方法签名
方法签名包括方法名称和参数列表,是JVM标识方法的唯一索引,不包括返回值,更加不包括访问权限控制符、异常类型等。假如返回值可以是方法签名的一部分,仅仅从代码可读性角度来考虑,如下示例:
long f() {
return 1L;
}
double f() {
return 1.0d;
}
var a = f();
那么类型推断的var到底是接受1.0d还是1L?从静态阅读的角度,根本无从知道它调用的是哪个方法。
参数
在高中数学中计算函数f(x,y) = 2x+2y-3,将x=3,y=7代入公式得到6+14-3=17,这里f(x,y)的x与y就是形式参数,简称形参;而3与7是实际参数,简称实参。参数是自变量,而f(x,y)函数,即代码中的方法是因变量,是一个逻辑执行的结果。参数又叫parameter,在代码注释中@param表示参数类型。参数在方法中,属于方法签名的一部分,包括参数类型和参数个数,多个参数用逗号相隔,在代码风格中,约定每个逗号后必须要有一个空格,不管是形参,还是实参。形参是在方法定义阶段,而实参是在方法调用阶段,先来看看实参传递形参的过程:
public class ParamPassing {
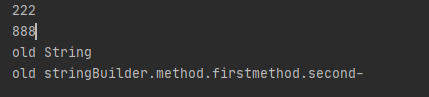
private static int intStatic = 222;
private static String stringStatic = "old String";
private static StringBuilder stringBuilderStatic = new StringBuilder("old stringBuilder");
public static void main(String[] args) {
// 实参调用
method(intStatic);
method(stringStatic);
method(stringBuilderStatic,stringBuilderStatic);
// 输出依然是222(第一处)
System.out.println(intStatic);
method();
// 无参方法调用之后,反而修改为888 (第二处)
System.out.println(intStatic);
// 输出依然是:old string
System.out.println(stringStatic);
// 输出结果参考下方分析
System.out.println(stringBuilderStatic);
}
// A方法
public static void method(int intStatic) {
intStatic = 777;
}
// B方法
public static void method() {
intStatic = 888;
}
// C方法
public static void method(String stringStatic) {
// String是immutable对象,String没有提供任何方法用于修改对象
stringStatic = "new String";
}
// D方法
public static void method(StringBuilder stringBuilderStatic1,StringBuilder stringBuilderStatic2) {
// 直接使用参数引用修改对象 (第三处)
stringBuilderStatic1.append(".method.first");
stringBuilderStatic2.append("method.second-");
// 引用重用赋值
stringBuilderStatic1 = new StringBuilder("new stringBuilder");
stringBuilderStatic1.append("new method's append") ;
}
}
如果不了解形参与实参的传递方法,对于第一处和第二处是存在疑问的。第一处通过有参方法执行intStatic=777,居然没有修改成功,而使用无参的menthod方法却成功地把静态变量intStatic的值修改为888。如图所示:
有参的A方法如上图所示,参数是局部变量,拷贝静态变量的777,并存入虚拟机栈中的局部变量表的第一个小格子内。虽然在方法内部的intStatic与静态变量同名,但是因为作用域就近原则,它是局部变量的参数,所有的操作与静态变量是无关的。而无参的B方法如上图所示,先把本地赋值的888压入虚拟机栈中的操作栈,然后给静态变量intStatic赋值。有两个参数的D方法中,我们在分析第三处StringBuilder疑问:
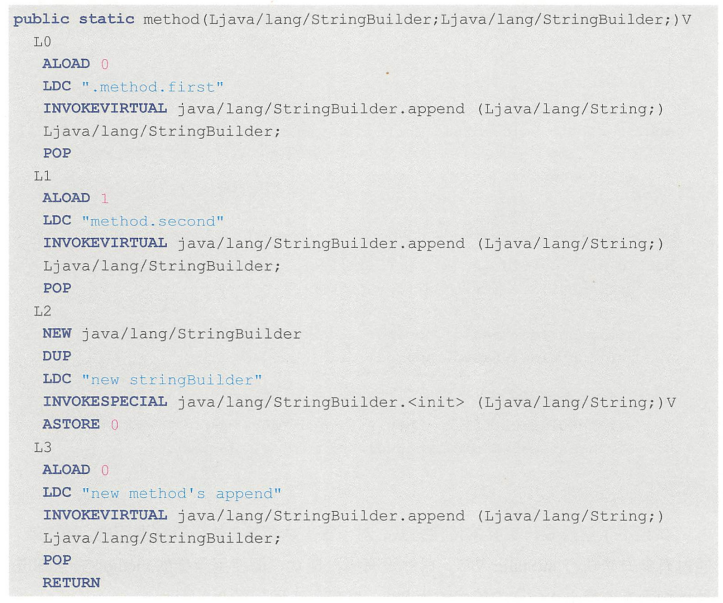
