序列化类常用字段和字段参数
drf在Django字段类型的基础上派生了自己的字段类型以及字段参数- 序列化器的字段类型用于处理原始值和内部数据类型直接的转换
- 还可以用于验证输入、以及父对象检索和设置值
常用字段类
| 字段 | 字段构造方式 |
|---|---|
| BooleanField | BooleanField() |
| NullBooleanField | NullBooleanField() |
| CharField | CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True) |
| EmailField | EmailField(max_length=None, min_length=None, allow_blank=False) |
| RegexField | RegexField(regex, max_length=None, min_length=None, allow_blank=False) |
| SlugField | SlugField(max_length=50, min_length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9-]+ |
| URLField | URLField(max_length=200, min_length=None, allow_blank=False) |
| UUIDField | UUIDField(format=’hex_verbose’) format: 1) 'hex_verbose' 如"5ce0e9a5-5ffa-654b-cee0-1238041fb31a" 2) 'hex' 如 "5ce0e9a55ffa654bcee01238041fb31a" 3)'int' - 如: "123456789012312313134124512351145145114" 4)'urn' 如: "urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a" |
| IPAddressField | IPAddressField(protocol=’both’, unpack_ipv4=False, **options) |
| IntegerField | IntegerField(max_value=None, min_value=None) |
| FloatField | FloatField(max_value=None, min_value=None) |
| DecimalField | DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_palces: 小数点位置 |
| DateTimeField | DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None) |
| DateField | DateField(format=api_settings.DATE_FORMAT, input_formats=None) |
| TimeField | TimeField(format=api_settings.TIME_FORMAT, input_formats=None) |
| DurationField | DurationField() |
| ChoiceField | ChoiceField(choices) choices与Django的用法相同 |
| MultipleChoiceField | MultipleChoiceField(choices) |
| FileField | FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ImageField | ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
重要,后面讲
| 字段 | 字段构造方式 |
|---|---|
| ListField | ListField(child=, min_length=None, max_length=None) |
| DictField | DictField(child=) |
常用字段参数
选项参数
| 参数名称 | 说明 |
|---|---|
| max_length | 最大长度 |
| min_lenght | 最小长度 |
| allow_blank | 是否允许为空 |
| trim_whitespace | 是否截断空白字符 |
| max_value | 最小值 |
| min_value | 最大值 |
通用参数
| 参数名称 | 说明 |
|---|---|
| required | 表明该字段在反序列化时必须输入,默认True |
| default | 反序列化时使用的默认值 |
| allow_null | 表明该字段是否允许传入None,默认False |
| validators | 该字段使用的验证器 |
看一眼忘掉
| 参数名称 | 说明 |
|---|---|
| error_messages | 包含错误编号与错误信息的字典 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text | 用于HTML展示API页面时,显示的字段帮助提示信息 |
重点
| 参数名称 | 说明 |
|---|---|
| read_only | 表明该字段仅用于序列化输出,默认False |
| write_only | 表明该字段仅用于反序列化输入,默认False |
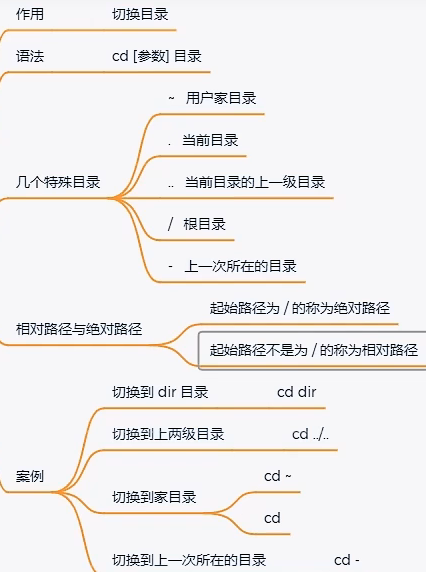
反序列化校验执行流程
-1 先执行字段自己的校验规则----》最大长度,最小长度,是否为空,是否必填,最小数字。。。。
-2 validators=[方法,] ----》单独给这个字段加校验规则
name=serializers.CharField(validators=[方法,])
-3 局部钩子校验规则
-4 全局钩子校验规则
序列化高级用法之source
- 创建关联表
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.CharField(max_length=32)
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE) # 留住,还有很多
authors = models.ManyToManyField(to='Author')
class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=32)
class Author(models.Model):
name = models.CharField(max_length=32)
phone = models.CharField(max_length=11)
- 迁移,录入数据
makemigrations
migrate
序列化定制字段名字
- 重点:source可以指定序列化字段的名字
-自有字段,直接写字段名字
-name_real = serializers.CharField(max_length=8, source='name')
-关联字段,一对多的关联,直接点
-publish = serializers.CharField(source='publish.name')
-多对多,搞不了,source不能用
-authors=serializers.CharField(source='authors.all')
- 序列化类
class BookSerializer(serializers.Serializer):
# 字段参数,通用的,所有字段都可以写 通过source指定哪个字段
# 自有字段,直接写字段名字
name_real = serializers.CharField(max_length=8, source='name')
real_price = serializers.CharField(source='price')
# 关联字段,一对多的关联,直接点
publish = serializers.CharField(source='publish.name')
#多对多,搞不了,source不能用
authors=serializers.CharField(source='authors.all')
序列化高级用法之定制字段的两种方式
方式一:SerializerMethodField定制
定制关联字段的显示形式
- 一对多的,显示字典
- 多对多,显示列表套字典
代码如下:
class BookSerializer(serializers.Serializer):
name = serializers.CharField(max_length=8)
price = serializers.CharField()
# 定制返回格式---》方式一
publish_detail = serializers.SerializerMethodField()
def get_publish_detail(self, obj):
return {'name': obj.publish.name, 'addr': obj.publish.addr}
author_list = serializers.SerializerMethodField()
def get_author_list(self, obj):
l = []
for author in obj.authors.all():
l.append({'name': author.name, 'phone': author.phone})
return l
在表模型中定制
表模型
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.CharField(max_length=32)
