转载请说明出处:信安科研人
please subscribe my official wechat :信安科研人
获取更多安全资讯
原文链接:
代码开源地址:
一 简介
1.1 摘要
研究背景:现有先进的二进制程序分析方法受到扩展性和准确性之间的内在权衡的限制。
静态分析:高扩展性,高覆盖率,更多的假阳
动态分析:低扩展性,低覆盖率,更少的假阳
研究目标:许多研究都集中在漏洞发现上,但没有一个提供自动化的、可伸缩的和通用的解决方案,而这正是本研究的目标。
灵感与主要思想:寻找并定义一些类别的漏洞属性,这个属性能够在静态分析和动态分析中都能起到作用。(本质就是基于漏洞模式的漏洞挖掘)
研究所做的贡献:
- 定义了一些种类漏洞的属性,这些属性适合静态和动态(尤其是动态符号执行)结合分析,保证精确率的同时保证扩展性。
- arbiter是一个结合静态分析和动态分析(DSE)的漏洞识别框架,不需要手动搭建系统也不需要知悉源代码(从源代码里看出用的angr,导入二进制程序即可,也保证了多架构需求,算是提高扩展性的方式),同时,定义新的漏洞类型模板比较容易(我认为这可能也算是一种提高扩展性的方式)
- 测试数据开源
1.2 知识背景
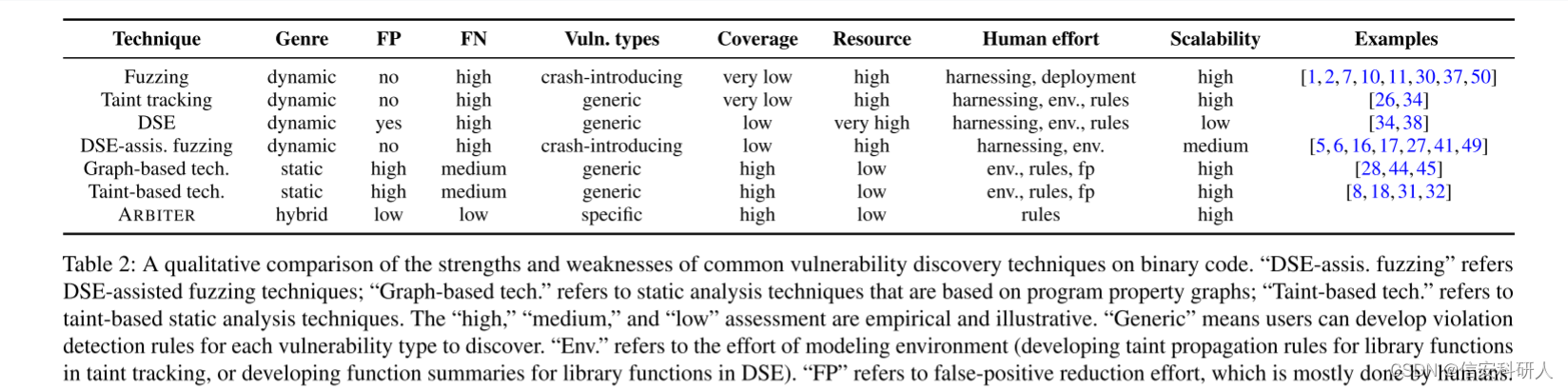
二进制程序静态分析和动态分析技术的比较
![]()
表2 二进制代码中常见漏洞发现技术的定性比较
动态分析技术和静态分析技术注重点不同:动态分析如fuzzing,牺牲覆盖率,依赖人工的环境部署;静态分析高代码覆盖率,但是有较高的假阳性。
1.3 以漏洞为目标的静态分析
通过仔细选择具有在静态和动态分析中可以利用的属性的漏洞,定义漏洞检测方法,将这两个范式结合起来,在保持可扩展性的同时实现高精度。
为此,作者定义了一组漏洞的“属性”,它很好地支持静态分析,同时也提供了集成动态技术以提高精度的机会。
每种漏洞定了三个属性:
1.属性一:是个数据流敏感的漏洞
什么是数据流敏感的漏洞?“数据流敏感”来自经典的程序分析概念,属于流敏感(flow-sensitive)的一种。
流敏感指的是考虑程序语句执行的顺序,例如在数据流分析中的指针别名(Pointer Alias)分析中,一个非流敏感指针别名分析可能得出“变量x和y可能会指向同一位置”,而流敏感指针别名分析得出的结论类似于“在执行第20条指令后,变量x和y可能会指向同一位置” 。
这里有一个
可以通过推理source和漏洞的sinks之间的数据流来发现数据流敏感的漏洞。数据流敏感漏洞的范围严格大于污点类(taint-style)漏洞,后者仅包括因未对受污染的用户输入进行清理而导致漏洞。
这些可以通过静态技术实现,具有典型的精度限制,但也允许对数据流进行额外的动态验证以提高精度。
2.属性二:漏洞含有易于识别的source和sink
漏洞的source代表数据流的起始,sink代表污点追踪的结束。
如果要识别一个漏洞类型的sources和sinks需要了解整个二进制文件的别名信息。
别名是指
也就是说这个代价非常大且低扩展性。示例:
例如,如果source被定义为“从文件 /tmp/secret 读取的任何数据”,识别所有输入source将需要正确分析打开文件的每个函数和系统调用的参数,以及文件指针、文件描述符的传播, 以及相关的数据结构。
相反,有些source或sink可以通过检查计算成本低且可扩展的分析生成的组件(例如 CFG)来识别。如sink的一个示例是“库函数 malloc() 的所有调用点”。
使用这种样式的source和sink,将程序从source切分到sink是一种成熟的静态技术。这种切片虽然是静态分析技术,但是同样可以用到动态技术中,比如DSE。
3.属性三:控制流确定的别名
