1 字符集的相关操作
MySQL8.0之前的版本,默认字符集为latin1,8.0及之后默认为utfmb3、utfmb4,如果以前的版本忘记修改默认的密码,就会出现乱码的问题。
1.1 修改步骤
修改mysql字符集配置
查看mysql的字符集编码
mysql> show variables like '%character%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
修改/etc/my.cnf配置文件
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
# Settings user and group are ignored when systemd is used.
# If you need to run mysqld under a different user or group,
# customize your systemd unit file for mariadb according to the
# instructions in http://fedoraproject.org/wiki/Systemd
[mysqld_safe]
log-error=/var/log/mariadb/mariadb.log
pid-file=/var/run/mariadb/mariadb.pid
#
# include all files from the config directory
#
!includedir /etc/my.cnf.d
character_set_server=utf8
修改的编码只会针对新创建的库和表,以前创建的库和表不会被修改
再创建一个数据库:
mysql> create database dbtest;
Query OK, 1 row affected (0.00 sec)
mysql> show create database dbtest;
+----------+-----------------------------------------------------------------+
| Database | Create Database |
+----------+-----------------------------------------------------------------+
| dbtest | CREATE DATABASE `dbtest` /*!40100 DEFAULT CHARACTER SET utf8 */ |
+----------+-----------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> use dbtest;
Database changed
mysql> create table emp1(id int, lname varchar(50));
Query OK, 0 rows affected (0.00 sec)
mysql> show create create table emp1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'create table emp1' at line 1
mysql> show create table emp1;
+-------+----------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+----------------------------------------------------------------------------------------------------------------------------+
| emp1 | CREATE TABLE `emp1` (
`id` int(11) DEFAULT NULL,
`lname` varchar(50) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+-------+----------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.02 sec)
如果此时在一个格式为latin1编码的数据库下创建一张表,其编码格式仍为latin1
修改已创建的库表的字符集配置
mysql> alter database dbtest character set 'utf8';
Query OK, 1 row affected (0.00 sec)
mysql> alter table emp1 convert to character set 'utf8';
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
1.2 各个级别的字符集
MySQL有4个级别的字符集和比较规则:
- 服务器级别
- 数据库级别
- 表级别
- 列级别
之前看到的mysql变量中,character_set_server 就是服务器级别,character_set_database就是数据库级别
mysql> show variables like '%character%'
-> ;
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
对服务器级别的字符集格式的修改会造成数据库级别的字符集修改,下一级的级别在没有设定的情况下会沿用上一级的字符集格式
服务器级别
数据库级别
character_set_database;当前数据库的字符集,可以在创建或者修改数据库的时候指定数据库的字符集和比较规则,具体语法如下:
create database 数据库名
[[Default] character set 字符集名称]
[[Default] collate 比较规则名称];
alter database 数据库名
[[Default] character set 字符集名称]
[[Default] collate 比较规则名称];
如不指定则会使用服务器级别的字符集和比较规则作为当前数据库的字符集和比较规则
表级别
create database 表名(列信息)
[[Default] character set 字符集名称]
[[Default] collate 比较规则名称];
alter database 表名(列信息)
[[Default] character set 字符集名称]
[[Default] collate 比较规则名称];
同样不指定则会沿用数据库的比较规则
列级别
同一个表中的列也能够有不同的字符集和比较规则,具体语法如下:
create table 表名 (
列名 数据类型 [character set 字符集名称] [collate 比较规则名称]
)
alter table 表名 modify 列名 字符串类型 [character set 字符集名称] [collate 比较规则名称]
1.3 字符集与比较规则
utf8与utf8mb4
utf8字符集一个字符需要1-4个字节,但一般情况下3个字节就够了,因此又细化分成两个概念:
- utf8mb3:只使用1-3个字节表示字符
- utf8mb4:使用1-4个字节表示字符,如emoji表情就需要四个字节
show charset 查看支持的字符集和对应的比较规则
mysql> show charset
-> ;