注意上述字节码中的两个ALOAD 0,是把静态变量的引用赋值给虚拟机栈的栈帧中的局部变量,然后ALOAD操作是把两个引用变量压入操作栈的栈顶。注意,这两个引用都指向了静态引用变量的new StringBuildStatic("old stringBuilder")对象在method(stringBuilderStatic,stringBuilderStatic)的执行结果后的值,其结果:
old stringBuilder.method.firstmethod.second-
在D方法中,new出来一个新的StringBuilder对象,赋值给stringBuilderStatic1。注意,这是一个新的局部引用了变量,使用ASTORE命名对局部变量表的第一个位置的引用变量值进行了赋值,然后再重新进行ALOAD到操作栈顶,所以后续对应stringBuilderStatic1的append操作,与类的静态引用变量stringBuilderStatic没有任何关系。
综上所述,无论是对于基本数据类型,还是引用变量,JAVA中的参数传递都是值复制的传递过程。对于引用变量,复制指向对象的首地址,双方都可以通过自己的引用变量修改了对象的相关属性。
再来介绍一种特殊的参数——可变参数。它是在JDK5版本中引入的,主要为了解决当时的反射机制和printf方法问题,适用于不确定参数个数的场景。可变参数通过“参数类型...”的方式定义,如PrintStream类中printf方法使用了可变参数:
public PrintStream printf(String format,Object ...args) {
return format(format,args);
}
// 调用printf方法示例
System.out.printf("%d",n); (第一处)
System.out.printf("%d %s",n,"something") (第二处)
如上图示例代码,虽然第一处调用传入了两个参数,第二处调用传入了三个参数,但它们调用的都是prinf(String format,Object ...args)方法。看上去可变参数使方法调用更简单,省去了手工创建数组的麻烦。有人说可变参数是语法糖,个人觉得是恶魔的果实。如果在实际开发中使用不当,会严重影响代码的可读性和可维护性。因此,使用时要小心谨慎,尽量不要使用可变参数编程。如果一定要使用,则只有相同参数类型,相同业务含义的参数才可以,并且一个方法中只能有一个可变参数,且这个可变参数必须是该方法的最后一个参数。此外,建议不要使用Object作为可变参数,如下警示代码:
public static void listUsers(Object ...args) {
System.out.println(args.length);
}
public static void main(String[] args){
// 以下代码输出结果是:3
listUsers(1,2,3);
// 以下代码输出结果是:1
listUses(new int[]{1,2,3});
// 以下代码输出结果是:2 (第一处)
listUsers(3,new String[]{"1","2"});
// 以下代码输出结果是3 (第二处)
listUsers(new Integer[]{1,2,3});
// 以下代码输出结果是2 (第三处)
listUsers(3,new Integer[]{1,2,3});
}
通过上面例子可以看到,使用Object作为可变参数时过于灵活,类型转换场景不好预判,比如第二处和第三处中Integer[]可以转型为Object[],也可以作为一个Object对象,所以导致第二处输出结果为3,第三处输出结果为2。而int[]只能被当作一个淡出的Object对象。同事Object又很容易破坏"可变参数具备相同类型,相同业务含义"这个大前提,如上例中第一处的整型和字符串类型混用,因此要避免使用Object作为Object可变参数。
以上是参数定义的相关内容,那么如何正确地使用参数呢?方法定义方并不能保证调用方会按照预期传入参数,因此在方法体中应该对传入的参数保持理性的不信任。方法的第一步骤并不是功能实现,而应该是参数预处理。参数预处理包括两种:
(1)入参保护。 虽然"入参保护"被提及的频率和认知度远低于参数校验,但是其重要性却不能被忽略。入参保护实际上是对服务提供方的保护,常见于批量接口。虽然批量接口能处理一批数据,但其处理能力并不是无限的,因此需要对入参的数据量进行判断和控制,如果超出处理能力,可以直接返回错误给客户端。某业务曾发生过一个严重的故障,就是由一个用户批量查询接口导致。虽然在API文档中约定了每次最多支持查询的用户ID个数,但在接口实现中没有作任何入参保护,导致当调用方传入万级的用户ID集合查询信息时,服务器内存被塞满,再无任何处理能力。
(12)入参校验。 参数作为方法间交互和传递信息的媒介,其重要性不言而喻。基于防御式编程理念,在方法内,无论是对方法调用方传入参数的理性不信任,还是对参数有效值的检测都是非常有必要的。但是,由于方法间交互是非常频繁的,如果所有方法都进行参数校验,就好导致重复代码及不必要检查影响代码性能。综合两个方面的考虑,汇总需要进行参数校验和无须处理的场景。
