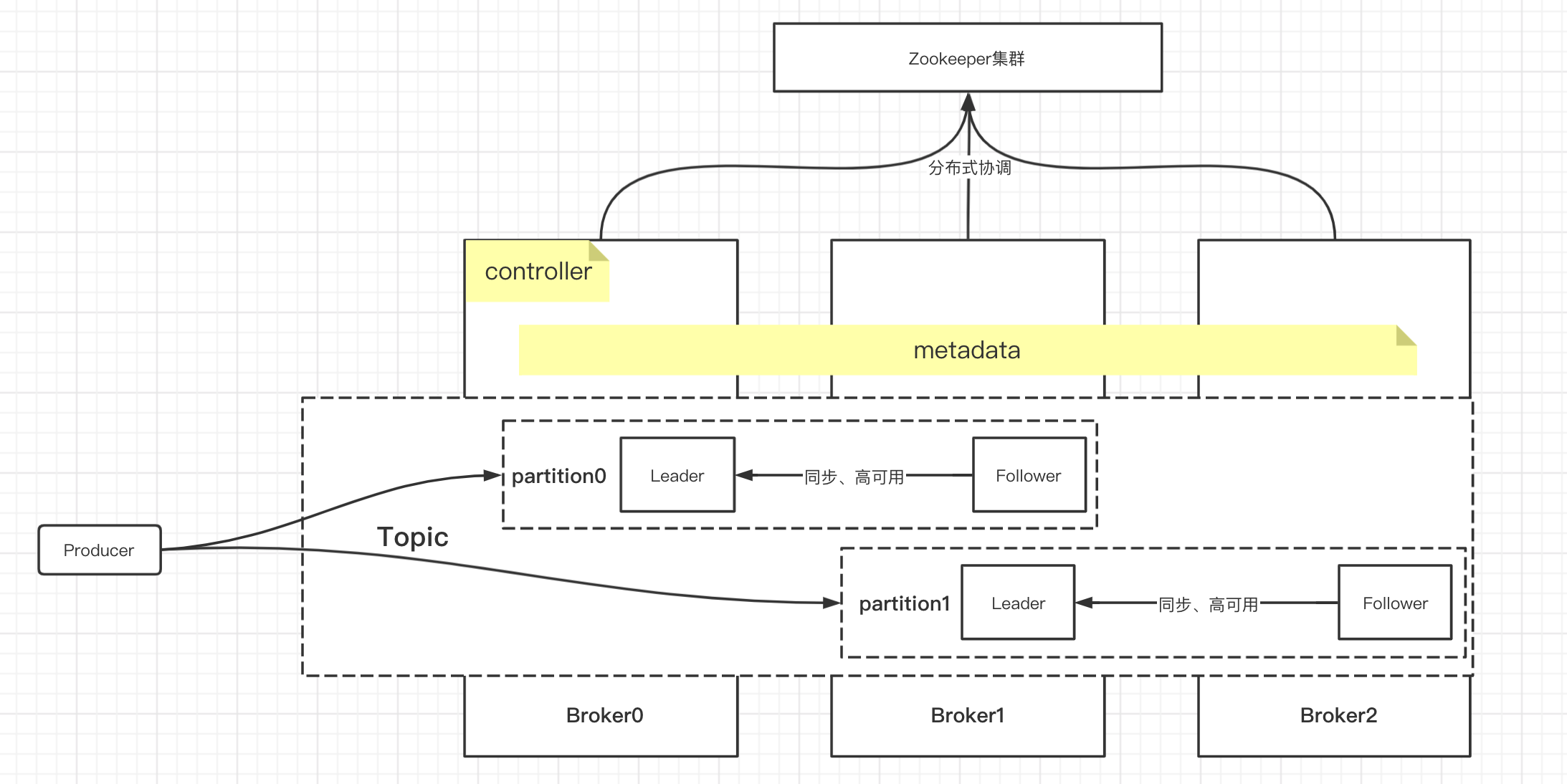
1.概述
Gossip 协议,顾名思义,就像流言蜚语一样,利用一种随机、带有传染性的方式,将信息传播到整个网络中,并在一定时间内,使得系统内的所有节点数据一致。对你来说,掌握这个协议不仅能很好地理解这种最常用的,实现最终一致性的算法,也能在后续工作中得心应手地实现数据的最终一致性。
2.直接邮寄
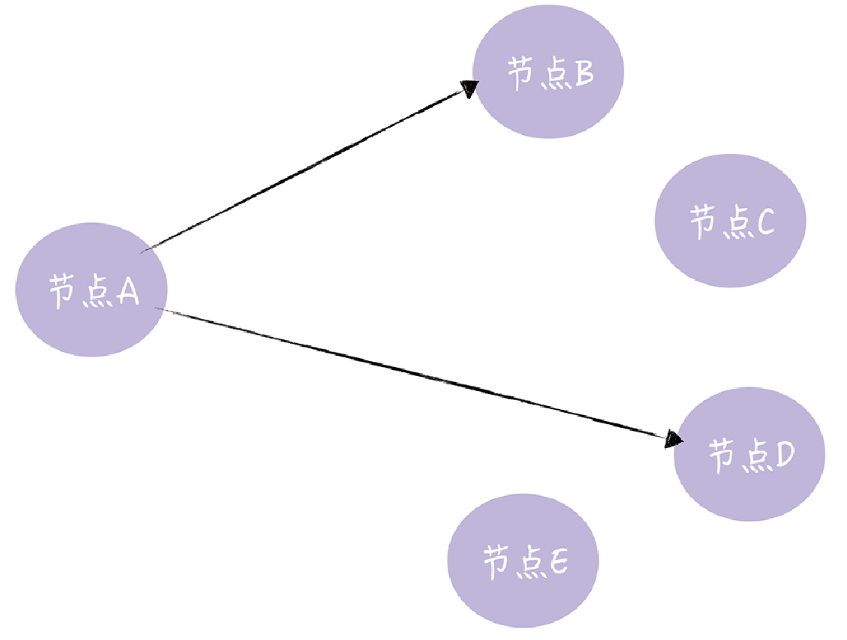
就是直接发送更新数据,当数据发送失败时,将数据缓存下来,然后重传。从图中你可以看到,节点 A 直接将更新数据发送给了节点 B、D。
在这里我想补充一点,直接邮寄虽然实现起来比较容易,数据同步也很及时,但可能会因为
缓存队列满了而丢数据。也就是说,只采用直接邮寄是无法实现最终一致性的。
3.反熵
那如何实现最终一致性呢?答案就是反熵。
