迁移学习(EADA)《Active Learning for Domain Adaptation: An Energy-Based Approach》
论文信息
论文标题:Active Learning for Domain Adaptation: An Energy-Based Approach
论文作者:Binhui Xie, Longhui Yuan, Shuang Li, Chi Harold Liu, Xinjing Cheng, Guoren Wang
论文来源:AAAI 2022
论文地址:download
论文代码:download
引用次数:225
1 介绍
在本文中,提倡使用基于能量的模型(EBMs)来帮助实现领域转移下的主动学习的潜力。已经证明,与标准鉴别分类器相比,基于能量的训练提高了校准,更好地区分分布内和分布外样本。在这一点上,本文开始使用不同的方法来研究自由能在源域和目标域上的分布,并从 $\text{Figure1}$ 中进行了一些观察:
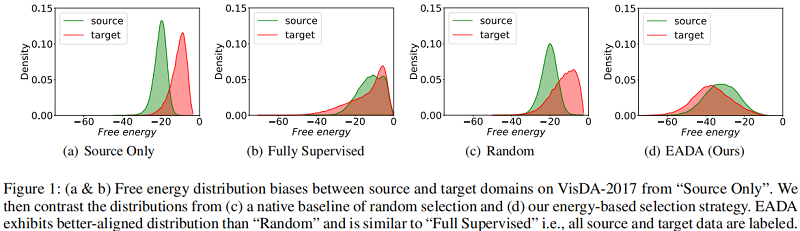
Figure1(a):仅对标记源数据进行训练的模型会导致监督源数据的自由能分布低于未标记目标数据的自由能分布,即两个域之间的自由能偏差;
Figure1(b):当对源域和目标域数据使用监督数据的时候,两者的自由能趋于一致;
Figure1(c):当在训练中随机标注一些未标记的目标数据时,偏差略微有消除;
Figure1(d):本文使用的方法;
2 Problem Statement
在主动域适应学习中,拥有不同数据分布的带标签源域数据 $\mathcal{S}=\left\{\left(x_{s}, y_{s}\right)\right\} $ 和不带标签的目标域数据 $\mathcal{T}=\left\{x_{t}\right\}$。根据标准的主动域适应学习,$B$ 是远小于带标签数 $\mathcal{T}$ 的采样数,目标域包括带标签样本 $\mathcal{T}_{l}$ 和不带标签样本
3 Method
3.1 基于能源的模型重新审视
机器学习的本质是对变量之间的依赖关系进行编码。让我们考虑一个基于能量的模型(EBM),其中有两组变量 $x$(一个高维变量)和 $y$(一个离散变量)。训练这个模型包括找到一个能量函数,即 $E(x, y)$,它给正确的答案最低的能量,给所有其他(不正确的)答案更高的能量 $1$。准确地说,模型必须产生 $E(x, y)$ 最小的值 $y^{*}$:
$y^{*}=\arg \min _{y \in \mathcal{Y}} E(x, y) \quad\quad\quad(1)$
一般来说,集合 $Y$ 的大小对于分类很小,因此推理过程可以简单地计算 $y \in Y$ 的所有可能值的 $E(x, y)$,并选择最小的。
利用能量函数,可以通过吉布斯分布估计输入 $x$ 和标签 $y$ 的联合概率:
$p(x, y)=\exp (-E(x, y)) / Z \quad\quad\quad(2)$
其中,$ Z=\sum\limits_{x \in \mathcal{X}} \sum\limits_{y \in \mathcal{Y}} \exp (-E(x, y))$
通过边缘化 $y$,我们也得到了 $x$ 的概率密度,
$p(x)=\sum\limits _{y \in \mathcal{Y}} p(x, y)=\sum\limits_{y \in \mathcal{Y}} \exp (-E(x, y)) / Z\quad\quad\quad(3)$
直观地说,在 Active DA 中,为了选择最具代表性的目标样本,可以直接从 $\text{Eq.3}$ 中估计每个目标样本的出现概率然后选择概率较低的样本。
不幸的是,我们无法计算甚至可靠地估计 $z$。因此,我们转向自由能,即 $\mathcal{F}(x)$,一个隐藏在 $\text{EBM}$ 中的函数,作为变量 $x$ 出现的“合理性”。在数学上,$x$ 的概率密度也可以表示为:
$p(x)=\frac{\exp (-\mathcal{F}(x))}{\sum\limits _{x \in \mathcal{X}} \exp (-\mathcal{F}(x))} \quad\quad\quad(4)$
这个公式表明,用 $\mathcal{F}(x)$ 可以代替 $p(x)$ 来选择概率较低的目标样本。通过 $\text{Eq.3}$ 和 $\text{Eq.4}$,有:
$\mathcal{F}(x)=-\log \sum\limits _{y \in \mathcal{Y}} \exp (-E(x, y))\quad\quad\quad(5)$
3.2 基于能源的主动域自适应
我们利用 $\text{EBM}$ 的一个新视角来获得主动域适应的好处,其中源数据和目标数据之间的自由能偏差允许有效的选择和适应。下面,我们首先描述如何训练具有几个损失函数的 $\text{EBM}$。然后,我们展示了如何通过基于能量的采样策略来查询和注释信息最丰富的未标记目标数据。最后,我们给出了一个直观的充分条件。
3.2.1 训练过程
给定一组标记源样本 $\mathcal{S}=\left\{\left(x_{s}, y_{s}\right)\right\}$,我们想要训练一个行为良好的 $\text{EBM}$,它给正确答案最低的能量,给所有其他(不正确)答案提供更高的能量。为此,我们利用 $\text{EBM}$ 中常用的损失,即来自概率建模的负对数似然损失来训练一个分类模型,它可以表述为
$\mathcal{L}_{n l l}(x, y ; \theta)=E(x, y ; \theta)+\frac{1}{\tau} \log \sum\limits _{c \in \mathcal{Y}} \exp (-\tau E(x, c ; \theta))\quad\quad\quad(6)$
其中 $\tau(\tau>0)$ 是相反的温度,一个低值对应于空间 $y$ 上能量的平滑分配。为了简单起见,我们固定 $\tau=1$,然后我们有
$\mathcal{L}_{n l l}(x, y ; \theta)=E(x, y ; \theta)-\mathcal{F}(x ; \theta)\quad\quad\quad(7)$
===