需要进行参数校验的场景:
· 调用频度低的方法
· 执行时间开销很大的方法。此情形 中,参数校验时间几乎可以忽略不计,但如果因为参数错误导致中间执行回退或错误,则得不偿失。
· 需要极高稳定性和可用性的方法。
· 对外提供的开放接口。
· 敏感权限入口。
不需要进行参数校验的场景:
· 极有可能被循环调用的方法。但方法说明里必须注明外部参数检查。
· 底层调用频率较高的方法。参数错误 不太可能到底层才会暴露问题。一般DAO层与Service层都在同一个应用中,部署在同一台服务器中,所以可以省略DAO的参数校验。
· 声明成private只会被自己代码调用的方法。如果能够调用方法的代码传入参数已经做过检查或者肯定不会有问题,此时可以不校验参数。
构造方法
构造方法(Constructor)是方法名与类名相同的特殊方法,在新建对象时调用,可以通过不同的构造方法实现不同方式的对象初始化,它有如下特征:
(1) 构造方法名称必须与类名相同
(2) 构造方法是没有返回类型的,即使是void也不能有。它返回对象的地址,并赋值给引用变量。
(3) 构造方法不能被继承,不能被覆写,不能被直接调用。调用途径有三种:一是通过new关键字,二是在子类的构造方法中通过super调用父类的构造方法,三是通过反射方法获取并使用。
(4) 类定义时提供了默认的无参构造方法。但是如果显示定义了有参构造方法,则此无参构造方法就会被覆盖;如果依然想拥有,就需要进行显示定义。
(5) 构造方法可以私有。外部无法使用私有构造方法创建对象。
在接口中不能定义构造方法,在抽象类中可以定义。在枚举中,构造方法是特殊存在的,它可以定义,但不能加public修饰,因为默认是private的,是绝对单例,不允许外部以创建对象的方式生成枚举对象。
一个类可以有多个参数不同的构造方法,称为构造方法的重载。为了方便阅读,当一个类有多个构造方法时,这些方法应该被放置在一起。同理,类中的其他同名方法也应该遵循这个规则。
单一职责,对于构造方法同样适用,构造方法的使命就是在构造对象时进行传参操作,所以不应该在构造方法中引入业务逻辑。如果在一个对象生产中,需要完成初始化上下游对象、分配内存、执行静态方法、赋值句柄等繁重的工作,其中某个步骤出错,导致没有完成对象初始化,再将希望寄托于业务逻辑部分来处理异常就是一件不受控制的事情了。故推荐将初始化业务逻辑放在某个方法中,比如int(),当对象确认完成所有初始化工作后,再显示调用。
类中的Static{...}代码被称为类的静态代码块,在类初始化时执行,优先级很高。下面看一下父子类静态代码块和构造方法的执行顺序:
class Son extends Parent {
static {System.out.println("Son 静态代码块");}
Son() {System.out.println("Son 构造方法");}
public static void main(String[] args) {
new Son();
new Son();
}
}
class Parent {
static {System.out.println("Parent 静态代码块");}
public Parent() {
System.out.println("Parent 构造方法");
}
}
执行结果如下:
Parent 静态代码块
Son 静态代码块
Parent 构造方法
Son 构造方法
Parent 构造方法
Son 构造方法
从以上示例可以看出,在创建对象时,会先执行父类和子类的静态代码块,然后再执行父类和子类的构造方法。并不是执行完父类的静态代码块和构造方法后,再去执行子类。静态代码块只执行一次,在第二次对象实例化时,不会再执行。
类内方法
在面向过程的语言中,几乎所有的方法都是全局静态方法,在引入面向对象理念之后,某些方法才归属于具体对象,即类内方法。构造方法无论是有形、无形、私有、公有,在一个类中是必然存在的。除构造方法外,类中还可以有三类方法,实例方法、静态方法、静态代码块。
1.实例方法
又称为非静态方法。实例方法比较简单,它必须依附于某个实际对象,并可以通过引用变量调用方法。类内部各个实例方法之间可以互相调用,也可以直接读写类变量,但是不包括this。当.class字节码文件加载之后,实例方法并不会被分配方法入口地址,只有在对象创建只会才会被分配。实例方法可以调用静态变量和静态方法,当从外部创建对象后,应尽量使用"类名.静态方法"来调用,而不是对象名,一来为编译器减负,而来提升代码可读性。
2.静态方法
又称为类方法。当类加载后,即分配了相应的内存空间,由于生命周期的限制,使用静态方法需要注意两点:
(1)静态方法中不能使用实例成员变量和实例方法。
(2)静态方法不能使用super和this关键字,这两个关键字指代的都是需要被创建出来的对象
通常静态方法用于定义工具类的方法等,静态方法如果使用了可修改的对象,那么并发时会存在线程安全问题。所以,工具类的静态方法与单例通常是相伴而生的。