本质上,反熵是一种通过异步修复实现最终一致性的方法。常见的最终一致性系统(比如 Cassandra),都实现了反熵功能。反熵中的熵是指混乱程度,反熵就是指消除不同节点中数据的差异,提升节点间数据的相似度,降低熵值。
反熵指的是集群中的节点,每隔段时间就随机选择某个其他节点,然后通过互相交换自己的所有数据来消除两者之间的差异,实现数据的最终一致性。
在实现反熵的时候,主要有推、拉和推拉三种方式。

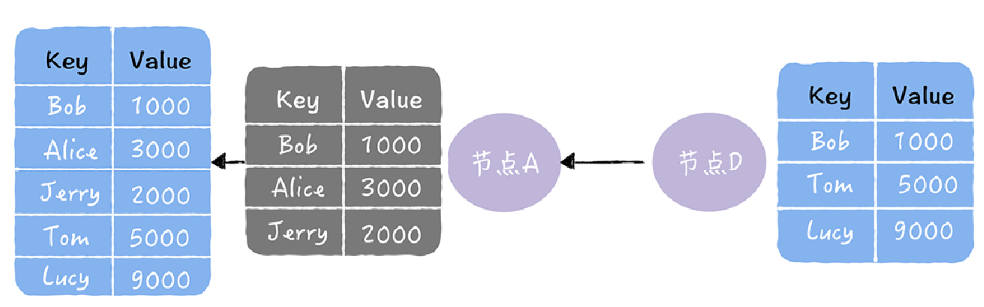
3.1 推
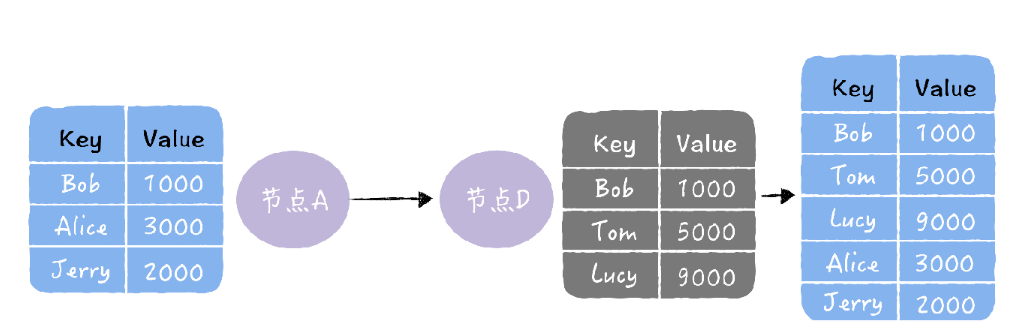
推方式,就是将自己的所有副本数据,推给对方,修复对方副本中的熵:
3.2 拉
拉方式,就是拉取对方的所有副本数据,修复自己副本中的熵:
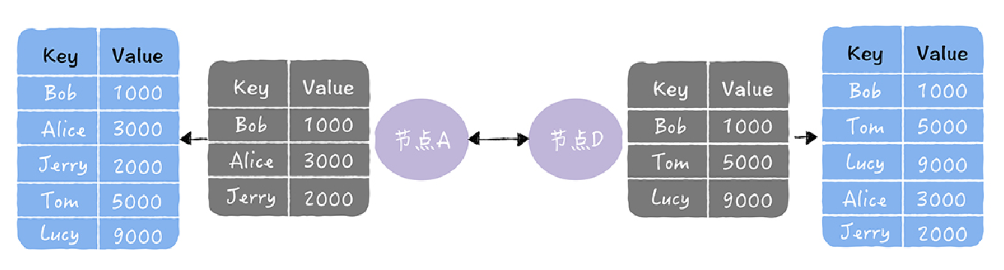
3.3推拉
理解了推和拉之后,推拉这个方式就很好理解了,这个方式就是同时修复自己副本和对方副本中的熵:
另外需要你注意的是,因为反熵需要节点两两交换和比对自己所有的数据,执行反熵时通讯成本会很高,所以我不建议你在实际场景中频繁执行反熵,并且可以通过引入校验和(Checksum)等机制,降低需要对比的数据量和通讯消息等。
4.谣言传播
虽然反熵很实用,但是执行反熵时,相关的节点都是已知的,而且节点数量不能太多,如果是一个动态变化或节点数比较多的分布式环境(比如在 DevOps 环境中检测节点故障,并动态维护集群节点状态),这时反熵就不适用了。那么当你面临这个情况要怎样实现最终一致性呢?答案就是谣言传播。
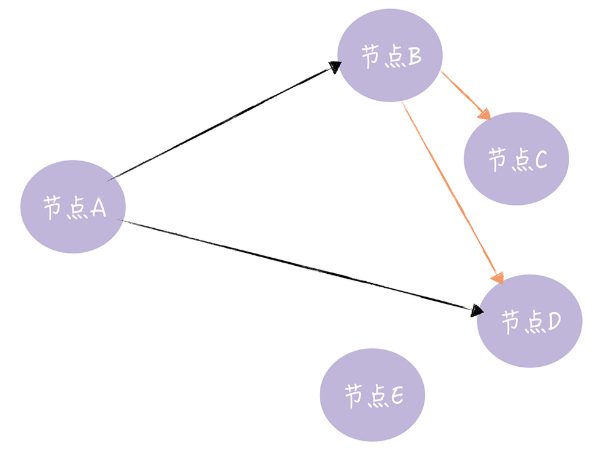
从图中你可以看到,节点 A 向节点 B、D 发送新数据,节点 B 收到新数据后,变成活跃节点,然后节点 B 向节点 C、D 发送新数据。其实,谣言传播非常具有传染性,它适合动态变化的分布式系统。