什么叫“控制流确定”?
作者发现,很多漏洞包含的数据流根本不涉及指针取消引用,或者当取消引用时,指针总是可以解析为一个由控制流确定的对象(例如,通过堆栈指针访问的局部变量)。
属性总结
三个属性总结后的表格如下:
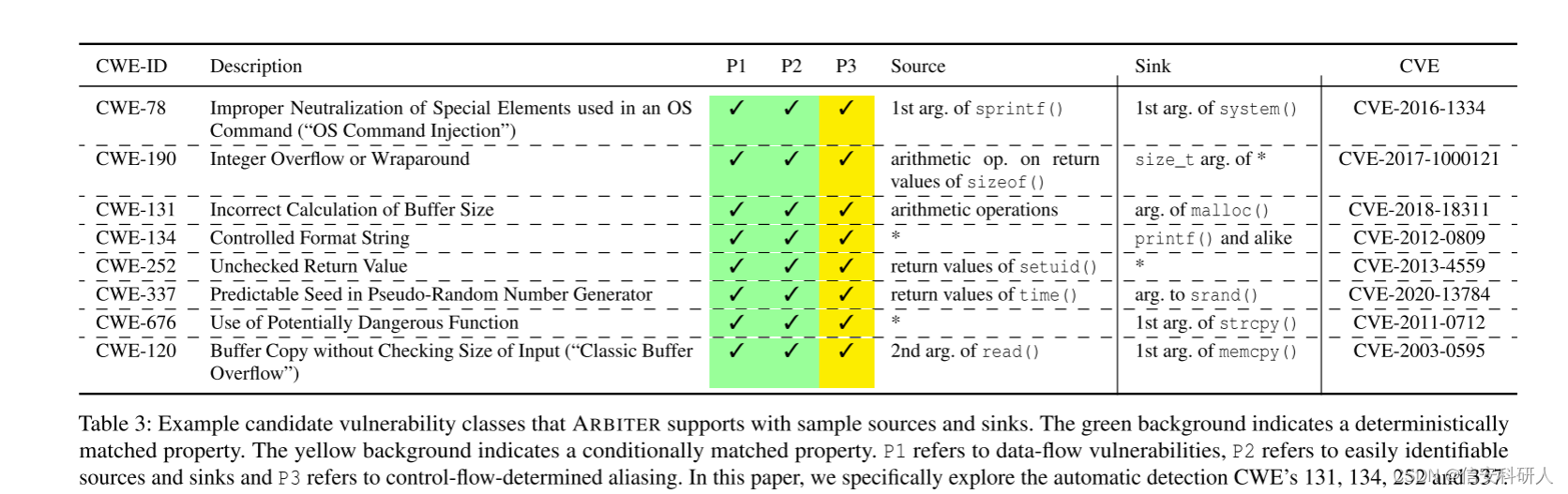
![]()
其中绿色背景表示确定性匹配的属性,黄色背景表示需要一定条件匹配的属性。 P1是指数据流漏洞, P2是指易于识别的sources和sinks, P3是指控制流确定的别名。
二 Arbiter介绍
Arbiter的工作目前支持的漏洞过检测类别见上一个表。
2.1 各类漏洞(作者所定义)的属性(模式)
2.1.1 CWE-131 Allowcation Site Overflows 分配点溢出
分配点(如malloc)的整数溢出漏洞,此类漏洞可能导致程序分配的内存块小于(注意不是大于,因为这是整数溢出)它们应该保存的数据量。当数据被复制到这个内存中时,由此产生的越界内存访问可能会被攻击者利用来获得代码执行。
漏洞发生
此类漏洞一般发生在一些分配内存的包装(wrapper)函数,例如libc中的malloc、alloc等,这些函数一般都需要一个表示要分配的字节数的参数,参数的过大可能会导致整数溢出。
静态的sources和sinks
sinks:分配内存的函数如malloc、calloc、realloc
sources:这些分配函数的参数
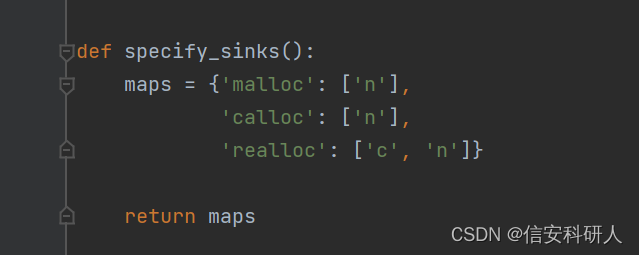
![]()
静态数据流
静态恢复从源到汇的所有流,然后象征性地解释它们。
动态符号约束
令 uint : e → uint 表示表达式的值为无符号整数值。给定一个作为参数传递给内存分配函数 f 的算术表达式 e 及其各个项 {e1, · · · ,en}。
如果存在漏洞,当且仅当 ∃ei ∈ {e1, · · · ,en} | uint(ei) > uint(e)
def apply_constraint(state, expr, init_val, **kwargs):
for x in init_val:
if x.length > expr.length:
continue
if x.length < expr.length:
x = x.zero_extend(expr.length-x.length)
s1 = state.copy()
s1.solver.add(expr > x)
# Check whether we can actually increment the value
if s1.satisfiable():
# Now if expr can be GT and LT x, it means there's an integer overflow/underflow
state.solver.add(expr < x)
else:
# Unsat the whole thing
state.solver.add(expr > x)
return![]()
2.1.2
这类缺陷的具体实例可看这个
简单的说就是软件不检查方法或函数的返回值,这些返回值可能造成危害如信息泄露等。
静态sources和sinks
sources:access, chdir, chown,chroot, mmap, prctl, setgid, setsid, setpgid, setreuid,
setregid, setresuid, setresgid, setrlimit, stat
def specify_sources():
_, checkpoints = parse_syscalls(SYSCALL_TABLE, return_filter=-1)