3.静态代码块
在代码的执行方法体中,非静态代码块和静态代码块比较特殊。非静态代码块又称为局部代码块,是及不推荐的方式。而静态代码块在类加载的时候调用,并且只执行一次。静态代码块是先于构造方法执行的特殊代码块。静态代码块不能存在于任何方法体内,包括类静态方法和属性变量。观察如下示例代码:
public class StaticCode {
// prior必须定义在last前边,否在编译出错:illegal forward reference
static String prior = "done";
// 依次调用f()的结果,三目运算符为true,执行g(),最后赋值成功
static String last = f() ? g() : prior;
public static boolen f() {
return true;
}
public static String g() {
return "hello world";
}
static {
// 静态代码块可以访问静态变量和静态方法
System.out.print(last);
g();
}
}
在上述代码中,由于last依赖了变量prior,所以两者之间存在先后关系,而静态方法与静态变量之间没有先后关系。在实际应用中例如容器初始化时,可以使用静态代码块实现加载判断、属性初始化、环境配置等。很多容器框架会在单例对象初始化成后调用默认init()方法,完成例如RPC注册中心服务器判断、应用通用底层数据初始化等工作。某框架的初始化代码如下所示:
public class RpcProviderBean {
public void init() throws RpcRuntimeException {
this.initRegister();
this.publish();
// 其他逻辑
}
public void initRegister() {
if(this.inited.compareAndSet(false,true)) {
this.checkConfig();
this.metadata.init();
}
}
public void publish (){
// 将本地服务信息发送到注册中心
}
}
getter与setter
在实例方法中有一类特殊的方法,即getter和setter方法,它们一般不包含任何业务逻辑,仅仅是为类成员属性提供读取和修改方法,这样设计有两点好处:
(1) 满足面向对象语言封装的特性。尽可能将类中的属性定义为private,针对属性值的访问与修改使用相应的getter与setter方法,而不是直接对public的属性读取和修改。
(2) 有利于统一控制。虽然直接对属性进行读取、修改的方式和使用相应的getter与setter方法在效果上是一样的,但是前者难以应对业务的变化。例如,业务要求对某个属性的修改要增加统一的权限控制,如果有setter作为统一的属性修改方法则更容易实现,这种情况在一些使用反射的框架中作用尤其明显。
因此,在类成员属性需要被外部访问的类中,getter与setter方法是必备。除特殊情况需要增加业务逻辑外,它们仅仅是对成员属性的访问和修改操作,其承载的信息价值比较低,所以建议在类定义中,类内方法定义顺序依次是:公有方法或保护方法>私有方法>getter/setter方法。
最典型的getter和setter方法使用是在POJO(简单的JAVA对象)类中。在本书中,POJO专指只包含getter、setter、toString方法简单的类,常见的POJO类包括DO(Domain Object)、BO(Business Object)、DTO(Data Transfer Object)、VO(View Object)、AO(Application Object)。POJO作为数据载体,通常用于数据传输,不应该包含任何业务逻辑。因此,在POJO类中,getter与setter不但是重要的组成部分,更是与外界进行信息交换的桥梁。getter与setter方法定义参考示例如下:
public class TicketDO {
private Long id;
// 目的地
private String destination;
// getter方法,要求:直接返回相应的属性值,不增加业务逻辑
public Long getId() {
return id;
}
public String getDestination() {
return destination;
}
// 参数名称与类成员名称一致,定义中的this.成员名=参数名,尽量不要增加业务逻辑
public void setId(Long id) {
this.id = id;
}
public void setDestination(String destination){
this.destination = destination;
}
}
