联邦学习笔记——003
2022.11.28周一
今天主要学习了几篇优秀的博客,补充了一些知识。
(一)联邦学习面临的挑战
-
非独立同分布的数据
-
有限通信带宽
-
不可靠和有限的设备
什么是Non-IID(非独立同分布)数据?
下面列举了数据偏离同分布的一些常见方式,即对于不用的客户端 \(i\) 和客户端 \(j\) 的分布不同,即 \(\mathcal{P}_i \neq \mathcal{P}_j\)。我们将 \(\mathcal{P}_i(x,y)\)重写为 \(\mathcal{P}_i(y|x)\mathcal{P}_i(x)\) 和 \(\mathcal{P}_i(x|y)\mathcal{P}_i(y)\)。
-
特征分布倾斜(协变量飘移):即使共享 \(\mathcal{P}(y|x)\),不同客户端上的边缘分布 \(\mathcal{P}_i(x)\)也可能不同。比如,在手写识别领域,用户在书写同一个单词时也可能有着不同的笔画宽度、斜度等。
-
标签分布倾斜(先验概率飘移):即使 \(\mathcal{P}(x|y)\)是相同的,对于不同客户端上的边缘分布 \(\mathcal{P}_i(y)\)也可能不同。比如,当客户端与特定的地理区域绑定时,标签的分布在不同的客户端上是不同的。比如:袋鼠只在澳大利亚或动物园里;一个人的脸只在出现在全球的几个地方;对于手机设备的键盘,某些特定人群使用某些表情,而其他人不使用。
-
标签相同,特征不同(概念飘移):即使共享 \(\mathcal{P}(y)\),不同客户端上的条件分布 \(\mathcal{P}_i(x|y)\)也可能是不同。由于文化差异,天气影响,生活水平等因素,对于相同的标签 \(y\),对于不同的客户端可能对应着差异非常大的特征 \(x\)。比如:世界各地的家庭图片千差万别,衣着也千差万别。即使在美国,冬季停放的被大雪覆盖汽车的图像只会出现在某些地区。同样的品牌在不同的时间和不同的时间尺度上看起来也会有很大的不同:白天和晚上、季节效应、自然灾害、时尚设计潮流等等。
-
特征相同,标签不同(概念飘移):即使 \(\mathcal{P}(X)\)是相同的,对于不同客户端上的条件分布 \(\mathcal{P}_i(y|x)\)也可能不同。由于个人偏好,训练数据项中的相同特征向量可能具有不同的标签。例如,反映情绪或单词联想的标签有着个人和地区差异。
-
数量倾斜或者不平衡:不同的客户可以拥有着样本数量差异很大的数据。
参考:
(二)研究方向
隐私保护
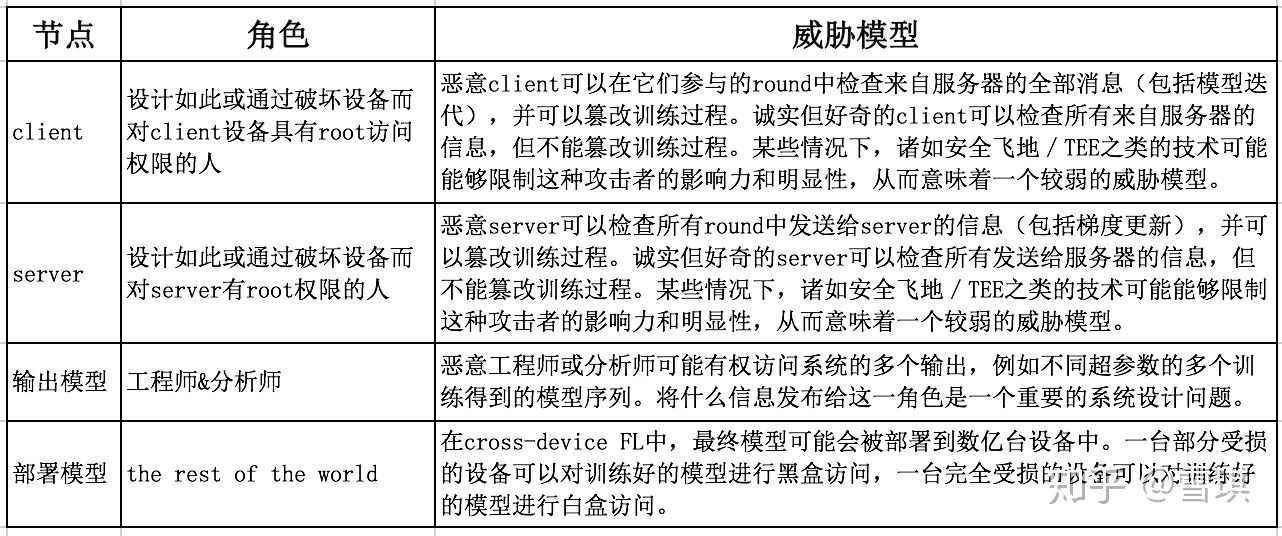
首先,明确一个问题,我们需要抵御什么样的威胁?
在联邦学习中,对隐私风险的规范处理需要一种整体的、跨学科的方法。对于一些风险类型,可以通过将现有技术扩展到指定场景中从而保护隐私和减轻风险,而其他更复杂的风险类型则需要跨学科的协同努力。
下表是联邦学习需要抵御的威胁
其次,这方面的研究涉及到的工具与技术主要有三个方向:
-
安全计算
- 可信执行环境
- 安全多方计算
- 其他技术,例如安全聚合,安全shuffle
-
隐私保护
- 本地差分隐私
- 分布式差分隐私
- 通过安全聚合实现分布式差分隐私
例如,每台设备可以在安全聚合之前干扰自己的模型参数,以实现本地差分隐私。通过正确设计噪声,我们可以确保聚合结果中的噪声与通过可信服务器集中添加的噪声(例如,具有低ε/高隐私级别)相匹配 - 通过安全shuffling实现分布式差分隐私
本地数据使用本地差分隐私进行加密,然后所有人传到一个安全shuffler,shuffler打乱次序,再发给服务器(不包含任何标识信息)。shuffler可以作为一个可信第三方,独立于服务器并专门用于shuffle。
- 通过安全聚合实现分布式差分隐私
- 混合差分隐私
通过允许多种模型共存,与纯本地DP或纯中央DP机制相比,混合模型机制可以在给定用户群中实现更高的实用性,例如根据场景不同,一部分人用本地差分隐私协议加密,一部分人直接贡献其信息。
-
可验证性
-
零知识证明(ZKPs)
-
可信执行环境中的远程证明
主要作用:
- 证明服务器已经进行了聚合,shuffle,或者添加差分隐私的操作。
- 证明client输入的数据符合某项规范
-