+----------+---------------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+---------------------------------+---------------------+--------+
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| dec8 | DEC West European | dec8_swedish_ci | 1 |
| cp850 | DOS West European | cp850_general_ci | 1 |
| hp8 | HP West European | hp8_english_ci | 1 |
| koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 |
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 |
| swe7 | 7bit Swedish | swe7_swedish_ci | 1 |
| ascii | US ASCII | ascii_general_ci | 1 |
| ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
| sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 |
| hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 |
| tis620 | TIS620 Thai | tis620_thai_ci | 1 |
| euckr | EUC-KR Korean | euckr_korean_ci | 2 |
| koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 |
| gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 |
| greek | ISO 8859-7 Greek | greek_general_ci | 1 |
| cp1250 | Windows Central European | cp1250_general_ci | 1 |
| gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 |
| latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 |
| armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 |
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
| cp866 | DOS Russian | cp866_general_ci | 1 |
| keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 |
| macce | Mac Central European | macce_general_ci | 1 |
| macroman | Mac West European | macroman_general_ci | 1 |
| cp852 | DOS Central European | cp852_general_ci | 1 |
| latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 |
| cp1251 | Windows Cyrillic | cp1251_general_ci | 1 |
| utf16 | UTF-16 Unicode | utf16_general_ci | 4 |
| utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 |
| cp1256 | Windows Arabic | cp1256_general_ci | 1 |
| cp1257 | Windows Baltic | cp1257_general_ci | 1 |
| utf32 | UTF-32 Unicode | utf32_general_ci | 4 |
| binary | Binary pseudo charset | binary | 1 |
| geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 |
| cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 |
| eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |
| gb18030 | China National Standard GB18030 | gb18030_chinese_ci | 4 |
+----------+---------------------------------+---------------------+--------+
41 rows in set (0.00 sec)
比较规则
比较规则主要记录字符集比较主要作用于哪种语言,geostd8_general_ci是一种通用的比较规则
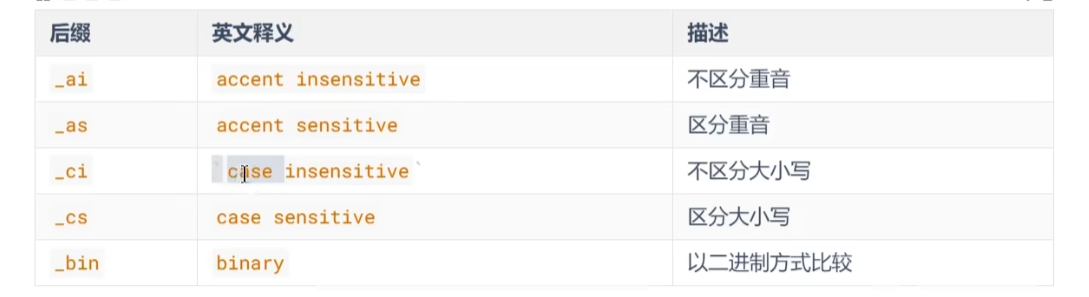
可以使用show collation查看比较规则
mysql> show collation like 'gbk%';
+----------------+---------+----+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+----------------+---------+----+---------+----------+---------+
| gbk_chinese_ci | gbk | 28 | Yes | Yes | 1 |
| gbk_bin | gbk | 87 | | Yes | 1 |
+----------------+---------+----+---------+----------+---------+
2 rows in set (0.00 sec)
Maxlen
记录字符集最多占用的字节数

1.4 SQL大小写规范
Windows和Linux平台区别
在SQL中,关键字和函数名是不区分大小写的,但也有所区别,分别在两个平台的mysql中执行下面的语句:
show variables like '%lower_case_table_names%'
结果windows中这个lower_case_table_names变量的值为1,linux中则为0
- 默认为0,表示大小写敏感
- 设置为1,大小写不敏感,创建的表、数据库都是以小写的形式存放在数据库上,对sql语句都是转换成小写对表和数据库进行查找
- 设置为2,创建的表和数据库都是按照语句上的格式存放,凡是查找都转换为小写进行
总结来说,MySQL在Linux下数据库名、表名、列名、别名的大小写规则是这样的:
- 数据库名、表名、表别名、变量名严格区分大小写
- 关键字、函数名在SQL不区分大小写
- 列名与列的别名在所有情况下均是忽略大小写的
Windows环境下均忽略大小写
SQL编写建议
- 关键字和函数名全部大写
- 数据库名、表名、表别名、字段名、字段别名全部小写
- 以分号结尾