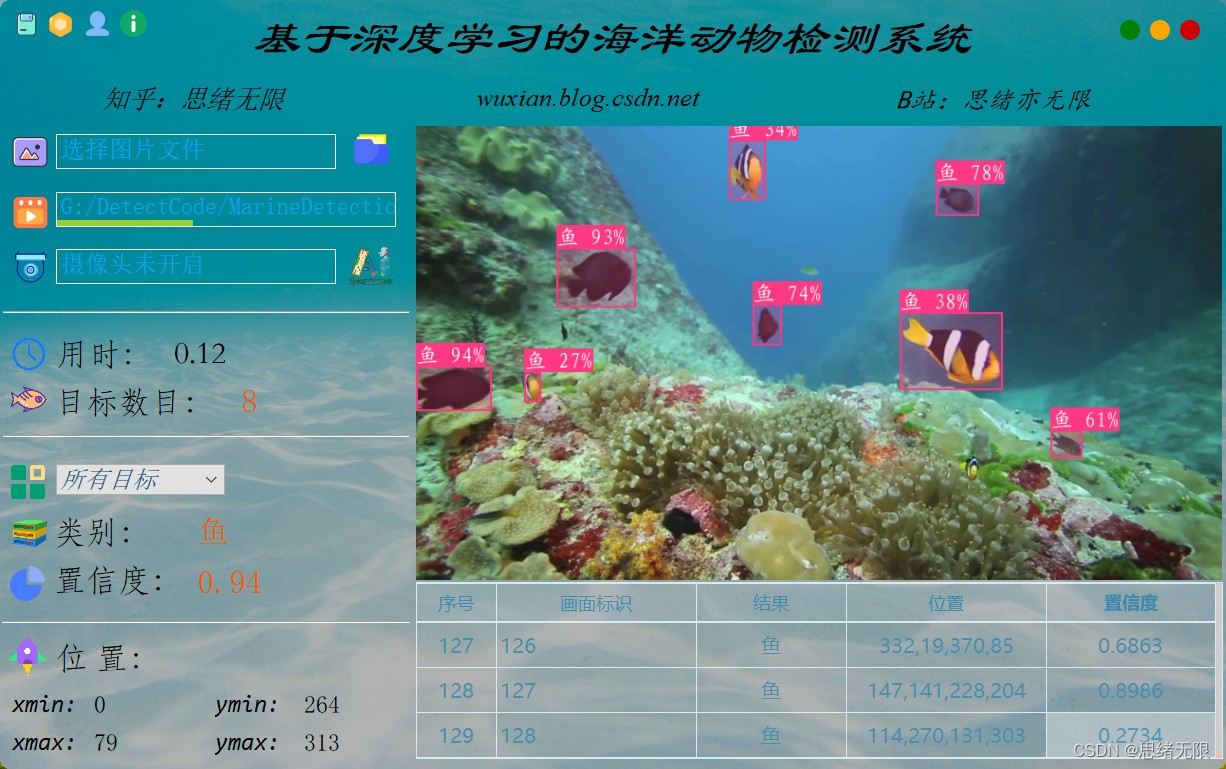
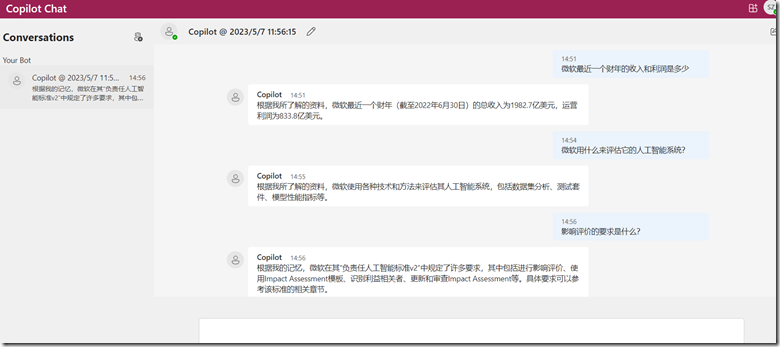
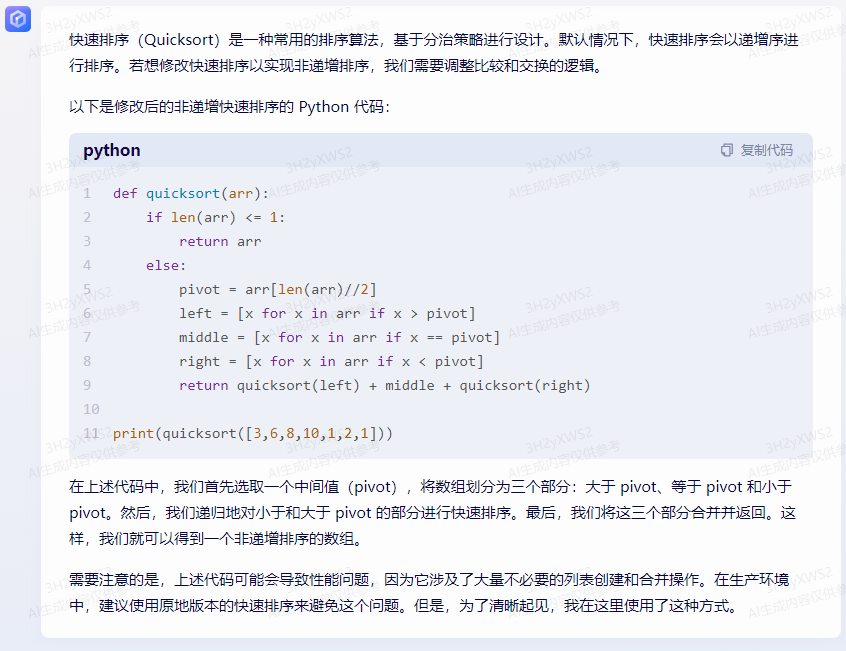
1.进行PDF切割
python代码如下:


# 20220521 # 1.选择要分割的文件 # 2.选择要保存的位置,分割为多个文件时,可自动用页码命名 # 3.输入要分割的页码,可以是一个范围1-23(将第1-23页提取出来),也可以是单个页码,12(将第12页单独提取出来) # 4.点击按钮执行 # 20220528 # 模块化 可用 # 20220529 输入页码范围判断 import os.path from PyPDF2 import PdfReader, PdfWriter import tkinter as tk from tkinter import filedialog as fd import tkinter.messagebox file_types = [('PDF文件', '.pdf')] # 分割操作,三个参数分别为待分割文件,分割开始页,结束页 def split_pdf(pdf_i, start_page, end_page): pdf = PdfReader(pdf_i) # pages = len(pdf.pages) # pages = pdf.getNumPages() pdf_wt = PdfWriter() # print(pages) for i in range(start_page - 1, end_page): pdf_wt.add_page(pdf.pages[i]) # pdf_wt.add_page(pdf.pages(i)) # 使用wb模式。使用ab模式的话,会保留原始数据,文件会越来越大 pdf_path, pdf_name = os.path.split(pdf_in.get()) pdf_name, pdf_ext = os.path.splitext(pdf_name) split_name = pdf_out.get() + '\\' + pdf_name + f'(第{start_page}——{end_page}页).pdf' split_name2 = pdf_out.get() + '\\' + pdf_name + f'(第{start_page}页).pdf' pdf_name = split_name2 if start_page == end_page else split_name with open(pdf_name, 'wb') as outfile: pdf_wt.write(outfile) # 选择待分割文件 def select_pdf(): pdf_selected = fd.askopenfilename(filetypes=file_types) if pdf_selected != '': pdf_in.set(pdf_selected) pdf = PdfReader(pdf_selected) pages = len(pdf.pages) pdf_pages.set(f'③输入要分割的页码:(页码范围1-{pages})') button_out['state'] = 'normal' # button_split['state'] = 'normal' # 选择保存位置 def select_out(): # path_save = fd.asksaveasfilename(defaultextension='*.pdf', filetypes=file_types) path_save = fd.askdirectory() # a = fd.askdirectory() if path_save != '': button_split['state'] = 'normal' pdf_out.set(path_save) # 分割前操作 def pdf_split(): if pdf_out2.get() != '': # 输入页码范围时,将中文’,‘替换为英文',' page_out_in = pdf_out2.get().replace(',', ',') # 