getter与setter方法定义非常简单,正因为如此,工程师们会放松对他们的警惕,导致在实际应用中因为不当操作出现问题。下面来罗列那些易出错的getter与setter方法定义方式:
(1)getter/setter中添加业务逻辑。问题出现时,程序员的惯性思维会忽略getter/setter方法的嫌疑,这会增加排除问题的难度。如下示例代码,在getData()中增加逻辑判断,修改了原属性,如出现属性值
不一致的情况,这里可能会是程序员最后被排查到的地方。
public Integer getData() {
if(condition) {
return this.data + 100;
} else {
return this.data - 100;
}
}
(2)同时定义isXxx()和getXxx()。在类定义中,两者同时存在会在iBATIS、JSON序列化等场景下引起冲突。比如,iBATIS通过反射机制解析加载属性的getter方法时,首先会获取对象的所有的方法,然后刷选出以get和is开头的方法,并存储到类型为HashMap的getMethods变量中。其中key为属性名称,value为getter方法。因此isXxx()和setXxx()方法只能保留一个,哪个方法被后存储到getMethods变量中,就会保留哪个方法,具有一定的随机性。所以当两者定义不同时,会导致误用,进而产生问题。
(3)相同的属性名容易带来歧义。 在编程过程中,应该尽量避免在子类的成员变量之间、不同代码块的局部变量之间采用完全相同的命名。虽然这样的定义是合法的,但是要避免。这样使用非常容易引起混淆,在使用参数时,难以明确属性的作用域,最终难以分清到底是父类的属性还是子类的属性。扩展开来,对于非setter/getter的参数名称也要避免与成员变量名称相同。
public class ConfusingName {
public int alibaba;
// 反例:非setter/getter方法的参数名称,不允许与本类成员变量同名
public void get(string alibaba) {
if(true) {
final int taobo = 15;
...
}
for(int i=0;i<10;i++) {
// 在同一方法体中,不允许与其他代码块中的taobo命名相同
final int taobo = 15;
...
}
}
}
class Son extends ConfusingName {
// 反例:不允许与父类的成员变量名称相同
public int aliabab;
}
同步与异步
同步调用是刚性调用,是阻塞式操作,必须等待调用方法执行结束。而异步调用是柔性调用,是非阻塞式操作,在执行过程中,如调用其他方法,自己可以继续执行而不被阻塞等待方法调用完毕,异步调用通常在某些耗时长的操作上,这个耗时方法的返回结果,可以使用某种机制反向通知,或者再启动一个线程轮询。反向通知方式需要异步系统和各个调用它的系统进行耦合;而轮询对于没有执行完的任务会不断的请求,从而加大执行机器的压力。
异步处理的任务是非时间敏感的。比如,在连接池中,异步任务会定期回收空闲的线程。举个现实的例子,在代码管理平台中,提交代码的操作是同步调用,需要实时返回给用户结果。但是当前的代码相关活动记录不是时间敏感的,在提交代码时,发送一个消息到后台的缓存队列中,后台服务器定时消费这些消息即可。
某些框架提供了丰富的异步处理方式,或者是把同步任务拆解成多个异步任务等。
覆写
如果父类定义的方法达不到子类的期望,那么子类可以重新实现方法覆盖父类的实现。因为有些子类是延迟加载的,甚至是网络加载的,所以最终的实现需要在运行期判断,这就是所谓的动态绑定。动态绑定是多态的性得以实现的重要因素,元空间有一个方法表保存着每个可以实例化类的方法信息,JVM可以通过方法表快速地激活实例方法。如果某个类覆写了父类的某个方法,则方法表中的方法指向引用会指向子类的实现处。代码通常是用这样的方式调用子类的方法,通常也被称为向上转型:
Father father = new Son();
// Son覆写了此方法
father.doSomething();
向上转型时,通过父类引用执行子类方法时需要注意以下两点:
(1)无法调用到子类中存在而父类本身不存在的方法。
(2)可以调用到子类覆写了父类的方法,这是一种多态实现。
想成功地覆写父类的方法,需要满足以下4个条件:
(1)访问权限不能变小。访问控制权限变小意味着在调用时父类的可见方法无法被子类多态执行,比如父类中的方法是用public修饰的,子类父写时变成private。设想如果编译器为多态开了后门,让在父类定义中可见的方法随着父类调用链路下来,执行了子类更小的权限的方法,则破坏了封装。如下代码所示,在实际编码中不允许将方法访问权限缩小:
class Father {
public void method() {
System.out.println("Father's method");
}
}
class Son extends Father {
