对象
- clear
person.clear() # 清空对象key,保留字典结构
10.5 遍历
# 1.遍历key
for key in person.keys():
print(key)
# 2.遍历value
for value in person.values():
print(value)
# 3.遍历key&&value
for key,value in person.items():
print(key,value)
# 4.遍历项,每个项实际上是元组
for item in person.items():
print(item)
11.函数
# 语法
def <函数名>(参数表):
print("李治牛逼!!!!!!")
print("李治我大哥!!!!!!")
return <值>
################################
# 传参
def sum(a,b)
# 1.位置传参
sum(11,55)
# 2.关键字传参
sum(b=11,a=55)
12.文件
12.1 打开&关闭
####### 打开 #######
fp = open('text.txt','w)
####### 写 #######
fp.write('hello\n'*3)
####### 读 #######
# 读一字节
content = fp.read()
# 读一行
content = fp.readline()
# 读完,以行分界组成列表
content = fp。readlines()
####### 关闭 #######
fp.close()
-
文件路径
-
绝对路径
-
相对路径
text.txt当前文件夹./text.txt当前文件夹../text.txt上一级文件夹demo/text.txtdemo文件夹
-
-
打开模式
模式 可做操作 若文件不存在 是否覆盖文件原来内容 r 只读 报错 —— r+ 可读、可写 报错 是 w 只写 创建 是 w+ 可读、可写 创建 是 a 只写 创建 否,追加写 a+ 可读、可写 创建 否,追加写
12.2 序列化与反序列化
-
定义
-
序列化:对象->字节序列
-
反序列化:字节序列->对象
使用JSON模块实现
-
-
序列化
import json
fp = open('text.txt','w')
name_list = ['zs','lz']
# dumps()
names = json.dumps(name_list)
fp.write(names)
# dump()
json.dump(name_list,fp)
fp.close()
反序列化
import json
fp = open('text.txt','r')
# loads()
content = fp.read()
result = json.loads(content)
# load()
result = json.load(fp)
不加s的都????
13.异常
try:
fp = oprn('text.txt','r')
fp.read()
except FileNotFoundError:
print('世界毁灭了!!!!!!')
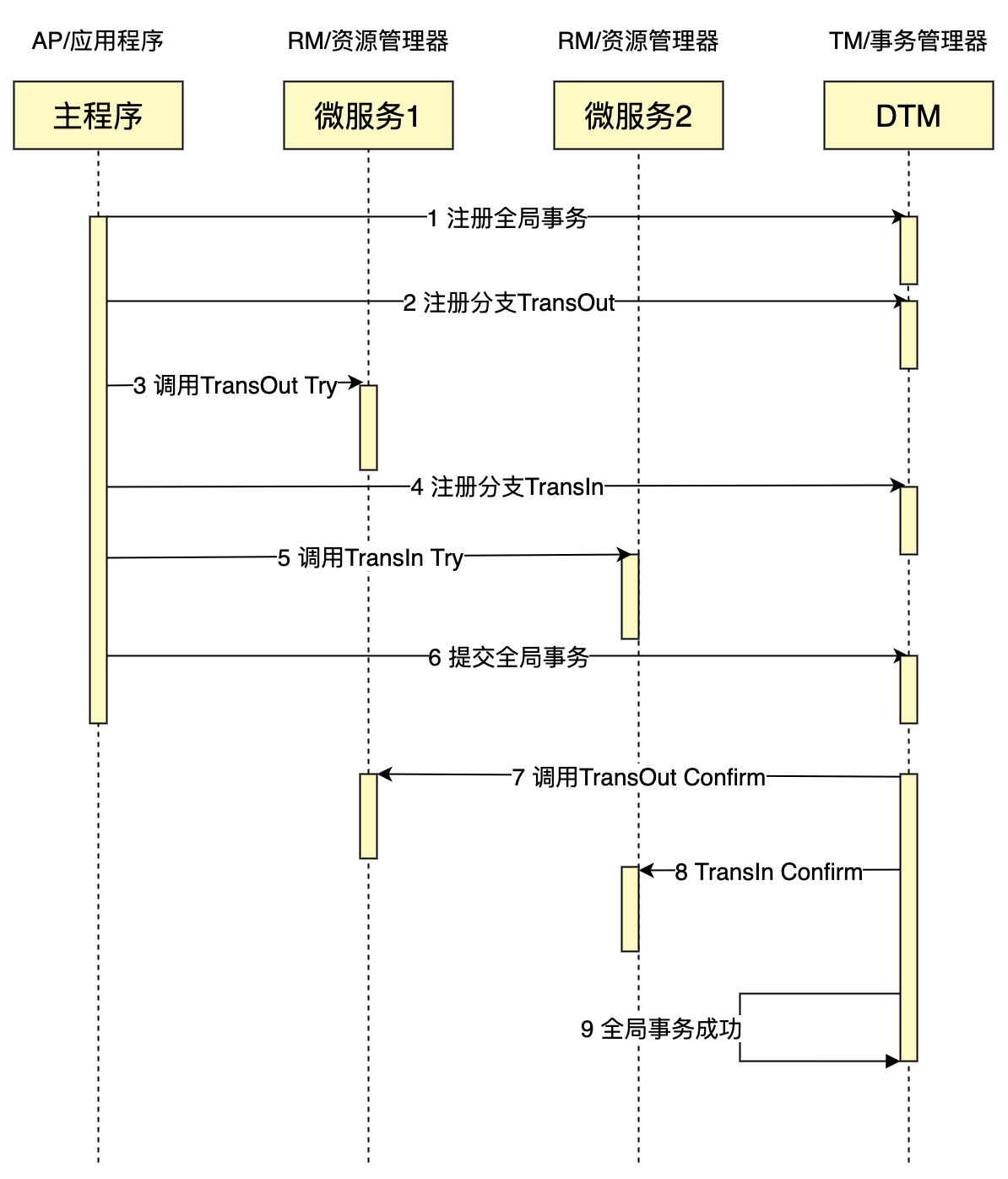
HTML页面结构
<!--
