jieba库使用
1.介绍
jieba库是python中一个非常重要的第三方中文分词函数库,其工作原理是:利用一个中文词库,将待分词的内容与词库进行对比,通过图结构和动态规划的方法找到最大概率的词组。该jieba库还提供了增加自定义中文词组的功能。
注意:
是中文分词函数库
jieba库支持一下3种分词模式:
精确模式:
将句子精确的切开,适合文本分析
全模式:
把句子中所有可以成词的词语都描述出来,速度非常快,但不能消除歧义
搜索引擎模式:
在精确模式的基础上,对长词再次切分,适合搜索引擎分词
2.安装
pip install jieba
3.英文分词
由于英文文本是通过空格或者标点进行分隔的,因此分词比较方便
#案例
import jieba
txts = "China is a beautiful country"
str = txts.split()
print(str)

4.中文分词
中文文本分词之所以比较困难,是因为中文句子内部缺少分隔符,使之不能直接进行分词
#基础案例
import jieba
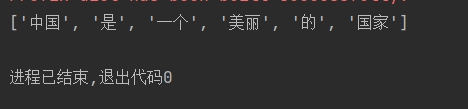
txts = "中国是一个美丽的国家"
str = jieba.lcut(txts)
print(str)
jieba库常用分词函数
| 函数 | 描述 |
|---|---|
| cut(s) | 精确模式,返回一个可迭代的数据类型 |
| cut(s,cut_all=True) | 全模式,输出文本s中所有可能的单词 |
| cut_for_search(s) | 搜索引擎模式,适合搜索引擎建立索引的分词结果 |
| lcut(s) | 精确模式,返回一个列表类型,建议使用 |
| lcut(s,cut_all=True) | 全模式,返回一个列表类型,建议使用 |
| lcut_for_search(s) | 搜索引擎模式,返回一个列表类型,建议使用 |
| add_word(w) | 向分词词典中增加新词w |
对比案例:使用cut_all=True与不使用cut_all=True的区别
##使用cut_all=True
import jieba
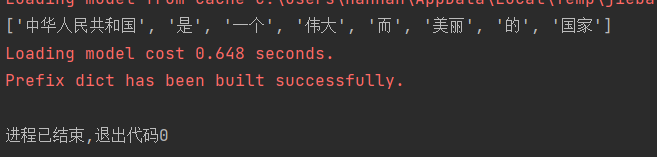
txts = "中华人民共和国是一个伟大而美丽的国家"
str = jieba.lcut(txts,cut_all=True)
print(str)
##不使用cut_all=True
import jieba
txts = "中华人民共和国是一个伟大而美丽的国家"
str = jieba.lcut(txts)
print(str)
使用cut_all=True结果

不使用cut_all=True结果
总结
jieba.lcut():返回精确模式,输出的分词刚好能够且不多余地组成原始文本
jieba.lcut(s,True):返回全模式,输出原始文本中,可能产生的所有词组,重复性最大
jieba.lcut_search():返回搜索引擎模式,首先执行精确模式,然后在对其中的长词进一步切分以获得结果。
案例一:英语词频统计案例
import jieba
#1.创建一个读取文件的函数findText()
def findText():
# 读取文本
txt = open("txt.txt", "r", encoding='utf-8').read()
# 将文本中的英文全部变成小写
txt = txt.lower()
# 将英文中的符号全部变成空格
for c in '!"#$%&()*+,-./;:<=>?@[\\]\'_{|}~':
txt = txt.replace(c, " ")
return txt
#2.创建findText()对象
Txts = findText()
#3.切割英语文本
words = Txts.split()
#4.创建一个counts集合,统计每个单词出现的次数
counts = {}
for word in words:
counts[word] = counts.get(word, 0) + 1
#5.将counts进行格式转换,变成[("is",1)]格式,外面是列表,里面是元祖
items = list(counts.items())
#6.将items根据单词出现的个数进行排序,从高到低
items.sort(key=lambda x: x[1], reverse=True)
#7.获取前10个最高的单词
for i in range(10):
word, count = items[i]
print("{0:<12}{1:>4}".format(word, count))
案例二:中文词频统计案例
import jieba
#1.读取中文txt文件
txt = open("txt.txt", "r", encoding='utf-8').read()
#2.对该文件进行切词
words = jieba.lcut(txt)
#3.创建counts集合,来保存切分后的词语
counts={}
#4.进行词频统计
for word in words:
if len(word) ==1:
continue
else:
counts[word]=counts.get(word,0)+1
#5.对切分后的词频,进行格式转换,转换成外面是列表,里面是元祖的形式,并且根据词频的大小,进行排序
items = list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
#6.取出前10个最大的词语
for i in range(10):
word,count = items[i]
print("{0:<10}{1:>5}".format(word.count()))










![[数据结构]单向链表插入排序(C语言)](https://img2023.cnblogs.com/blog/3039354/202301/3039354-20230118205923906-1018009121.jpg)