return checkpoints![]()
sinks:使用函数的返回块(在正在分析的二进制文件中)调用 系统调用的 相应 libc 的API。
def specify_sinks():
maps, _ = parse_syscalls(SYSCALL_TABLE, return_filter=-1)
return maps![]()
静态数据流
为了捕获返回值被丢弃的情况(此漏洞的常见原因),数据流规范必须从源捕获 API 返回值的所有流,包括那些调用者的返回值不依赖于系统的流调用返回值。
动态符号约束
如果在函数结束时,DSE 识别 API 调用的返回值可以是成功又可以是失败的状态(即下面代码的条件判断),则没有检查以约束该返回值,并且存在未检查的返回值漏洞。
def apply_constraint(state, expr, init_val, **kwargs):
s1 = state.copy()
# target function returned -1 (indicating error)
s1.solver.add(init_val[0] == 0xffffffffffffffff)
if s1.satisfiable():
# target function allows both (indicating absence of checks)
state.solver.add(init_val[0] == 0)
else:
# Unsat the whole thing
state.solver.add(init_val[0] == 0xffffffffffffffff)
return![]()
2.1.3 CWE-134 未受控制的格式化字符串
漏洞起因
格式化字符串参数不是个常量。
静态sources和sinks
sinks:
def specify_sinks():
maps = {'printf': ['n'],
'fprintf': ['c', 'n'],
'dprintf': ['c', 'n'],
'sprintf': ['c', 'n'],
'vasprintf': ['c', 'n'],
'snprintf': ['c', 'c', 'n'],
'fprintf_chk': ['c', 'c', 'n'],
'dprintf_chk': ['c', 'c', 'n'],
'sprintf_chk': ['c', 'c', 'c', 'n'],
'vasprintf_chk': ['c', 'c', 'n'],
'asprintf_chk': ['c', 'c', 'n'],
'snprintf_chk': ['c', 'c', 'c', 'c', 'n'],
}
return maps![]()
sources:
sources是调用已识别sinks的wrapper函数(就是包含这些printf函数的自定义函数等)的参数。
def specify_sources():
return {}![]()
静态数据流
这个漏洞的数据流规范很简单:静态地恢复从sources到sinks的所有流,然后对它们进行符号推理。
动态符号约束
此漏洞的动态符号约束检查sinks中使用的格式字符串是否为常量。如果此格式字符串不是常量,则将其标记为潜在错误。
def apply_constraint(state, expr, init_val, **kwargs):
addr = state.solver.eval(expr, cast_to=int)
if state.project.loader.find_section_containing(addr) is not None:
# Force an unsat error
state.solver.add(expr==0)
return![]()
2.1.4 伪随机数生成器的种子可以推测
漏洞起因
很多开发案例中使用当前时间(以秒为单位)来作为伪随机数生成器的种子。这使得种子可预测,并导致漏洞。
sources和sinks
论文原文这里作者直接摆烂没写了,我就直接附上源代码,可以看到作者这里的模式主要聚焦在time函数,sinks就是srand,也就是我们常用的srand(time)。
def specify_sinks():
maps = {'srand': ['n']}
return maps
def specify_sources():
checkpoints = {'time': 0}
return checkpoints![]()
DSE约束
无。因为DSE 只需要确认数据流分析的结果,并在sources和sinks之间建立数据流。
2.2 Arbiter分析框架
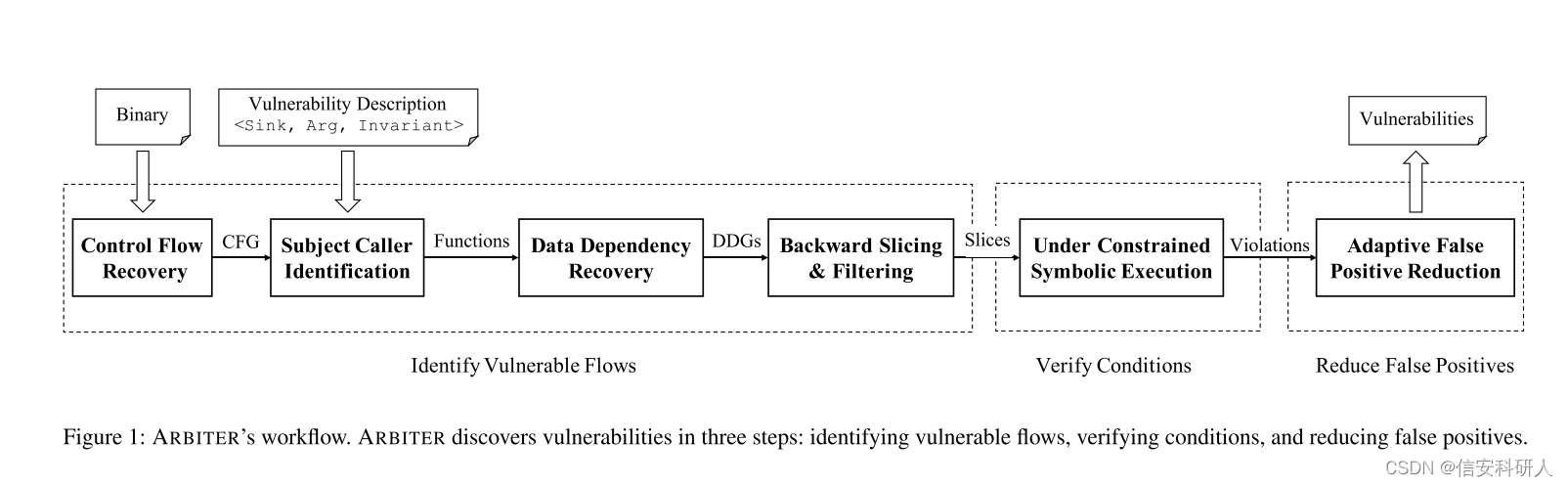
![]()
输入:需要分析的二进制代码和漏洞描述VD(就是2.1节介绍的pattern)
识别威胁流:使用各类技术的组合识别可能满足二进制中的漏洞描述的流。首先在恢复的控制流程图CFG上搜索VD对象,然后查询计算数据依赖关系图DDG,识别与提供的 VD 匹配的数据流。 Arbiter计算表示这些流的路径,并将这些路径传送到下一步。
校验漏洞条件:使用欠约束符号执行UCSE来执行上一步提供的路径,并恢复sources和sinks之间的符号数据关系。如果此关系满足提供的 VD 中描述的约束,则路径将传送到下一步。
减少基于上下文的误报:ARBITER 限制其静态分析的上下文敏感性以实现可扩展性。因此,为候选漏洞检测到的数据流,可能缺少约束条件,这些约束条件具有更高的上下文敏感性,从而导致误报检测。为了缓解这个问题,ARBITER 从检测到的具有更高上下文敏感性的sinks中计算出一个切片,并执行它以识别缺失的约束。通过在此步骤中提高上下文敏感性级别,ARBITER 以可扩展性换取精度。如果 ARBITER 无法识别任何使现有漏洞候选无效的约束,则该候选将作为警报报告给分析师。
2.2.1 识别威胁流
以 CFG 和 VD 作为输入,构建并查询关于 VD 中指定的漏洞源/汇的数据依赖图 (DDG)。由此产生的候选易受攻击的数据流将由 ARBITER 的动态分析组件进行验证。本节重点介绍静态数据流跟踪技术、DDG 的创建方式以及易受攻击的数据流候选者的识别方式。
(1)精确的静态数据流跟踪
基于图形和基于污点分析的静态分析被用于发现源代码和二进制代码中的污点式漏洞。ARBITER 采用了一种名为SymDFT的新静态Data-flow Tracing技术,给定任何起点(通常是函数的起始地址),SymDFT以上下文敏感和路径敏感的方式静态模拟基本块,模型寄存器,内存(作为覆盖全局区域、堆栈和堆叠的平板内存模型),syscalls和访问文件描述符(捕获文件和网络套接字)。 通过使用符号域,在分析过程中跟踪未知变量和符号表达式来实现建模数据的高精度。
新在以下几种策略:
遍历策略。在函数级别,SymDFT 以拓扑顺序遍历函数内部的基本块,这确保了在访问所有前任块之后始终访问一个块。一旦遇到对被调用方的调用,SymDFT 将分析被调用方函数并使用返回的抽象状态在返回站点继续进行分析。
分支策略。 SymDFT 结合了支持强制执行和一揽子执行的想法:在每个分支点,分叉抽象状态并遵循所有分支,而不管分支可行性如何:SymDFT 在仿真过程中收集符号路径谓词(即符号约束),但是不评估这些约束的可满足性。虽然会牺牲精度,但会在第 6 节中描述的验证步骤中恢复精度。