table 表格
tr 行
td 列
ul li 无序列表
ol li 有序列表
a 超链接
-->
爬虫
0.防爬手段
- User-Agent(用户代理)
- 代理IP
- 西次代理
- 快代理
- 透明代理:代理+真实IP
- 匿名代理:代理
- 高匿名代理:无
- 验证码
- 打码平台
- 云打码平台
- 超级✈
- 动态加载网页(返回的是js数据并非真实数据)
- selenium驱动浏览器发送请求
- 数据加密
- 分析js代码
1.urllib
1.1 基本用法&get方法
# _*_ coding : UTF-8 _*_
# @Time : 2023/2/28 18:56
# @Author : LinFeng
# @File : learn_urllib_base_01
# @Project : LearnSpider
import urllib.request
url = 'http://www.baidu.com'
# 发送请求
response = urllib.request.urlopen(url)
# response是HTTPResponse类型
print(type(response))
# 获取响应中的页面源码
# 因为read()方法获取的是字节编码的页面源码
# 故需要使用decode()方法进行解码
content = response.read().decode('utf-8') # 按字节读
content = response.readline() # 读一行
content = response.readlines() # 按行读,每行组成列表
print(content)
# 返回状态码,200就对了!!
print(response.getcode())
# 返回url地址
print(response.geturl())
# 获取状态信息
print(response.getheaders())
1.2 下载_urlretrieve()方法
# _*_ coding : UTF-8 _*_
# @Time : 2023/2/28 19:17
# @Author : LinFeng
# @File : learn_urllib_download_02
# @Project : LearnSpider
import urllib.request
# 下载网页源码
url_page = 'http://www.baidu.com'
urllib.request.urlretrieve(url_page, 'baidu.html')
# 下载图片
url_img = 'https://pic2.zhimg.com/v2-a808ed8dd58234857734fcf3925b867d_250x0.jpg?source=172ae18b'
urllib.request.urlretrieve(url_img, '爬虫.jpg')
# 下载视频 现在好多防爬的视频网站啦,看看就好
# url_video = 'https://haokan.baidu.com/v?pd=wisenatural&vid=2126907687398950584'
# urllib.request.urlretrieve(url_video, 'shitVideo.mp4')