将输入的要分割的页码分开 page_split = page_out_in.split(',') # 要分割的pdf文件名称,获取StringVar中存储的数据 pdf_to_be_split = pdf_in.get() pdf = PdfReader(pdf_to_be_split) pages = len(pdf.pages) flag_successed = 0 flag_failed = [] for i in page_split: page_range = i.split('-') page_range_l = len(page_range) # 如果输入的是一个范围,获取获取开始页和结束页。例如,1-18,18-39,2-15 # 起始页大于结束页时,不能正确分割 if page_range_l > 1: start_page = int(page_range[0]) end_page = int(page_range[1]) if start_page <= end_page <= pages: # print(start_page, end_page, pages) split_pdf(pdf_to_be_split, start_page, end_page) flag_successed += 1 # tkinter.messagebox.showinfo('操作提示', '分割成功') else: flag_failed.append(f'{start_page}-{end_page}') # tkinter.messagebox.showinfo('操作提示', f'页码输入错误,页码范围为1——{pages}') # 输入的是某个数值,单独提取一页。例如1,3,12,5,53 # 输入数值大于待分割文件总页数时,不能正常分割 elif page_range_l == 1: if int(page_range[0]) <= pages: split_pdf(pdf_to_be_split, int(page_range[0]), int(page_range[0])) flag_successed += 1 # tkinter.messagebox.showinfo('操作提示', '分割成功') else: flag_failed.append(f'{page_range[0]}') # tkinter.messagebox.showinfo('操作提示', f'页码输入错误,页码范围为1——{pages}') if len(flag_failed) == 0: tkinter.messagebox.showinfo('操作提示', f'{flag_successed}个文件分割成功') else: tkinter.messagebox.showinfo('操作提示', f'{flag_successed}个文件分割成功,{len(flag_failed)}个文件分割失败') tkinter.messagebox.showinfo('操作提示', f'以下页码输入错误,页码范围为1--{pages}\n{flag_failed}') global pdf_in, pdf_out, pdf_out2, entry_out, entry_out2, pdf_pages, button_out, button_split def main(root3): global pdf_in, pdf_out, pdf_out2, entry_out, entry_out2, pdf_pages, button_out, button_split pdf_in = tk.StringVar() pdf_out = tk.StringVar() pdf_out2 = tk.StringVar() pdf_pages = tk.StringVar() pdf_pages.set('③输入要分割的页码:') label_input = tk.Label(root3, text='①选择要分割的PDF文件:') entry_input = tk.Entry(root3, textvariable=pdf_in, width=45) button_input = tk.Button(root3, text='①选择要分割的PDF文件', command=select_pdf) label_out = tk.Label(root3, text='②选择输出文件夹:') entry_out = tk.Entry(root3, textvariable=pdf_out, width=45) button_out = tk.Button(root3, text='②选择保存位置', command=select_out) button_out['state'] = 'disabled' page_out = tk.Label(root3, textvariable=pdf_pages, text='③输入要分割的页码:') page_out_ = tk.Label(root3, text='(可分割为多个PDF,用逗号分隔。例如,1-10,2-17,10,12)') entry_out2 = tk.Entry(root3, textvariable=pdf_out2, width=45) button_split = tk.Button(root3, text='④执行分割', command=pdf_split, width=20, height=3) button_split['state'] = 'disabled' # entry_out2.bind('<Key>', jc) # button_split.configure(text=pdf_out2.get()) label_input.place(x=10, y=10) entry_input.place(x=10, y=35) button_input.place(x=350, y=32) label_out.place(x=10, y=80) entry_out.place(x=10, y=105) button_out.place(x=350, y=97) page_out.place(x=10, y=150) page_out_.place(x=10, y=175) entry_out2.place(x=10, y=200) button_split.place(x=220, y=240) root2 = tk.Tk() # 窗口尺寸 # root.geometry('400x300') # 窗口居中 sw = root2.winfo_screenwidth() sh = root2.winfo_screenheight() c = (sw - 400) / 2 d = (sh - 300) / 2 # print(a,b,c,d) root2.geometry('605x500+%d+%d' % (c, d)) # 软件标题 root2.title('PDF分割软件') # # 软件左上角图标 # root2.iconbitmap('tubiao.ico') # 窗口大小不可调 root2.resizable(width=False, height=False) root = tk.Frame(root2, width=605, height=500) root.place(x=0, y=0) main(root) root2.mainloop()
View Code
2.进行PDF合并
有合并顺序需手动进行数字命名。如:01.pdf,02.pdf,03.pdf,04.pdf……
import os from PyPDF2 import PdfMerger #target_path = r'C:\Users\Administrator\Desktop\合并pdf文件' # pdf目录文件 path = __file__ target_path = os.path.dirname(path) pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')] pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst] file_merger = PdfMerger() for pdf in pdf_lst: file_merger.append(pdf,import_outline=False) # 合并pdf文件 file_merger.write(r"合并文件.pdf")
View Code