状态合并策略。同一二进制地址的抽象状态被立即合并,每个状态被分配一个merging label,具体和符号表达式被合并成,以合并标签为条件的if-then-else表达式的形式。
终止。为确保分析终止,SymDFT 采用策略如下:(1) 当调用深度超过 2 个函数时,SymDFT 伪造一个抽象返回值而不是分析被调用者;(2) 每个循环最多访问 3 次。这种终止策略以降低可伸缩性的可靠性和精度为代价。
(2)构建DDG并提取流
ARBITER 首先识别 CFG 上的sources或sinks,并识别相关功能。
然后 ARBITER 为包含每个sources或sinks的函数构建一个 DDG。注意,这些 DDG 不包括任何调用者。
当 VD 中只描述了 sinks 时,ARBITER 会为找到 sinks 的每个函数(和被调用者)构建一个 DDG,而不是构建一个涵盖所有潜在输入源的完整程序 DDG。这显着提高了 DDG 生成的可扩展性和易受攻击的流识别,但以精度为代价,ARBITER 在验证步骤中纠正了这一点。
2.2.2 校验漏洞流
在静态分析期间收集的候选漏洞数据流不一定是vulnerable,因为 (1) 它们不可满足或 (2) 路径谓词使漏洞无法触发,即使流有效。 ARBITER 使用欠约束符号执行来验证每个候选数据流,并消除那些不满足或不vulnerable的数据流。
使用:
1)欠约束符号执行
为什么要欠约束符号执行?因为CFG不完整以及一些动态覆盖问题的存在,Arbiter一般难以推导出从目标二进制文件的入口点开始并到达sinks的可执行路径。在基于sources的分析中,欠约束符号执行 (UCSE) 是对不完整的程序状态执行 DSE 的可行方法 。
欠约束符号执行的作用?UCSE 允许在不初始化数据结构或建模环境的情况下符号执行任意函数。
欠约束符号执行的技术细节?所有在不完整状态下不可用的值(例如,缺少参数和来自被调用方的未知返回值)都被视为欠约束变量。当欠约束变量用作指针时,UCSE 会将变量初始化为指针,指向新分配的内存区域,其大小与指针类型指定的大小相同。如果变量不用作指针,则约束不足的变量将受到对其应用符号约束的更多约束。
2)收集数据流约束
对于每个候选漏洞数据流,ARBITER 在遍历每个sinks的 CFG 生成的程序切片上运行 UCSE。在sink点,ARBITER 提取表示source和sink之间数据依赖关系的符号表达式,并收集路径谓词(约束)。如果满足VD的约束,ARBITER 报告潜在的 VD 违规。
2.2.3 自适应的减少误报
尽管在 UCSE 步骤中对候选vulnerable的数据流进行了可满足性过滤,但缺乏上下文仍然会留下大量误报。因为 ARBITER 在函数内部工作,所以它没有可能影响函数的控制流和数据流的上下文相关信息。一旦在较小的上下文中检测到漏洞,就会通过增加分析上下文来过滤掉误报。
ARBITER 递归地识别当前函数的所有调用点,并继续在调用帧的上下文中进行分析。 ARBITER 递归地继续逐个调用者扩展上下文调用者,直到达到预定义的递归限制。
分析人员可以根据报告的数量和时间限制自适应地选择递归限制,因为每个额外的上下文都可能导致分析时间呈指数增长。
三 项目源代码使用与部分分析
安装方法:
git clone https://github.com/jkrshnmenon/arbiter
python setup.py build && python setup.py install![]()
使用教程:
$ run_arbiter.py -h