// 编译报错,不允许修改为访问更严格的修饰符
@overvide
private void method() {
System.out.println("Son's method");
}
}
(2)返回类型能够向上转型成为父类的返回类型。虽然方法返回值不是方法签名的一部分,但是在覆写时,父类的方法表指向了子类实现方法,编译器会检查返回值是否向上兼容。注意,这里的向上转型必须是严格的继承关系,数据类型基本不存在通过继承向上转型的问题。比如int与integer是非兼容返回类型,不会自动装箱。再比如,如果子类方法返回int,而父类返回long,虽然数据表范围更大,但是它们之间没有继承关系。返回类型是Object的方法,能够兼容任何对象,包括class、enum、interface等类型。
(3)异常也要能向上转型称为父类的异常。异常分为chekced和unchekced两种类型。如果父类抛出一个checked异常,则子类只能抛出此异常或此异常的子类。而unchecked异常不用显式地向上抛出,所有没有任何兼容问题。
(4)方法名、参数类型及个数必须严格一致。为了使编译器地判断是否是覆写行为,所有的覆写方法必须加@override注解。此时编译器会自动检查覆写方法签名是否一致,避免了覆写因写错方法名或方法参数而导致覆写失败。例如,AbstractCollection的clear方法,当覆写此方法时,成c1ear,注意是数字1,这会导致定义了两个不同的方法。此外,@override注解还可以避免因权限控制可见范围导致的覆写失败。如果2-7所示,Father和Son属于不同的包,它们的method()方法无权限控制符修饰,是默认的仅包内可见。Father的method方法在Son中是不可见的。所以Son中的定义的method方法时一个新方法,如果加上@override,则会提示:Method does not override method from its superclass。

综上所述,方法的覆写可以总结成容易的记忆的口诀:"一大两小两同"。
· 一大:子类的方法访问权限控制符只能相同或变大。
· 两小:抛出的异常和返回值只能变下,能够转型成父类的对象。子类的返回值、抛出异常类型必须与父类的返回值、抛出异常类型存在继承关系。
· 两同:方法名和参数必须完全相同
根据这个原则,再看一个编译和运行都正确的覆写示例代码:
class Father {
protected Number doSomething(int a,Integer b,Object c) throws SQLException{
System.out.println("Father's doSomething");
return new Integer(7);
}
class Son extends Father {
/**
* 1.权限扩大,由protected到public(一大)
* 2.返回值是父类Number的子类(两小)
* 3.抛出异常是SQLException的子类
* 4.方法名必须严格的一致(两同)
* 5.参数类型与参数个数必须严格一致
* 6.必须加@override
*/
public Integer doSomething(int a,Integer b,Object c) throws SQLException {
if(a == 0) {
throw new SQLClientInfoException();
}
return new Integer(17);
}
}
}
覆写只能针对非静态、非final、非构造方法。由于静态方法属于类,如果父类和子类存在同名的静态方法,那么两者都可以被正常调用。如果方法有final修饰,则表示此方法不可被覆写。
如果想在子类覆写的方法中调用父类方法,则可以使用super关键字。在上述示例代码中,在Son的doSomething方法体里可以使用super.doSomething(a,b,c)调用父类方法。如果与此同时在父类方法的代码中中写一句this.doSomething(),会得到什么样的运行结果呢?
public class Father {
protected void doSomething() {
System.out.println("Father's doSomething");
this.doSomething();
}
public static void main(String[] args) {
Father father = new Son();
father.doSomething();
}
}
class Son extends Father {
@override
public void doSomething() {
System.out.println("Son's doSomething");
super.doSomething();
}
}
在经过了一系列的父子方法循环调用后,JVM崩溃了,发生了StackOverflowError,如图2-8所示。