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE) # 留住,还有很多
authors = models.ManyToManyField(to='Author')
def publish_detail(self):
return {'name': self.publish.name, 'addr': self.publish.addr}
def author_list(self):
l = []
for author in self.authors.all():
l.append({'name': author.name, 'phone': author.phone})
return l
序列化类
class BookSerializer(serializers.Serializer):
name = serializers.CharField(max_length=8)
price = serializers.CharField()
# publish_detail = serializers.CharField()
publish_detail = serializers.DictField()
author_list = serializers.ListField()
多表关联反序列化保存
新增图书接口
新增图书接口
前端传入的数据格式:{name:红楼梦,price:19,publish:1,authors:[1,2]}
视图类
class BookView(APIView):
def post(self, request):
ser = BookSerializer(data=request.data)
if ser.is_valid():
ser.save()
return Response({'code': 100, 'msg': '新增成功'})
else:
return Response({'code': 101, 'msg': ser.errors})
序列化类
class BookSerializer(serializers.Serializer):
# name和price 既用来序列化,又用来反序列化 即写又读 ,不用加read_only,write_only
name = serializers.CharField(max_length=8)
price = serializers.CharField()
# 只用来做序列化 只读 read_only
publish_detail = serializers.DictField(read_only=True)
author_list = serializers.ListField(read_only=True)
# 只用来做反序列化 只写 write_only
publish = serializers.CharField(write_only=True)
authors = serializers.ListField(write_only=True)
# 新增要重写create方法
def create(self, validated_data):
# validated_data 校验过后的数据,{name:红楼梦,price:19,publish:1,authors:[1,2]}
# 新增一本图书
book = Book.objects.create(name=validated_data.get('name'), price=validated_data.get('price'),
publish_id=validated_data.get('publish'))
# 作者也要关联上
# book.authors add remove set clear....
book.authors.add(*validated_data.get('authors'))
# book.authors.add(1,2)
return book
修改图书接口
新增图书接口
前端传入的数据格式:{name:红楼梦,price:19,publish:1,authors:[1,2]}
视图类
class BookDetailView(APIView):
def put(self, request, pk):
book = Book.objects.filter(pk=pk).first()
ser = BookSerializer(data=request.data, instance=book)
if ser.is_valid():
ser.save()
return Response({'code': 100, 'msg': '修改成功'})
else:
return Response({'code': 101, 'msg': ser.errors})
序列化类
# 反序列化的多表关联的保存
class BookSerializer(serializers.Serializer):
# name和price 既用来序列化,又用来反序列化 即写又读 ,不用加read_only,write_only
name = serializers.CharField(max_length=8)
price = serializers.CharField()
# 只用来做反序列化 只写 write_only
publish = serializers.CharField(write_only=True)
authors = serializers.ListField(write_only=True)
# 修改要重写update
def update(self, instance, validated_data):
# validated_data 校验过后的数据,{name:红楼梦,price:19,publish:1,authors:[1,2]}
instance.name = validated_data.get('name')
instance.price = validated_data.get('price')
instance.publish_id = validated_data.get('publish')
# 先清空,再add
authors = validated_data.get('authors')
instance.authors.clear()
instance.authors.add(*authors)
instance.save()
return instance
反序列化字段校验其他
# 4层
-1 字段自己的:举例:name = serializers.CharField(max_length=8, error_messages={'max_length': '太长了'})
-2 validators=[方法,] 忽略掉
-3 局部钩子
-4 全局钩子
ModelSerializer使用
# ModelSerializer 继承自Serializer,帮咱们完成了很多操作
-跟表模型强关联
-大部分请求,不用写create和update了
# 如何使用
### ModelSerializer的使用
class BookSerializer(serializers.ModelSerializer):
# 跟表有关联
class Meta:
model = Book # 跟book表建立了关系 序列化类和表模型类
# fields = '__all__' # 序列化所有Book中的字段 id name price publish authors
fields = ['name', 'price', 'publish_detail', 'author_list', 'publish', 'authors'] # 序列化所有Book中的name和price字段字段
# 定制name反序列化时,最长不能超过8 给字段类加属性---方式一
extra_kwargs = {'name': {'max_length': 8},
'publish_detail': {'read_only': True},
'author_list': {'read_only': True},
'publish': {'write_only': True},
'authors': {'write_only': True},
}
# 如果Meta写了__all__ ,就相当于,复制了表模型中的所有字段,放在了这里,做了个映射
# name = serializers.CharField(max_length=32)
# price = serializers.CharField(max_length=32)
# 定制name反序列化时,最长不能超过8 给字段类加属性---方式二,重写name字段
# name = serializers.CharField(max_length=8)
# 同理,所有的read_only和wirte_only都可以通过重写或使用extra_kwargs传入
# 终极,把这个序列化类写成跟之前一模一样项目
# publish_detail = serializers.SerializerMethodField(read_only=True)
# def get_publish_detail(self, obj):
# return {'name': obj.publish.name, 'addr': obj.publish.addr}
# author_list = serializers.SerializerMethodField(read_only=True)
# def get_author_list(self, obj):
# l = []
# for author in obj.authors.all():
# l.append({'name': author.name, 'phone': author.phone})
# return l
# 局部钩子和全局钩子跟之前完全一样
def validate_name(self, name):
if name.startswith('sb'):
raise ValidationError('不能sb')
else:
return name