usage: run_arbiter.py [-h] -f VD -t TARGET [-r LEVEL] [-l LOG_DIR] [-j JSON_DIR] [-s]
Use Arbiter to run a template against a specific binary
optional arguments:
-h, --help show this help message and exit
-f VD The VD template to use
-t TARGET The target binary to analyze
-r LEVEL Number of levels for Adaptive False Positive Reduction
-l LOG_DIR Enable logging to LOG_DIR
-j JSON_DIR Enable verbose statistics dumps to JSON_DIR
-s Enable strict mode (stricter static data-flow based filtering)
![]()
项目中给的示例命令是:
mkdir <log_dir>
mkdir <json_dir>
cd <path/to/arbiter>/vuln_templates/
./run_arbiter.py -f ./CWE131.py -t /bin/ls -l <log_dir> -j <json_dir>![]()
-f 指定漏洞模板CWE131,对应子类漏洞整数溢出,-t 指定测试的文件,-l 指定日志目录,-j 指定结果目录
程序逻辑
漏洞模式(污点定义与DSE约束的源代码)上一节已经随理论定义给出来了这里不再分析。程序测试起始文件为run_arbiter.py,main函数处理分析流程:
def main(template, target):
project = angr.Project(target, auto_load_libs=False)
sink_map = template.specify_sinks()
sa = SA_Recon(project, sinks=sink_map.keys(), maps=sink_map, json_dir=JSON_DIR)
if IDENTIFIER is None:
sa.analyze(ignore_funcs=BLACKLIST)
else:
sa.analyze_one(IDENTIFIER)
sources = template.specify_sources()
sb = SA_Adv(sa, checkpoint=sources, require_dd=STRICT_MODE, call_depth=CALL_DEPTH, json_dir=JSON_DIR)
sb.analyze_all()
constrain = template.apply_constraint
se = SymExec(sb, constrain=constrain, require_dd=STRICT_MODE, json_dir=JSON_DIR)
se.run_all()
template.save_results(se.postprocessing(pred_level=CALLER_LEVEL))![]()
输入参数:template 漏洞模板;target 测试文件
处理流程:加载文件project →定义指定漏洞模板对应的sink_map中的sink和source → sa = SA_Recon(project) → sb = SA_Adv(sa) → se = SymExec(sb) → se.run_all()
使用体验:误报率还是挺高的
具体的这三个函数将会在下一篇进行分析